 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Party Turn-Taking Models from Dialogue Logs
Paper and Code
Jul 03, 2019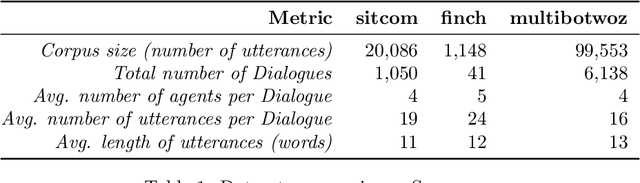

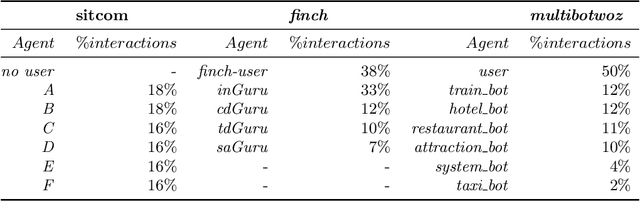
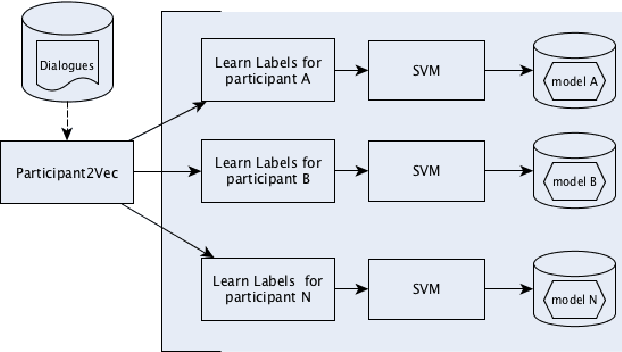
This paper investigates the application of machine learning (ML) techniques to enable intelligent systems to learn multi-party turn-taking models from dialogue logs. The specific ML task consists of determining who speaks next, after each utterance of a dialogue, given who has spoken and what was said in the previous utterances. With this goal, this paper presents comparisons of the accuracy of different ML techniques such as Maximum Likelihood Estimation (MLE), Support Vector Machines (SVM), and Convolutional Neural Networks (CNN) architectures, with and without utterance data. We present three corpora: the first with dialogues from an American TV situated comedy (chit-chat), the second with logs from a financial advice multi-bot system and the third with a corpus created from the Multi-Domain Wizard-of-Oz dataset (both are topic-oriented). The results show: (i) the size of the corpus has a very positive impact on the accuracy for the content-based deep learning approaches and those models perform best in the larger datasets; and (ii) if the dialogue dataset is small and topic-oriented (but with few topics), it is sufficient to use an agent-only MLE or SVM models, although slightly higher accuracies can be achieved with the use of the content of the utterances with a CNN model.