 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransplantation of Conversational Speaking Style with Interjections in Sequence-to-Sequence Speech Synthesis
Jul 25, 2022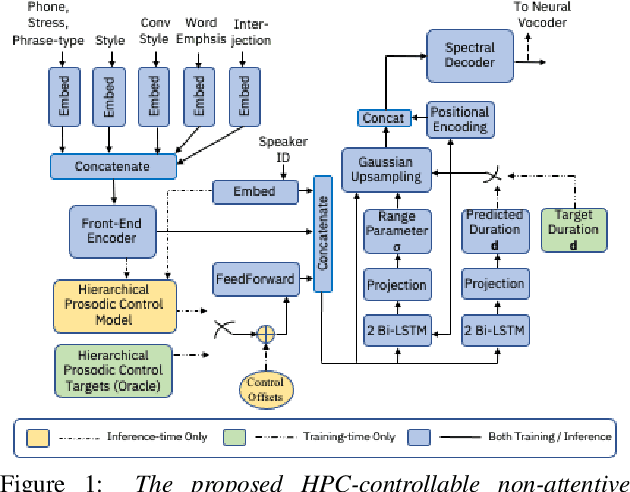

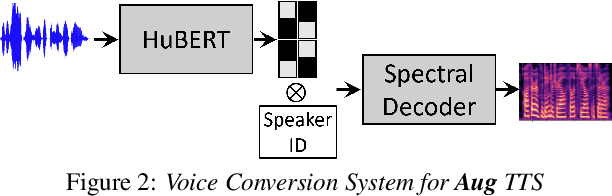

Sequence-to-Sequence Text-to-Speech architectures that directly generate low level acoustic features from phonetic sequences are known to produce natural and expressive speech when provided with adequate amounts of training data. Such systems can learn and transfer desired speaking styles from one seen speaker to another (in multi-style multi-speaker settings), which is highly desirable for creating scalable and customizable Human-Computer Interaction systems. In this work we explore one-to-many style transfer from a dedicated single-speaker conversational corpus with style nuances and interjections. We elaborate on the corpus design and explore the feasibility of such style transfer when assisted with Voice-Conversion-based data augmentation. In a set of subjective listening experiments, this approach resulted in high-fidelity style transfer with no quality degradation. However, a certain voice persona shift was observed, requiring further improvements in voice conversion.