 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Local Overfitting and Forgetting in Deep Neural Networks
Dec 17, 2024



The infrequent occurrence of overfitting in deep neural networks is perplexing: contrary to theoretical expectations, increasing model size often enhances performance in practice. But what if overfitting does occur, though restricted to specific sub-regions of the data space? In this work, we propose a novel score that captures the forgetting rate of deep models on validation data. We posit that this score quantifies local overfitting: a decline in performance confined to certain regions of the data space. We then show empirically that local overfitting occurs regardless of the presence of traditional overfitting. Using the framework of deep over-parametrized linear models, we offer a certain theoretical characterization of forgotten knowledge, and show that it correlates with knowledge forgotten by real deep models. Finally, we devise a new ensemble method that aims to recover forgotten knowledge, relying solely on the training history of a single network. When combined with self-distillation, this method enhances the performance of any trained model without adding inference costs. Extensive empirical evaluations demonstrate the efficacy of our method across multiple datasets, contemporary neural network architectures, and training protocols.
Relearning Forgotten Knowledge: on Forgetting, Overfit and Training-Free Ensembles of DNNs
Oct 17, 2023The infrequent occurrence of overfit in deep neural networks is perplexing. On the one hand, theory predicts that as models get larger they should eventually become too specialized for a specific training set, with ensuing decrease in generalization. In contrast, empirical results in image classification indicate that increasing the training time of deep models or using bigger models almost never hurts generalization. Is it because the way we measure overfit is too limited? Here, we introduce a novel score for quantifying overfit, which monitors the forgetting rate of deep models on validation data. Presumably, this score indicates that even while generalization improves overall, there are certain regions of the data space where it deteriorates. When thus measured, we show that overfit can occur with and without a decrease in validation accuracy, and may be more common than previously appreciated. This observation may help to clarify the aforementioned confusing picture. We use our observations to construct a new ensemble method, based solely on the training history of a single network, which provides significant improvement in performance without any additional cost in training time. An extensive empirical evaluation with modern deep models shows our method's utility on multiple datasets, neural networks architectures and training schemes, both when training from scratch and when using pre-trained networks in transfer learning. Notably, our method outperforms comparable methods while being easier to implement and use, and further improves the performance of competitive networks on Imagenet by 1\%.
United We Stand: Using Epoch-wise Agreement of Ensembles to Combat Overfit
Oct 17, 2023



Deep neural networks have become the method of choice for solving many image classification tasks, largely because they can fit very complex functions defined over raw images. The downside of such powerful learners is the danger of overfitting the training set, leading to poor generalization, which is usually avoided by regularization and "early stopping" of the training. In this paper, we propose a new deep network ensemble classifier that is very effective against overfit. We begin with the theoretical analysis of a regression model, whose predictions - that the variance among classifiers increases when overfit occurs - is demonstrated empirically in deep networks in common use. Guided by these results, we construct a new ensemble-based prediction method designed to combat overfit, where the prediction is determined by the most consensual prediction throughout the training. On multiple image and text classification datasets, we show that when regular ensembles suffer from overfit, our method eliminates the harmful reduction in generalization due to overfit, and often even surpasses the performance obtained by early stopping. Our method is easy to implement, and can be integrated with any training scheme and architecture, without additional prior knowledge beyond the training set. Accordingly, it is a practical and useful tool to overcome overfit.
The Dynamic of Consensus in Deep Networks and the Identification of Noisy Labels
Oct 02, 2022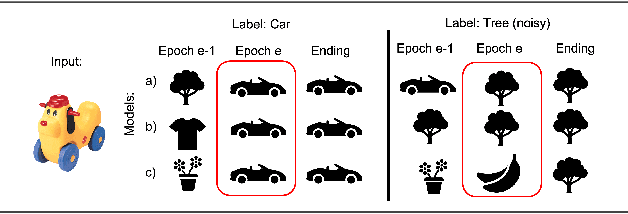


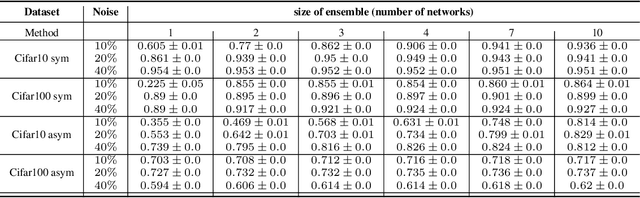
Deep neural networks have incredible capacity and expressibility, and can seemingly memorize any training set. This introduces a problem when training in the presence of noisy labels, as the noisy examples cannot be distinguished from clean examples by the end of training. Recent research has dealt with this challenge by utilizing the fact that deep networks seem to memorize clean examples much earlier than noisy examples. Here we report a new empirical result: for each example, when looking at the time it has been memorized by each model in an ensemble of networks, the diversity seen in noisy examples is much larger than the clean examples. We use this observation to develop a new method for noisy labels filtration. The method is based on a statistics of the data, which captures the differences in ensemble learning dynamics between clean and noisy data. We test our method on three tasks: (i) noise amount estimation; (ii) noise filtration; (iii) supervised classification. We show that our method improves over existing baselines in all three tasks using a variety of datasets, noise models, and noise levels. Aside from its improved performance, our method has two other advantages. (i) Simplicity, which implies that no additional hyperparameters are introduced. (ii) Our method is modular: it does not work in an end-to-end fashion, and can therefore be used to clean a dataset for any other future usage.