 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarGait: Cross-Attention based Re-ranking for Gait recognition
Mar 05, 2025Gait recognition is a computer vision task that identifies individuals based on their walking patterns. Gait recognition performance is commonly evaluated by ranking a gallery of candidates and measuring the accuracy at the top Rank-$K$. Existing models are typically single-staged, i.e. searching for the probe's nearest neighbors in a gallery using a single global feature representation. Although these models typically excel at retrieving the correct identity within the top-$K$ predictions, they struggle when hard negatives appear in the top short-list, leading to relatively low performance at the highest ranks (e.g., Rank-1). In this paper, we introduce CarGait, a Cross-Attention Re-ranking method for gait recognition, that involves re-ordering the top-$K$ list leveraging the fine-grained correlations between pairs of gait sequences through cross-attention between gait strips. This re-ranking scheme can be adapted to existing single-stage models to enhance their final results. We demonstrate the capabilities of CarGait by extensive experiments on three common gait datasets, Gait3D, GREW, and OU-MVLP, and seven different gait models, showing consistent improvements in Rank-1,5 accuracy, superior results over existing re-ranking methods, and strong baselines.
EffoVPR: Effective Foundation Model Utilization for Visual Place Recognition
May 28, 2024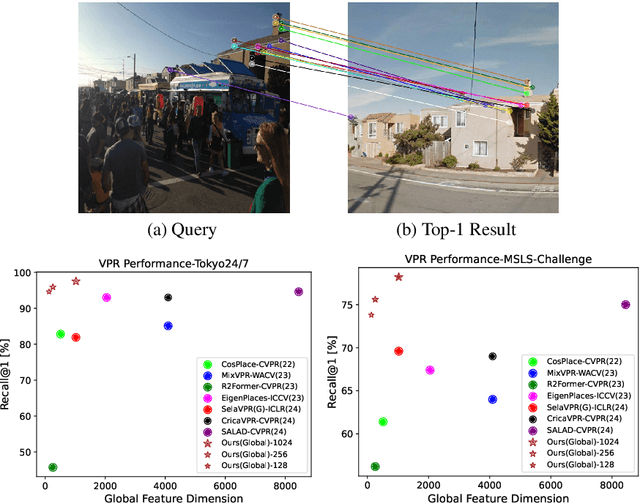
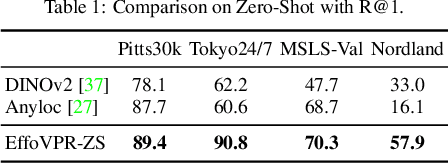
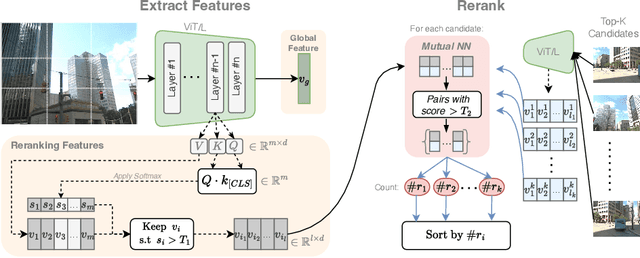
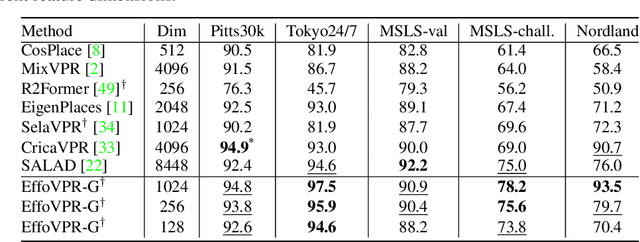
The task of Visual Place Recognition (VPR) is to predict the location of a query image from a database of geo-tagged images. Recent studies in VPR have highlighted the significant advantage of employing pre-trained foundation models like DINOv2 for the VPR task. However, these models are often deemed inadequate for VPR without further fine-tuning on task-specific data. In this paper, we propose a simple yet powerful approach to better exploit the potential of a foundation model for VPR. We first demonstrate that features extracted from self-attention layers can serve as a powerful re-ranker for VPR. Utilizing these features in a zero-shot manner, our method surpasses previous zero-shot methods and achieves competitive results compared to supervised methods across multiple datasets. Subsequently, we demonstrate that a single-stage method leveraging internal ViT layers for pooling can generate global features that achieve state-of-the-art results, even when reduced to a dimensionality as low as 128D. Nevertheless, incorporating our local foundation features for re-ranking, expands this gap. Our approach further demonstrates remarkable robustness and generalization, achieving state-of-the-art results, with a significant gap, in challenging scenarios, involving occlusion, day-night variations, and seasonal changes.
Watch Your Pose: Unsupervised Domain Adaption with Pose based Triplet Selection for Gait Recognition
Jul 13, 2023Gait Recognition is a computer vision task aiming to identify people by their walking patterns. Existing methods show impressive results on individual datasets but lack the ability to generalize to unseen scenarios. Unsupervised Domain Adaptation (UDA) tries to adapt a model, pre-trained in a supervised manner on a source domain, to an unlabelled target domain. UDA for Gait Recognition is still in its infancy and existing works proposed solutions to limited scenarios. In this paper, we reveal a fundamental phenomenon in adaptation of gait recognition models, in which the target domain is biased to pose-based features rather than identity features, causing a significant performance drop in the identification task. We suggest Gait Orientation-based method for Unsupervised Domain Adaptation (GOUDA) to reduce this bias. To this end, we present a novel Triplet Selection algorithm with a curriculum learning framework, aiming to adapt the embedding space by pushing away samples of similar poses and bringing closer samples of different poses. We provide extensive experiments on four widely-used gait datasets, CASIA-B, OU-MVLP, GREW, and Gait3D, and on three backbones, GaitSet, GaitPart, and GaitGL, showing the superiority of our proposed method over prior works.
Image Quality Assessment: Learning to Rank Image Distortion Level
Aug 04, 2022Over the years, various algorithms were developed, attempting to imitate the Human Visual System (HVS), and evaluate the perceptual image quality. However, for certain image distortions, the functionality of the HVS continues to be an enigma, and echoing its behavior remains a challenge (especially for ill-defined distortions). In this paper, we learn to compare the image quality of two registered images, with respect to a chosen distortion. Our method takes advantage of the fact that at times, simulating image distortion and later evaluating its relative image quality, is easier than assessing its absolute value. Thus, given a pair of images, we look for an optimal dimensional reduction function that will map each image to a numerical score, so that the scores will reflect the image quality relation (i.e., a less distorted image will receive a lower score). We look for an optimal dimensional reduction mapping in the form of a Deep Neural Network which minimizes the violation of image quality order. Subsequently, we extend the method to order a set of images by utilizing the predicted level of the chosen distortion. We demonstrate the validity of our method on Latent Chromatic Aberration and Moire distortions, on synthetic and real datasets.