 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarGait: Cross-Attention based Re-ranking for Gait recognition
Mar 05, 2025Gait recognition is a computer vision task that identifies individuals based on their walking patterns. Gait recognition performance is commonly evaluated by ranking a gallery of candidates and measuring the accuracy at the top Rank-$K$. Existing models are typically single-staged, i.e. searching for the probe's nearest neighbors in a gallery using a single global feature representation. Although these models typically excel at retrieving the correct identity within the top-$K$ predictions, they struggle when hard negatives appear in the top short-list, leading to relatively low performance at the highest ranks (e.g., Rank-1). In this paper, we introduce CarGait, a Cross-Attention Re-ranking method for gait recognition, that involves re-ordering the top-$K$ list leveraging the fine-grained correlations between pairs of gait sequences through cross-attention between gait strips. This re-ranking scheme can be adapted to existing single-stage models to enhance their final results. We demonstrate the capabilities of CarGait by extensive experiments on three common gait datasets, Gait3D, GREW, and OU-MVLP, and seven different gait models, showing consistent improvements in Rank-1,5 accuracy, superior results over existing re-ranking methods, and strong baselines.
Watch Your Pose: Unsupervised Domain Adaption with Pose based Triplet Selection for Gait Recognition
Jul 13, 2023Gait Recognition is a computer vision task aiming to identify people by their walking patterns. Existing methods show impressive results on individual datasets but lack the ability to generalize to unseen scenarios. Unsupervised Domain Adaptation (UDA) tries to adapt a model, pre-trained in a supervised manner on a source domain, to an unlabelled target domain. UDA for Gait Recognition is still in its infancy and existing works proposed solutions to limited scenarios. In this paper, we reveal a fundamental phenomenon in adaptation of gait recognition models, in which the target domain is biased to pose-based features rather than identity features, causing a significant performance drop in the identification task. We suggest Gait Orientation-based method for Unsupervised Domain Adaptation (GOUDA) to reduce this bias. To this end, we present a novel Triplet Selection algorithm with a curriculum learning framework, aiming to adapt the embedding space by pushing away samples of similar poses and bringing closer samples of different poses. We provide extensive experiments on four widely-used gait datasets, CASIA-B, OU-MVLP, GREW, and Gait3D, and on three backbones, GaitSet, GaitPart, and GaitGL, showing the superiority of our proposed method over prior works.
MISS GAN: A Multi-IlluStrator Style Generative Adversarial Network for image to illustration translation
Aug 12, 2021
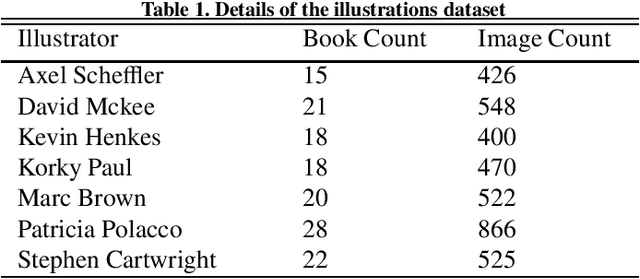
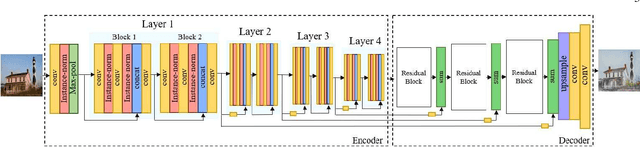

Unsupervised style transfer that supports diverse input styles using only one trained generator is a challenging and interesting task in computer vision. This paper proposes a Multi-IlluStrator Style Generative Adversarial Network (MISS GAN) that is a multi-style framework for unsupervised image-to-illustration translation, which can generate styled yet content preserving images. The illustrations dataset is a challenging one since it is comprised of illustrations of seven different illustrators, hence contains diverse styles. Existing methods require to train several generators (as the number of illustrators) to handle the different illustrators' styles, which limits their practical usage, or require to train an image specific network, which ignores the style information provided in other images of the illustrator. MISS GAN is both input image specific and uses the information of other images using only one trained model.