 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-point Inversion for Text-to-image diffusion models
Paper and Code
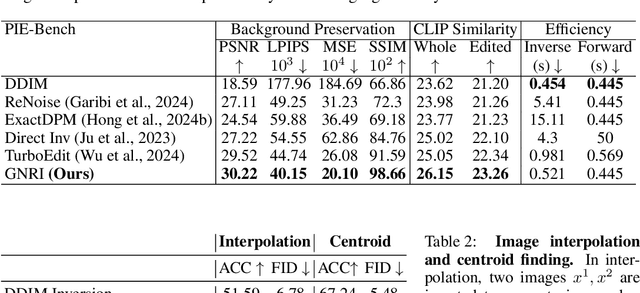
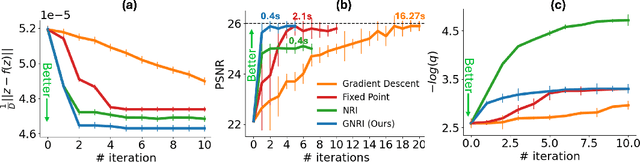
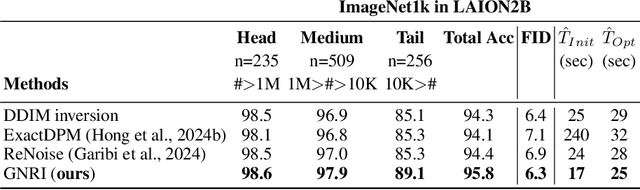
Dec 19, 2023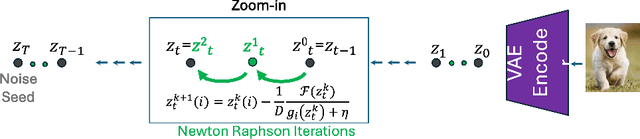
Text-guided diffusion models offer powerful new ways to generate and manipulate images. Several applications of these models, including image editing interpolation, and semantic augmentation, require diffusion inversion. This is the process of finding a noise seed that can be used to generate a given image. Current techniques for inverting a given image can be slow or inaccurate. The technical challenge for inverting the diffusion process arises from an implicit equation over the latent that cannot be solved in closed form. Previous approaches proposed to solve this issue by approximation or various learning schemes. Here, we formulate the problem as a fixed-point equation problem and solve it using fixed-point iterations, a well-studied approach in numerical analysis. We further identify a source of inconsistency that significantly hurts the inversion of real images encoded to the latent space. We show how to correct it by applying a prompt-aware adjustment of the encoding. Our solution, Fixed-point inversion, is much faster than previous techniques like EDICT and Null-text, with similar inversion quality. It can be combined with any pretrained diffusion model and requires no model training, prompt tuning, or additional parameters. In a series of experiments, we find that Fixed-point inversion shows improved results in several downstream tasks: image editing, image interpolation, and generation of rare objects.