 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Attribute: Open-vocabulary Attribute Encoder for Visual Concept Personalization
Dec 11, 2025Visual concept personalization aims to transfer only specific image attributes, such as identity, expression, lighting, and style, into unseen contexts. However, existing methods rely on holistic embeddings from general-purpose image encoders, which entangle multiple visual factors and make it difficult to isolate a single attribute. This often leads to information leakage and incoherent synthesis. To address this limitation, we introduce Omni-Attribute, the first open-vocabulary image attribute encoder designed to learn high-fidelity, attribute-specific representations. Our approach jointly designs the data and model: (i) we curate semantically linked image pairs annotated with positive and negative attributes to explicitly teach the encoder what to preserve or suppress; and (ii) we adopt a dual-objective training paradigm that balances generative fidelity with contrastive disentanglement. The resulting embeddings prove effective for open-vocabulary attribute retrieval, personalization, and compositional generation, achieving state-of-the-art performance across multiple benchmarks.
Stable Flow: Vital Layers for Training-Free Image Editing
Nov 21, 2024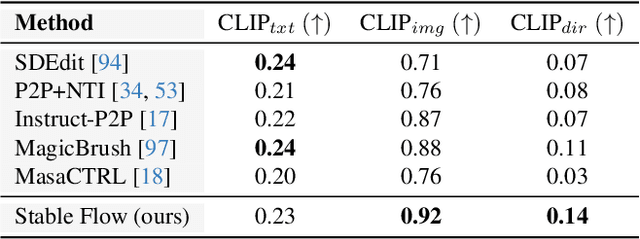

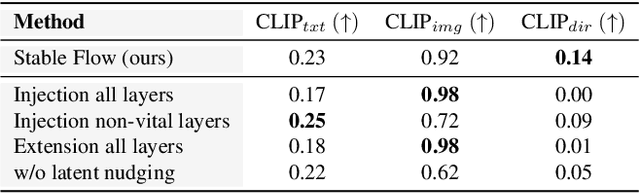
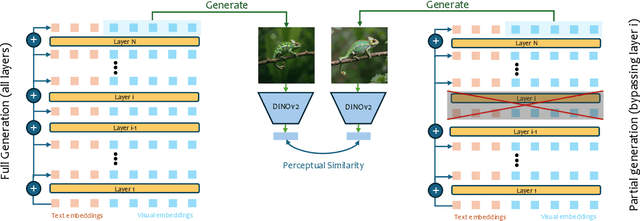
Diffusion models have revolutionized the field of content synthesis and editing. Recent models have replaced the traditional UNet architecture with the Diffusion Transformer (DiT), and employed flow-matching for improved training and sampling. However, they exhibit limited generation diversity. In this work, we leverage this limitation to perform consistent image edits via selective injection of attention features. The main challenge is that, unlike the UNet-based models, DiT lacks a coarse-to-fine synthesis structure, making it unclear in which layers to perform the injection. Therefore, we propose an automatic method to identify "vital layers" within DiT, crucial for image formation, and demonstrate how these layers facilitate a range of controlled stable edits, from non-rigid modifications to object addition, using the same mechanism. Next, to enable real-image editing, we introduce an improved image inversion method for flow models. Finally, we evaluate our approach through qualitative and quantitative comparisons, along with a user study, and demonstrate its effectiveness across multiple applications. The project page is available at https://omriavrahami.com/stable-flow