 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProve Symbolic Regression is NP-hard by Symbol Graph
Apr 22, 2024

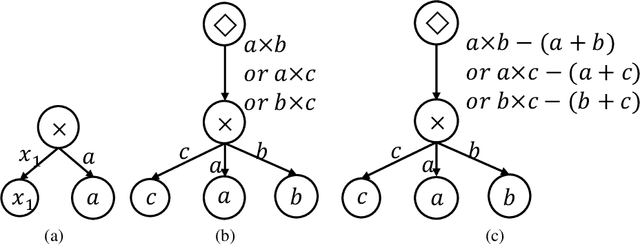
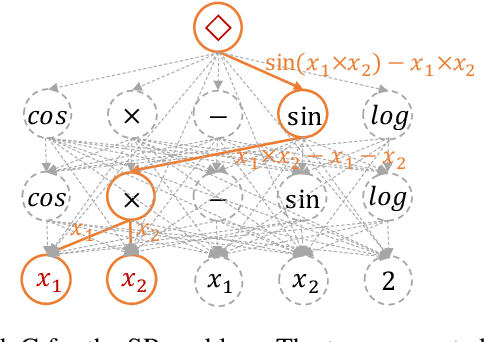
Symbolic regression (SR) is the task of discovering a symbolic expression that fits a given data set from the space of mathematical expressions. Despite the abundance of research surrounding the SR problem, there's a scarcity of works that confirm its NP-hard nature. Therefore, this paper introduces the concept of a symbol graph as a comprehensive representation of the entire mathematical expression space, effectively illustrating the NP-hard characteristics of the SR problem. Leveraging the symbol graph, we establish a connection between the SR problem and the task of identifying an optimally fitted degree-constrained Steiner Arborescence (DCSAP). The complexity of DCSAP, which is proven to be NP-hard, directly implies the NP-hard nature of the SR problem.
Exploring Hidden Semantics in Neural Networks with Symbolic Regression
Apr 22, 2022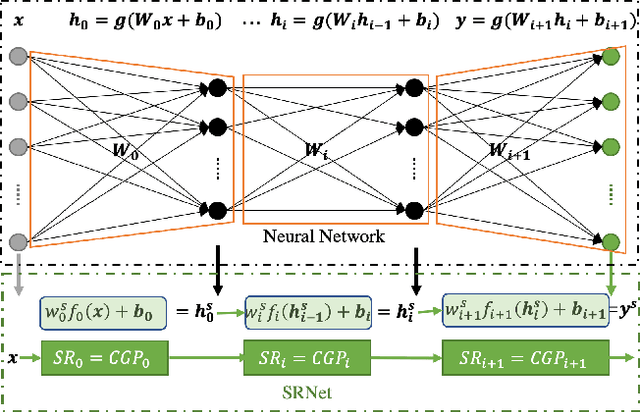

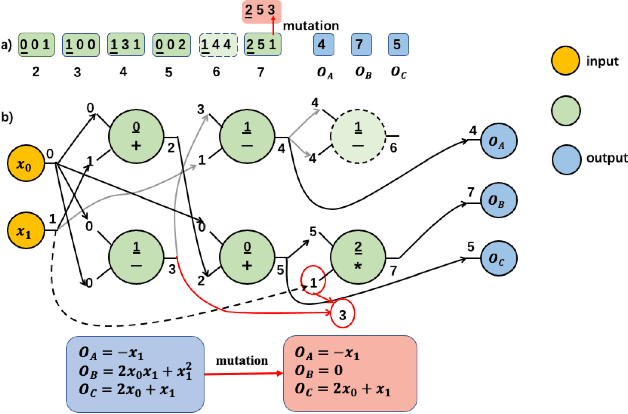
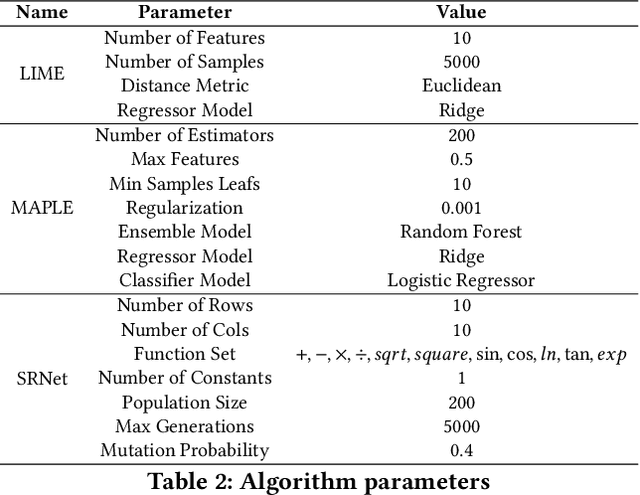
Many recent studies focus on developing mechanisms to explain the black-box behaviors of neural networks (NNs). However, little work has been done to extract the potential hidden semantics (mathematical representation) of a neural network. A succinct and explicit mathematical representation of a NN model could improve the understanding and interpretation of its behaviors. To address this need, we propose a novel symbolic regression method for neural works (called SRNet) to discover the mathematical expressions of a NN. SRNet creates a Cartesian genetic programming (NNCGP) to represent the hidden semantics of a single layer in a NN. It then leverages a multi-chromosome NNCGP to represent hidden semantics of all layers of the NN. The method uses a (1+$\lambda$) evolutionary strategy (called MNNCGP-ES) to extract the final mathematical expressions of all layers in the NN. Experiments on 12 symbolic regression benchmarks and 5 classification benchmarks show that SRNet not only can reveal the complex relationships between each layer of a NN but also can extract the mathematical representation of the whole NN. Compared with LIME and MAPLE, SRNet has higher interpolation accuracy and trends to approximate the real model on the practical dataset.
Zero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021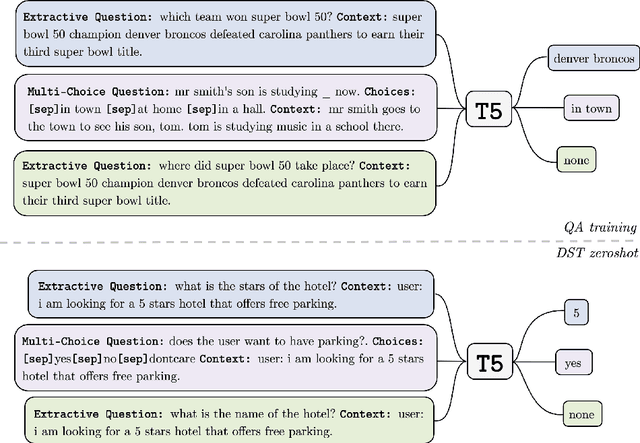
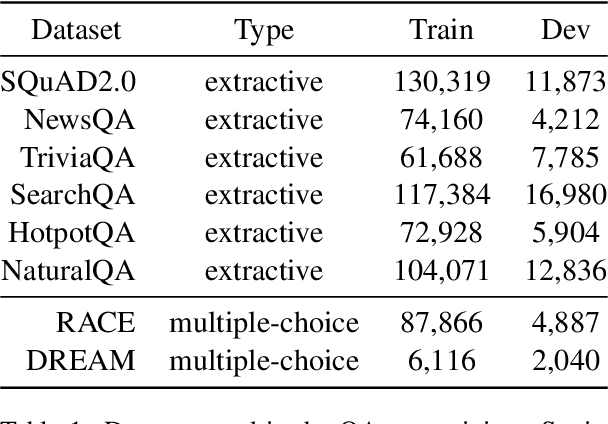
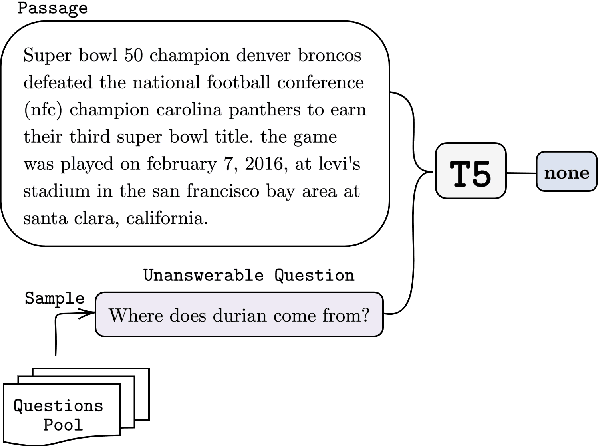
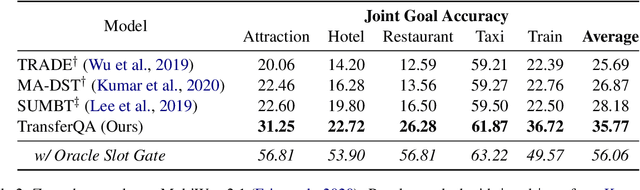
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021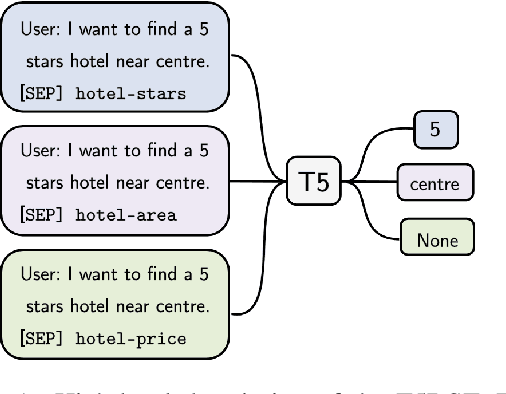

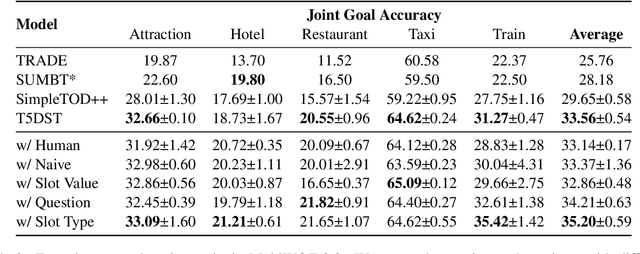
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Gated Transformer Networks for Multivariate Time Series Classification
Mar 26, 2021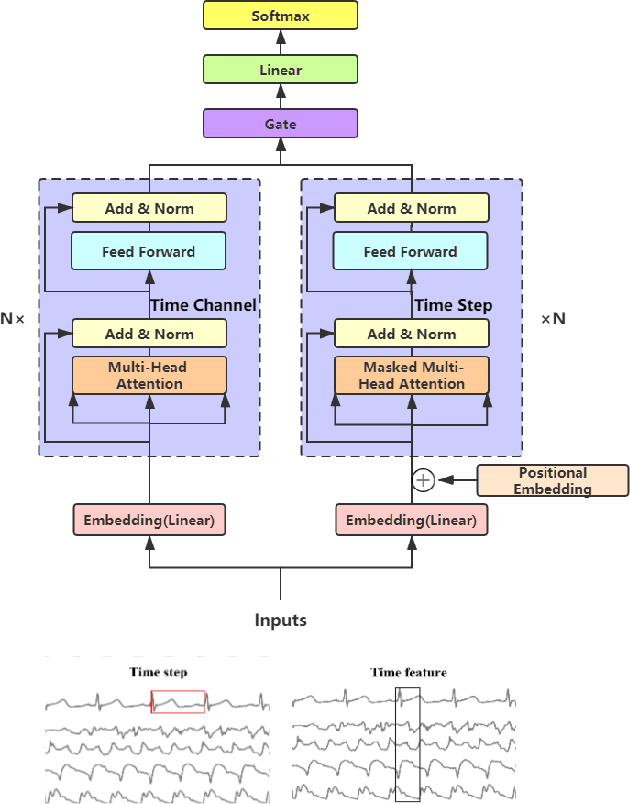
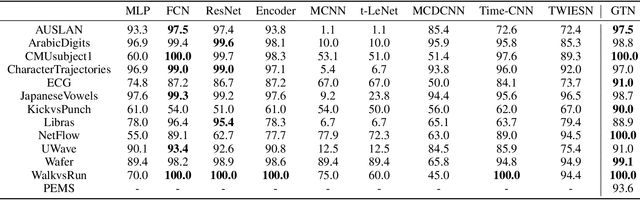
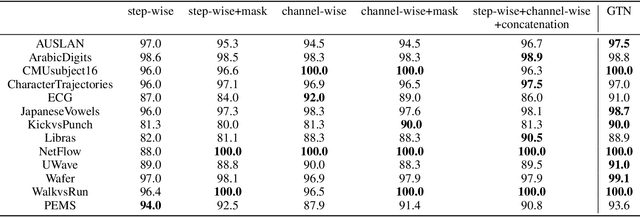
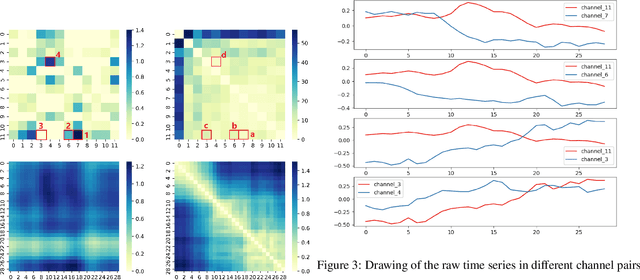
Deep learning model (primarily convolutional networks and LSTM) for time series classification has been studied broadly by the community with the wide applications in different domains like healthcare, finance, industrial engineering and IoT. Meanwhile, Transformer Networks recently achieved frontier performance on various natural language processing and computer vision tasks. In this work, we explored a simple extension of the current Transformer Networks with gating, named Gated Transformer Networks (GTN) for the multivariate time series classification problem. With the gating that merges two towers of Transformer which model the channel-wise and step-wise correlations respectively, we show how GTN is naturally and effectively suitable for the multivariate time series classification task. We conduct comprehensive experiments on thirteen dataset with full ablation study. Our results show that GTN is able to achieve competing results with current state-of-the-art deep learning models. We also explored the attention map for the natural interpretability of GTN on time series modeling. Our preliminary results provide a strong baseline for the Transformer Networks on multivariate time series classification task and grounds the foundation for future research.
Continual Learning in Task-Oriented Dialogue Systems
Dec 31, 2020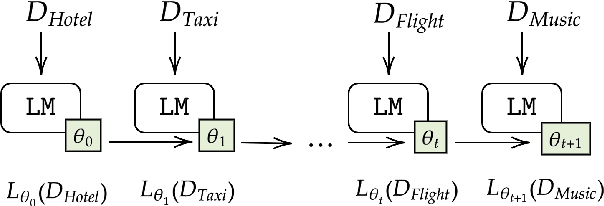
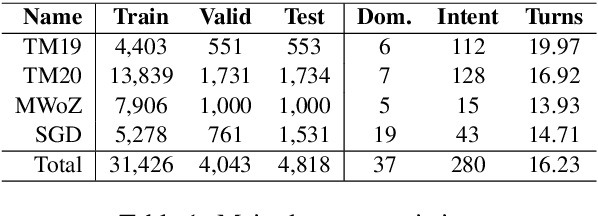

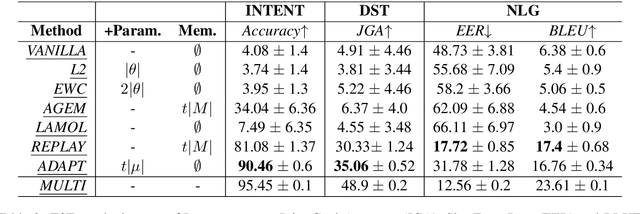
Continual learning in task-oriented dialogue systems can allow us to add new domains and functionalities through time without incurring the high cost of a whole system retraining. In this paper, we propose a continual learning benchmark for task-oriented dialogue systems with 37 domains to be learned continuously in four settings, such as intent recognition, state tracking, natural language generation, and end-to-end. Moreover, we implement and compare multiple existing continual learning baselines, and we propose a simple yet effective architectural method based on residual adapters. Our experiments demonstrate that the proposed architectural method and a simple replay-based strategy perform comparably well but they both achieve inferior performance to the multi-task learning baseline, in where all the data are shown at once, showing that continual learning in task-oriented dialogue systems is a challenging task. Furthermore, we reveal several trade-offs between different continual learning methods in term of parameter usage and memory size, which are important in the design of a task-oriented dialogue system. The proposed benchmark is released together with several baselines to promote more research in this direction.
Adding Chit-Chats to Enhance Task-Oriented Dialogues
Oct 24, 2020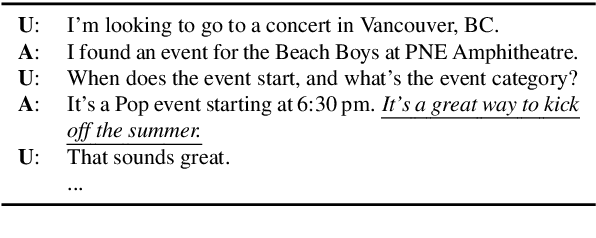
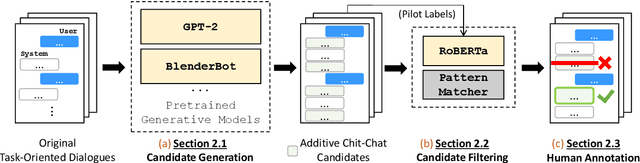
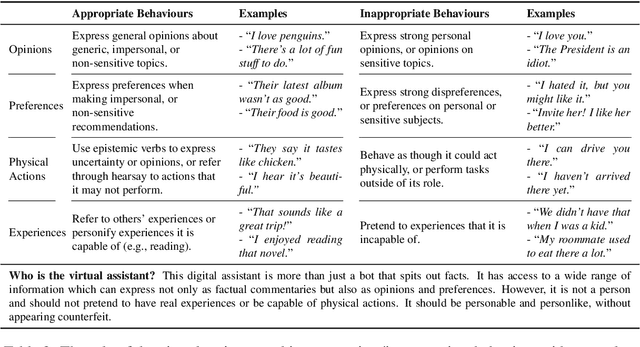
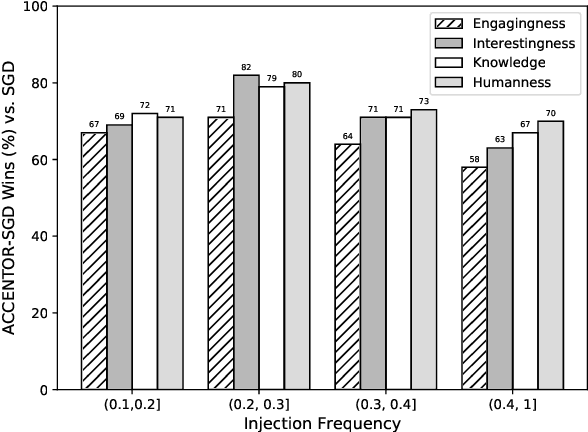
The existing dialogue corpora and models are typically designed under two disjoint motives: while task-oriented systems focus on achieving functional goals (e.g., booking hotels), open-domain chatbots aim at making socially engaging conversations. In this work, we propose to integrate both types of systems by Adding Chit-Chats to ENhance Task-ORiented dialogues (ACCENTOR), with the goal of making virtual assistant conversations more engaging and interactive. Specifically, we propose a flexible approach for generating diverse chit-chat responses to augment task-oriented dialogues with minimal annotation effort. We then present our new chit-chat annotations to 23.8K dialogues from the popular task-oriented datasets (Schema-Guided Dialogue and MultiWOZ 2.1) and demonstrate their advantage over the originals via human evaluation. Lastly, we propose three new models for ACCENTOR explicitly trained to predict user goals and to generate contextually relevant chit-chat responses. Automatic and human evaluations show that, compared with the state-of-the-art task-oriented baseline, our models can code-switch between task and chit-chat to be more engaging, interesting, knowledgeable, and humanlike, while maintaining competitive task performance.
Information Seeking in the Spirit of Learning: a Dataset for Conversational Curiosity
May 01, 2020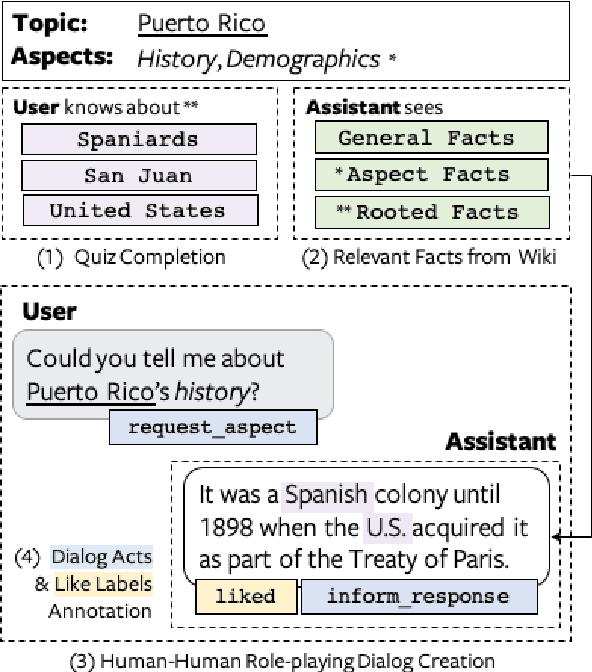
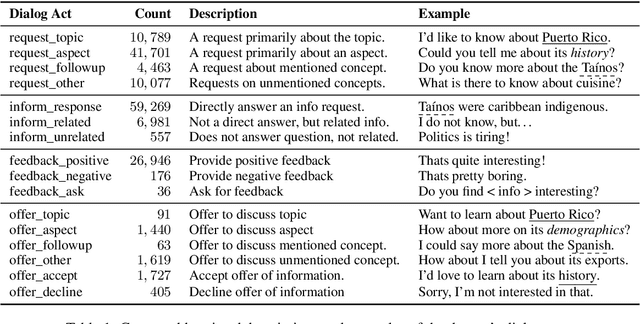
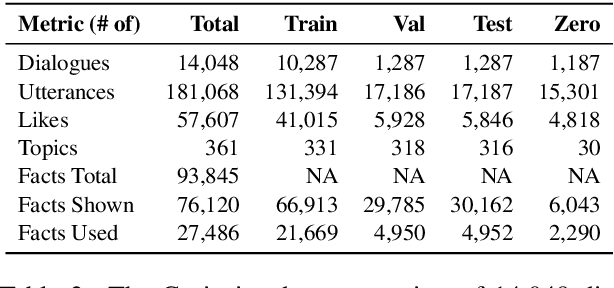
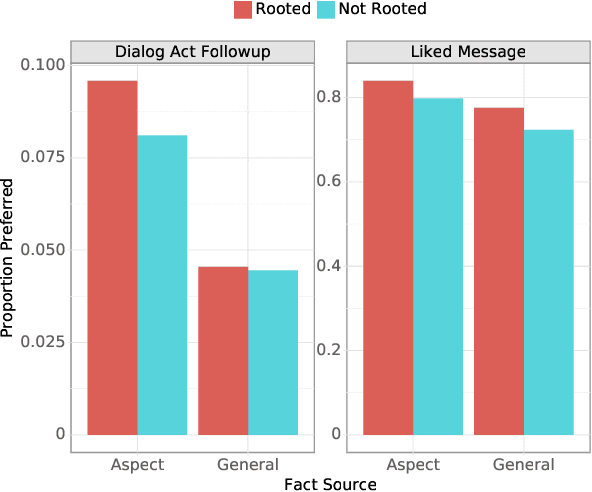
Open-ended human learning and information-seeking are increasingly mediated by technologies like digital assistants. However, such systems often fail to account for the user's pre-existing knowledge, which is a powerful way to increase engagement and to improve retention. Assuming a correlation between engagement and user responses such as "liking" messages or asking followup questions, we design a Wizard of Oz dialog task that tests the hypothesis that engagement increases when users are presented with facts that relate to their existing knowledge. Through crowd-sourcing of this experimental task we collected and now open-source 14K dialogs (181K utterances) where users and assistants converse about various aspects related to geographic entities. This dataset is annotated with pre-existing user knowledge, message-level dialog acts, message grounding to Wikipedia, user reactions to messages, and per-dialog ratings. Our analysis shows that responses which incorporate a user's prior knowledge do increase engagement. We incorporate this knowledge into a state-of-the-art multi-task model that reproduces human assistant policies, improving over content selection baselines by 13 points.
Encoding Temporal Markov Dynamics in Graph for Visualizing and Mining Time Series
Aug 14, 2018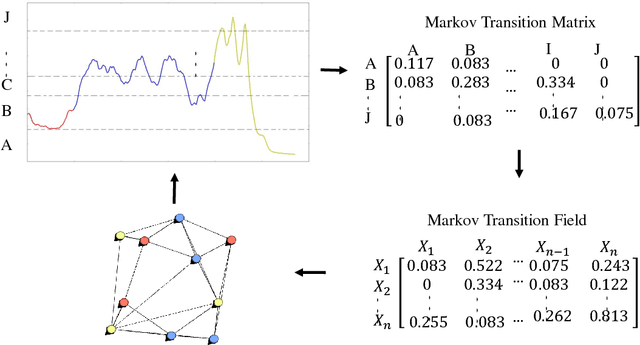
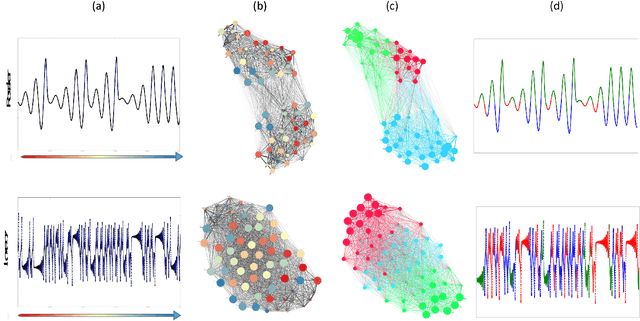
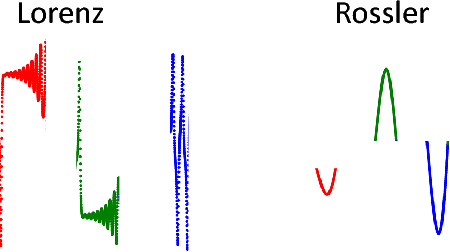
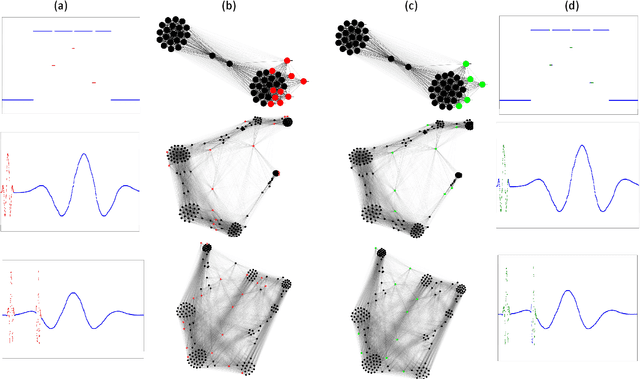
Time series and signals are attracting more attention across statistics, machine learning and pattern recognition as it appears widely in the industry especially in sensor and IoT related research and applications, but few advances has been achieved in effective time series visual analytics and interaction due to its temporal dimensionality and complex dynamics. Inspired by recent effort on using network metrics to characterize time series for classification, we present an approach to visualize time series as complex networks based on the first order Markov process in its temporal ordering. In contrast to the classical bar charts, line plots and other statistics based graph, our approach delivers more intuitive visualization that better preserves both the temporal dependency and frequency structures. It provides a natural inverse operation to map the graph back to raw signals, making it possible to use graph statistics to characterize time series for better visual exploration and statistical analysis. Our experimental results suggest the effectiveness on various tasks such as pattern discovery and classification on both synthetic and the real time series and sensor data.
Improving Native Ads CTR Prediction by Large Scale Event Embedding and Recurrent Networks
Aug 14, 2018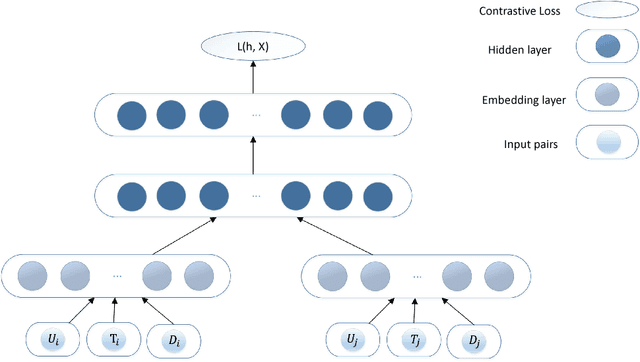

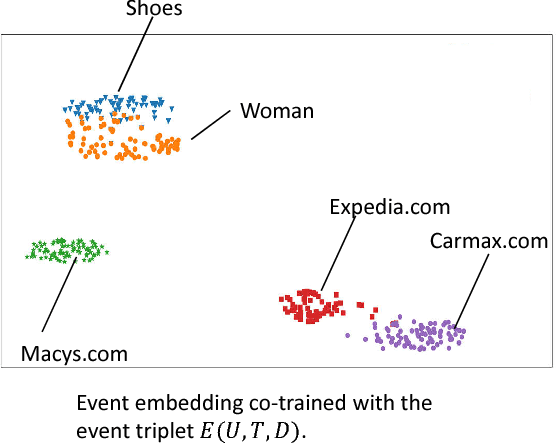

Click through rate (CTR) prediction is very important for Native advertisement but also hard as there is no direct query intent. In this paper we propose a large-scale event embedding scheme to encode the each user browsing event by training a Siamese network with weak supervision on the users' consecutive events. The CTR prediction problem is modeled as a supervised recurrent neural network, which naturally model the user history as a sequence of events. Our proposed recurrent models utilizing pretrained event embedding vectors and an attention layer to model the user history. Our experiments demonstrate that our model significantly outperforms the baseline and some variants.