 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs Meet Cunning Questions: A Fallacy Understanding Benchmark for Large Language Models
Feb 16, 2024
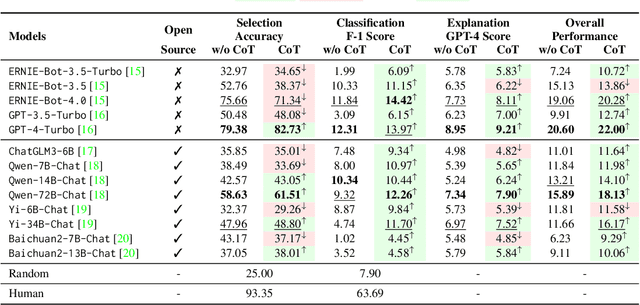

Recently, Large Language Models (LLMs) have made remarkable evolutions in language understanding and generation. Following this, various benchmarks for measuring all kinds of capabilities of LLMs have sprung up. In this paper, we challenge the reasoning and understanding abilities of LLMs by proposing a FaLlacy Understanding Benchmark (FLUB) containing cunning questions that are easy for humans to understand but difficult for models to grasp. Specifically, the cunning questions that FLUB focuses on mainly consist of the tricky, humorous, and misleading questions collected from the real internet environment. And we design three tasks with increasing difficulty in the FLUB benchmark to evaluate the fallacy understanding ability of LLMs. Based on FLUB, we investigate the performance of multiple representative and advanced LLMs, reflecting our FLUB is challenging and worthy of more future study. Interesting discoveries and valuable insights are achieved in our extensive experiments and detailed analyses. We hope that our benchmark can encourage the community to improve LLMs' ability to understand fallacies.
Enhancing Phrase Representation by Information Bottleneck Guided Text Diffusion Process for Keyphrase Extraction
Aug 17, 2023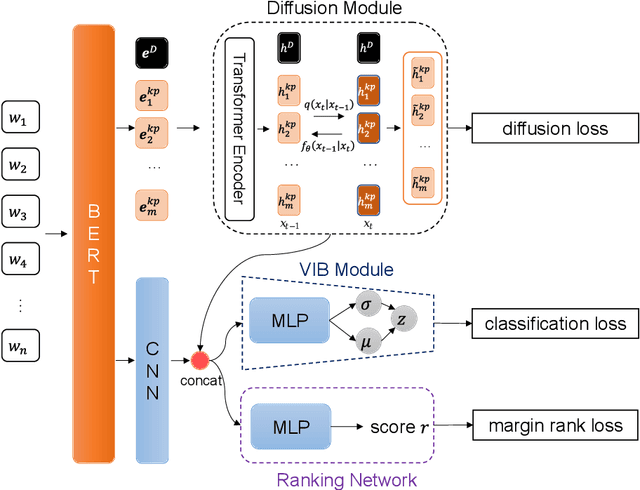



Keyphrase extraction (KPE) is an important task in Natural Language Processing for many scenarios, which aims to extract keyphrases that are present in a given document. Many existing supervised methods treat KPE as sequential labeling, span-level classification, or generative tasks. However, these methods lack the ability to utilize keyphrase information, which may result in biased results. In this study, we propose Diff-KPE, which leverages the supervised Variational Information Bottleneck (VIB) to guide the text diffusion process for generating enhanced keyphrase representations. Diff-KPE first generates the desired keyphrase embeddings conditioned on the entire document and then injects the generated keyphrase embeddings into each phrase representation. A ranking network and VIB are then optimized together with rank loss and classification loss, respectively. This design of Diff-KPE allows us to rank each candidate phrase by utilizing both the information of keyphrases and the document. Experiments show that Diff-KPE outperforms existing KPE methods on a large open domain keyphrase extraction benchmark, OpenKP, and a scientific domain dataset, KP20K.
Exploring Hidden Semantics in Neural Networks with Symbolic Regression
Apr 22, 2022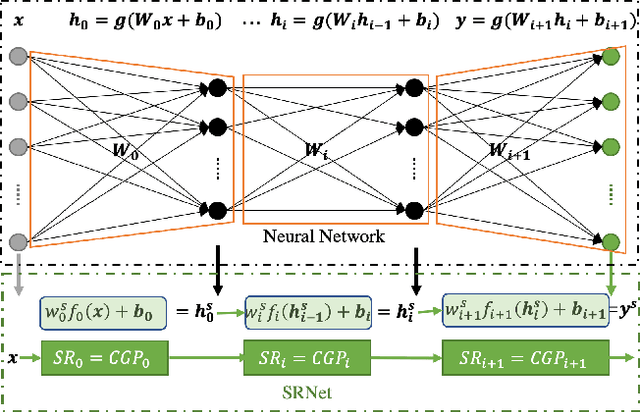

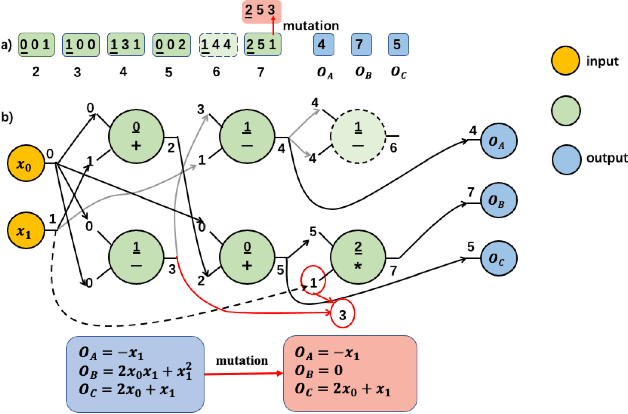
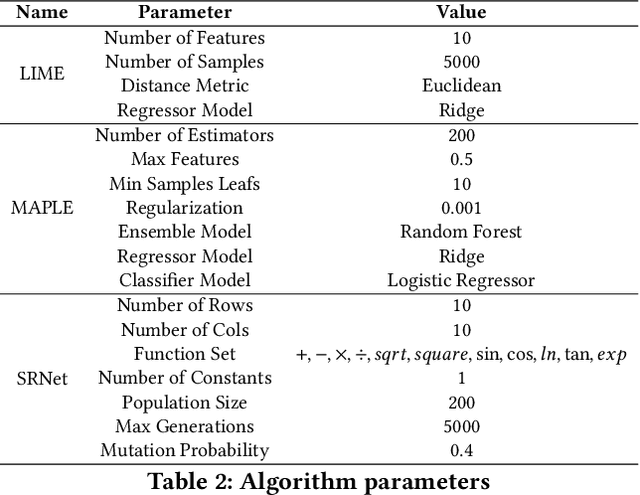
Many recent studies focus on developing mechanisms to explain the black-box behaviors of neural networks (NNs). However, little work has been done to extract the potential hidden semantics (mathematical representation) of a neural network. A succinct and explicit mathematical representation of a NN model could improve the understanding and interpretation of its behaviors. To address this need, we propose a novel symbolic regression method for neural works (called SRNet) to discover the mathematical expressions of a NN. SRNet creates a Cartesian genetic programming (NNCGP) to represent the hidden semantics of a single layer in a NN. It then leverages a multi-chromosome NNCGP to represent hidden semantics of all layers of the NN. The method uses a (1+$\lambda$) evolutionary strategy (called MNNCGP-ES) to extract the final mathematical expressions of all layers in the NN. Experiments on 12 symbolic regression benchmarks and 5 classification benchmarks show that SRNet not only can reveal the complex relationships between each layer of a NN but also can extract the mathematical representation of the whole NN. Compared with LIME and MAPLE, SRNet has higher interpolation accuracy and trends to approximate the real model on the practical dataset.