 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Robotic Language Grounding: Tradeoffs Between Symbols and Embeddings
Paper and Code
May 21, 2024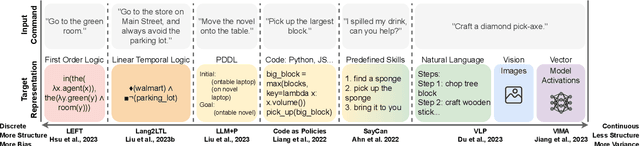

With large language models, robots can understand language more flexibly and more capable than ever before. This survey reviews recent literature and situates it into a spectrum with two poles: 1) mapping between language and some manually defined formal representation of meaning, and 2) mapping between language and high-dimensional vector spaces that translate directly to low-level robot policy. Using a formal representation allows the meaning of the language to be precisely represented, limits the size of the learning problem, and leads to a framework for interpretability and formal safety guarantees. Methods that embed language and perceptual data into high-dimensional spaces avoid this manually specified symbolic structure and thus have the potential to be more general when fed enough data but require more data and computing to train. We discuss the benefits and tradeoffs of each approach and finish by providing directions for future work that achieves the best of both worlds.