 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATTO: Balancing Preferences and Confidence in Language Models
Jan 30, 2026Large language models (LLMs) often make accurate next token predictions but their confidence in these predictions can be poorly calibrated: high-confidence predictions are frequently wrong, and low-confidence predictions may be correct. This miscalibration is exacerbated by preference-based alignment methods breaking the link between predictive probability and correctness. We introduce a Calibration Aware Token-level Training Objective (CATTO), a calibration-aware objective that aligns predicted confidence with empirical prediction correctness, which can be combined with the original preference optimization objectives. Empirically, CATTO reduces Expected Calibration Error (ECE) by 2.22%-7.61% in-distribution and 1.46%-10.44% out-of-distribution compared to direct preference optimization (DPO), and by 0.22%-1.24% in-distribution and 1.23%-5.07% out-of-distribution compared to the strongest DPO baseline. This improvement in confidence does not come at a cost of losing task accuracy, where CATTO maintains or slightly improves multiple-choice question-answering accuracy on five datasets. We also introduce Confidence@k, a test-time scaling mechanism leveraging calibrated token probabilities for Bayes-optimal selection of output tokens.
What is in a name? Mitigating Name Bias in Text Embeddings via Anonymization
Feb 05, 2025Text-embedding models often exhibit biases arising from the data on which they are trained. In this paper, we examine a hitherto unexplored bias in text-embeddings: bias arising from the presence of $\textit{names}$ such as persons, locations, organizations etc. in the text. Our study shows how the presence of $\textit{name-bias}$ in text-embedding models can potentially lead to erroneous conclusions in assessment of thematic similarity.Text-embeddings can mistakenly indicate similarity between texts based on names in the text, even when their actual semantic content has no similarity or indicate dissimilarity simply because of the names in the text even when the texts match semantically. We first demonstrate the presence of name bias in different text-embedding models and then propose $\textit{text-anonymization}$ during inference which involves removing references to names, while preserving the core theme of the text. The efficacy of the anonymization approach is demonstrated on two downstream NLP tasks, achieving significant performance gains. Our simple and training-optimization-free approach offers a practical and easily implementable solution to mitigate name bias.
POSIT: Promotion of Semantic Item Tail via Adversarial Learning
Aug 07, 2023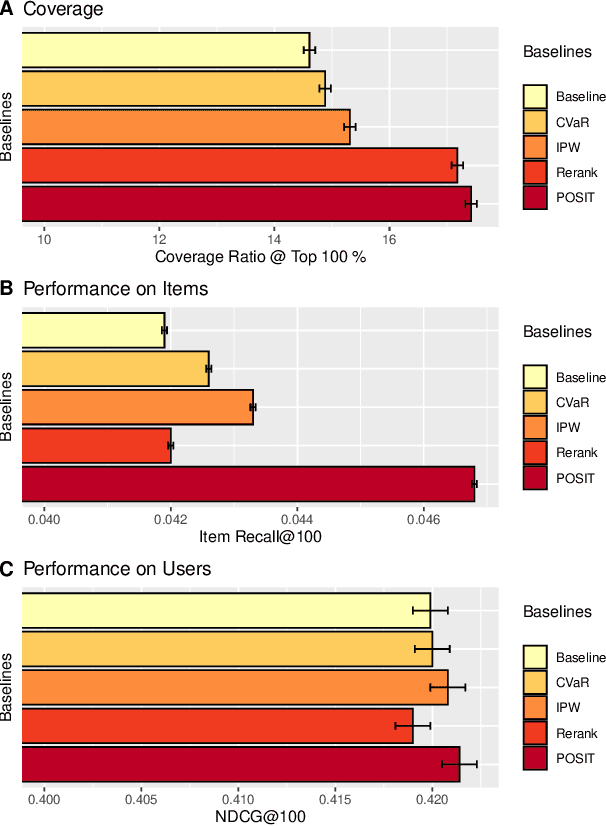
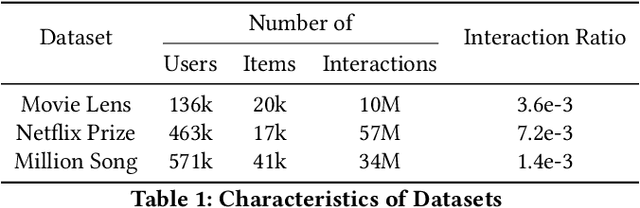
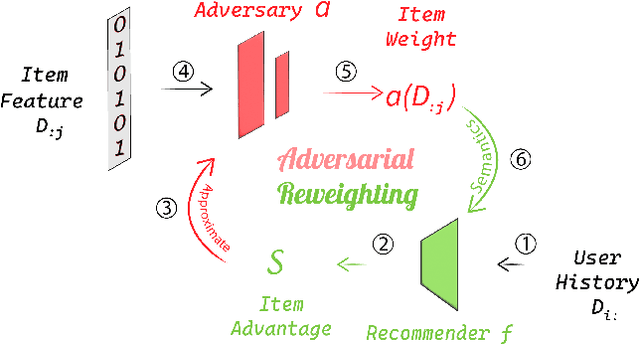
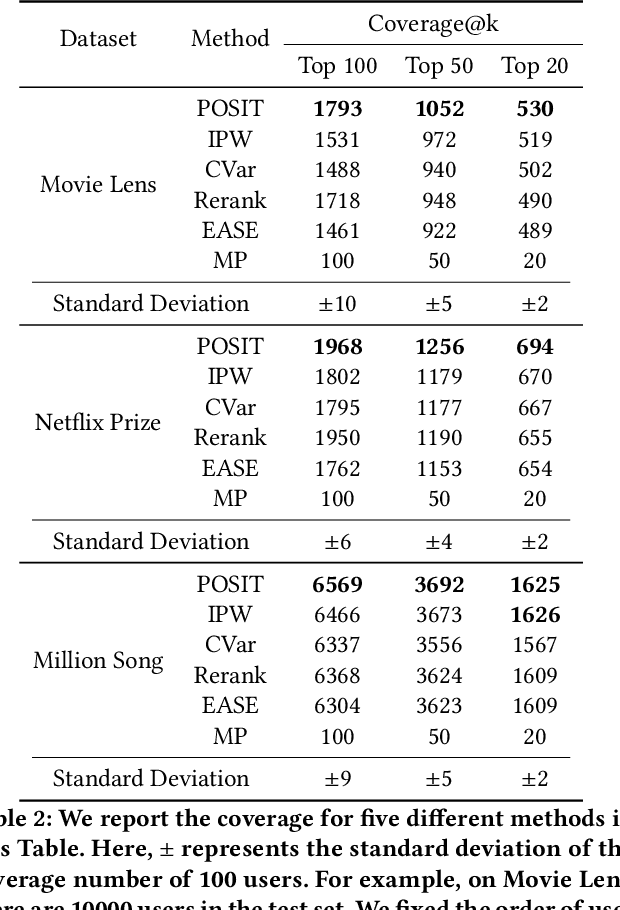
In many recommender problems, a handful of popular items (e.g. movies/TV shows, news etc.) can be dominant in recommendations for many users. However, we know that in a large catalog of items, users are likely interested in more than what is popular. The dominance of popular items may mean that users will not see items they would likely enjoy. In this paper, we propose a technique to overcome this problem using adversarial machine learning. We define a metric to translate user-level utility metric in terms of an advantage/disadvantage over items. We subsequently use that metric in an adversarial learning framework to systematically promote disadvantaged items. The resulting algorithm identifies semantically meaningful items that get promoted in the learning algorithm. In the empirical study, we evaluate the proposed technique on three publicly available datasets and four competitive baselines. The result shows that our proposed method not only improves the coverage, but also, surprisingly, improves the overall performance.
Online Structured Prediction via Coactive Learning
Jun 27, 2012

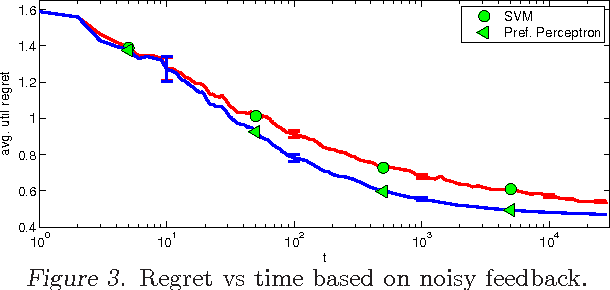

We propose Coactive Learning as a model of interaction between a learning system and a human user, where both have the common goal of providing results of maximum utility to the user. At each step, the system (e.g. search engine) receives a context (e.g. query) and predicts an object (e.g. ranking). The user responds by correcting the system if necessary, providing a slightly improved -- but not necessarily optimal -- object as feedback. We argue that such feedback can often be inferred from observable user behavior, for example, from clicks in web-search. Evaluating predictions by their cardinal utility to the user, we propose efficient learning algorithms that have ${\cal O}(\frac{1}{\sqrt{T}})$ average regret, even though the learning algorithm never observes cardinal utility values as in conventional online learning. We demonstrate the applicability of our model and learning algorithms on a movie recommendation task, as well as ranking for web-search.
Large-Margin Learning of Submodular Summarization Methods
Oct 13, 2011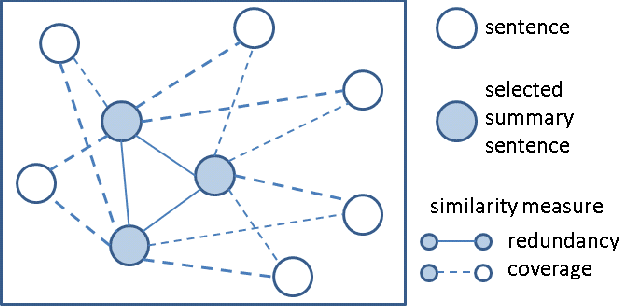
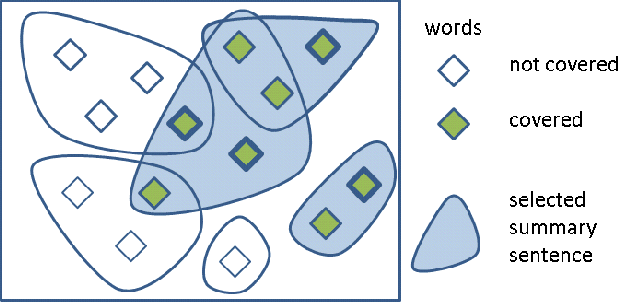
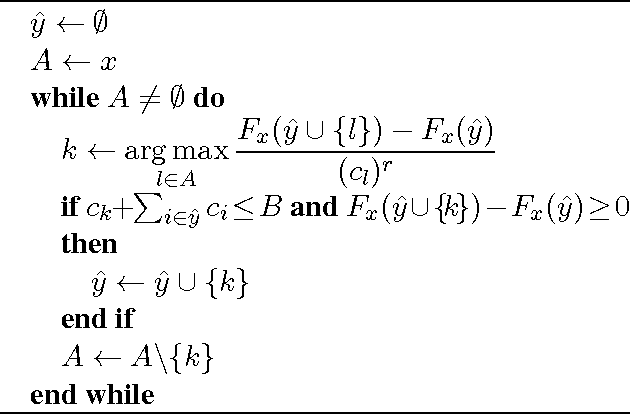

In this paper, we present a supervised learning approach to training submodular scoring functions for extractive multi-document summarization. By taking a structured predicition approach, we provide a large-margin method that directly optimizes a convex relaxation of the desired performance measure. The learning method applies to all submodular summarization methods, and we demonstrate its effectiveness for both pairwise as well as coverage-based scoring functions on multiple datasets. Compared to state-of-the-art functions that were tuned manually, our method significantly improves performance and enables high-fidelity models with numbers of parameters well beyond what could reasonbly be tuned by hand.