Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Margin Learning of Submodular Summarization Methods
Paper and Code
Oct 13, 2011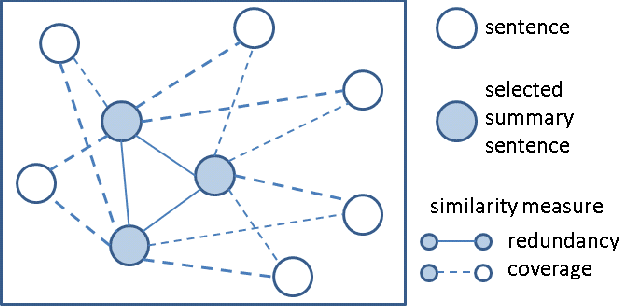
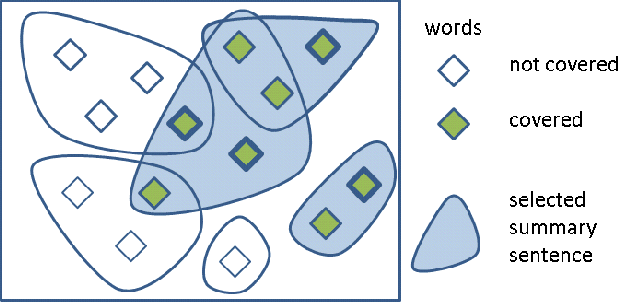
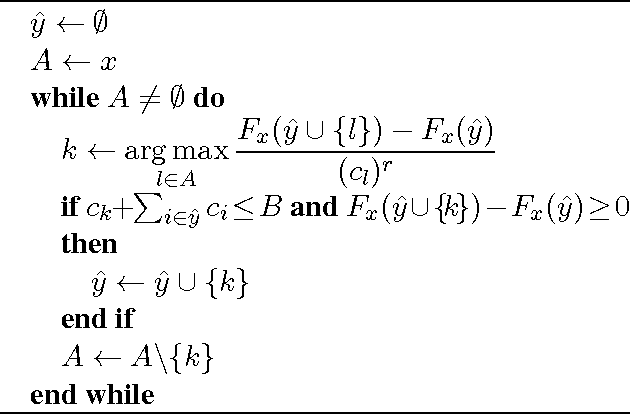

In this paper, we present a supervised learning approach to training submodular scoring functions for extractive multi-document summarization. By taking a structured predicition approach, we provide a large-margin method that directly optimizes a convex relaxation of the desired performance measure. The learning method applies to all submodular summarization methods, and we demonstrate its effectiveness for both pairwise as well as coverage-based scoring functions on multiple datasets. Compared to state-of-the-art functions that were tuned manually, our method significantly improves performance and enables high-fidelity models with numbers of parameters well beyond what could reasonbly be tuned by hand.
* update: improved formatting (figure placement) and algorithm
pseudocode clarity (Fig. 3)
View paper on