 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle-MedGemma Based Abnormality Detection in Musculoskeletal radiographs
Nov 06, 2025This paper proposes a MedGemma-based framework for automatic abnormality detection in musculoskeletal radiographs. Departing from conventional autoencoder and neural network pipelines, the proposed method leverages the MedGemma foundation model, incorporating a SigLIP-derived vision encoder pretrained on diverse medical imaging modalities. Preprocessed X-ray images are encoded into high-dimensional embeddings using the MedGemma vision backbone, which are subsequently passed through a lightweight multilayer perceptron for binary classification. Experimental assessment reveals that the MedGemma-driven classifier exhibits strong performance, exceeding conventional convolutional and autoencoder-based metrics. Additionally, the model leverages MedGemma's transfer learning capabilities, enhancing generalization and optimizing feature engineering. The integration of a modern medical foundation model not only enhances representation learning but also facilitates modular training strategies such as selective encoder block unfreezing for efficient domain adaptation. The findings suggest that MedGemma-powered classification systems can advance clinical radiograph triage by providing scalable and accurate abnormality detection, with potential for broader applications in automated medical image analysis. Keywords: Google MedGemma, MURA, Medical Image, Classification.
Exploring the Use of LLMs for SQL Equivalence Checking
Dec 07, 2024Equivalence checking of two SQL queries is an intractable problem encountered in diverse contexts ranging from grading student submissions in a DBMS course to debugging query rewriting rules in an optimizer, and many more. While a lot of progress has been made in recent years in developing practical solutions for this problem, the existing methods can handle only a small subset of SQL, even for bounded equivalence checking. They cannot support sophisticated SQL expressions one encounters in practice. At the same time, large language models (LLMs) -- such as GPT-4 -- have emerged as power generators of SQL from natural language specifications. This paper explores whether LLMs can also demonstrate the ability to reason with SQL queries and help advance SQL equivalence checking. Towards this, we conducted a detailed evaluation of several LLMs over collections with SQL pairs of varying levels of complexity. We explored the efficacy of different prompting techniques, the utility of synthetic examples & explanations, as well as logical plans generated by query parsers. Our main finding is that with well-designed prompting using an unoptimized SQL Logical Plan, LLMs can perform equivalence checking beyond the capabilities of current techniques, achieving nearly 100% accuracy for equivalent pairs and up to 70% for non-equivalent pairs of SQL queries. While LLMs lack the ability to generate formal proofs, their synthetic examples and human-readable explanations offer valuable insights to students (& instructors) in a classroom setting and to database administrators (DBAs) managing large database installations. Additionally, we also show that with careful fine-tuning, we can close the performance gap between smaller (and efficient) models and larger models such as GPT, thus paving the way for potential LLM-integration in standalone data processing systems.
Embeddings for Tabular Data: A Survey
Feb 23, 2023

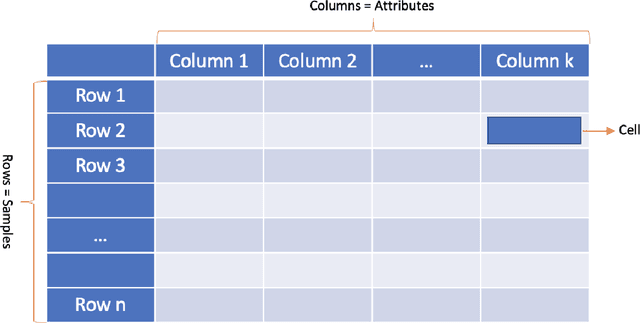
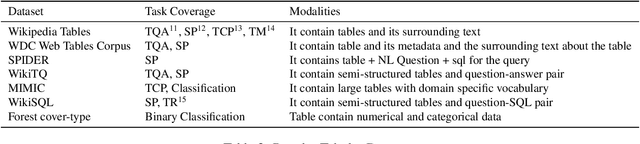
Tabular data comprising rows (samples) with the same set of columns (attributes, is one of the most widely used data-type among various industries, including financial services, health care, research, retail, and logistics, to name a few. Tables are becoming the natural way of storing data among various industries and academia. The data stored in these tables serve as an essential source of information for making various decisions. As computational power and internet connectivity increase, the data stored by these companies grow exponentially, and not only do the databases become vast and challenging to maintain and operate, but the quantity of database tasks also increases. Thus a new line of research work has been started, which applies various learning techniques to support various database tasks for such large and complex tables. In this work, we split the quest of learning on tabular data into two phases: The Classical Learning Phase and The Modern Machine Learning Phase. The classical learning phase consists of the models such as SVMs, linear and logistic regression, and tree-based methods. These models are best suited for small-size tables. However, the number of tasks these models can address is limited to classification and regression. In contrast, the Modern Machine Learning Phase contains models that use deep learning for learning latent space representation of table entities. The objective of this survey is to scrutinize the varied approaches used by practitioners to learn representation for the structured data, and to compare their efficacy.
A Survey of Knowledge Graph Embedding and Their Applications
Jul 16, 2021
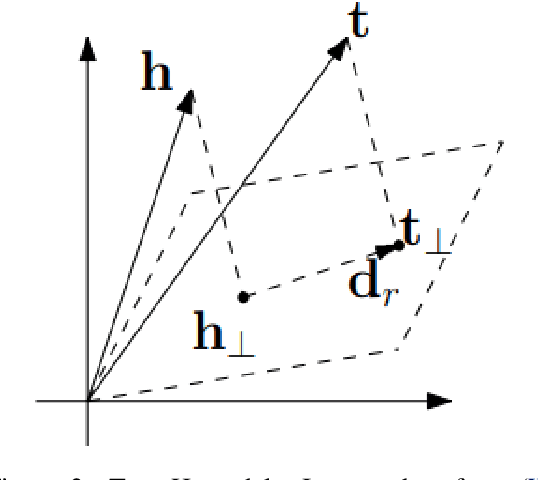
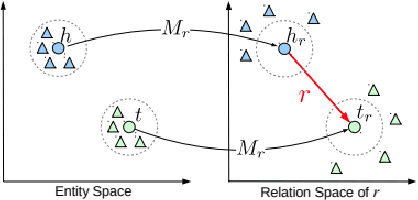
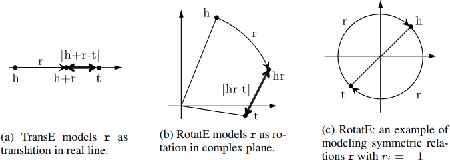
Knowledge Graph embedding provides a versatile technique for representing knowledge. These techniques can be used in a variety of applications such as completion of knowledge graph to predict missing information, recommender systems, question answering, query expansion, etc. The information embedded in Knowledge graph though being structured is challenging to consume in a real-world application. Knowledge graph embedding enables the real-world application to consume information to improve performance. Knowledge graph embedding is an active research area. Most of the embedding methods focus on structure-based information. Recent research has extended the boundary to include text-based information and image-based information in entity embedding. Efforts have been made to enhance the representation with context information. This paper introduces growth in the field of KG embedding from simple translation-based models to enrichment-based models. This paper includes the utility of the Knowledge graph in real-world applications.
Cross-Lingual Task-Specific Representation Learning for Text Classification in Resource Poor Languages
Jun 10, 2018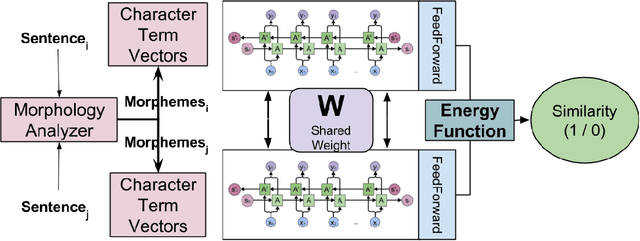


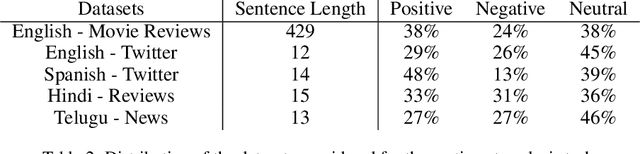
Neural network models have shown promising results for text classification. However, these solutions are limited by their dependence on the availability of annotated data. The prospect of leveraging resource-rich languages to enhance the text classification of resource-poor languages is fascinating. The performance on resource-poor languages can significantly improve if the resource availability constraints can be offset. To this end, we present a twin Bidirectional Long Short Term Memory (Bi-LSTM) network with shared parameters consolidated by a contrastive loss function (based on a similarity metric). The model learns the representation of resource-poor and resource-rich sentences in a common space by using the similarity between their assigned annotation tags. Hence, the model projects sentences with similar tags closer and those with different tags farther from each other. We evaluated our model on the classification tasks of sentiment analysis and emoji prediction for resource-poor languages - Hindi and Telugu and resource-rich languages - English and Spanish. Our model significantly outperforms the state-of-the-art approaches in both the tasks across all metrics.
Contrastive Learning of Emoji-based Representations for Resource-Poor Languages
Apr 03, 2018
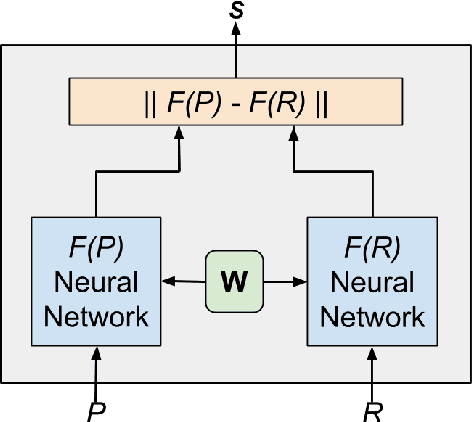
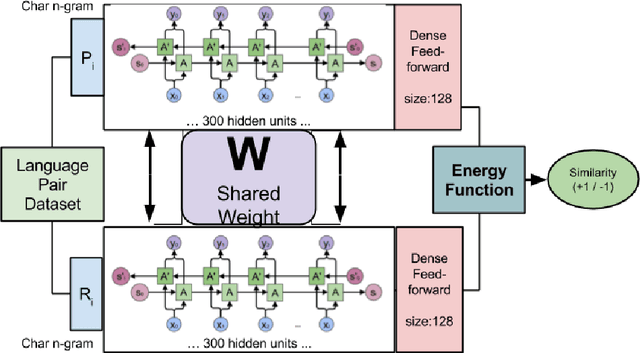
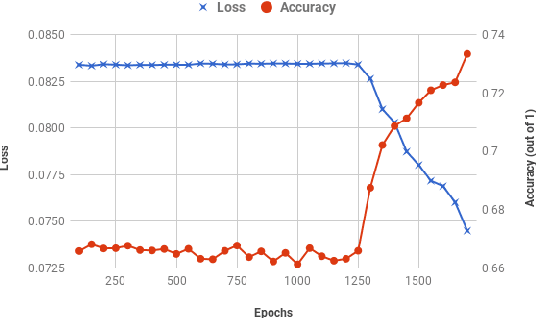
The introduction of emojis (or emoticons) in social media platforms has given the users an increased potential for expression. We propose a novel method called Classification of Emojis using Siamese Network Architecture (CESNA) to learn emoji-based representations of resource-poor languages by jointly training them with resource-rich languages using a siamese network. CESNA model consists of twin Bi-directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN) with shared parameters joined by a contrastive loss function based on a similarity metric. The model learns the representations of resource-poor and resource-rich language in a common emoji space by using a similarity metric based on the emojis present in sentences from both languages. The model, hence, projects sentences with similar emojis closer to each other and the sentences with different emojis farther from one another. Experiments on large-scale Twitter datasets of resource-rich languages - English and Spanish and resource-poor languages - Hindi and Telugu reveal that CESNA outperforms the state-of-the-art emoji prediction approaches based on distributional semantics, semantic rules, lexicon lists and deep neural network representations without shared parameters.
Sentiment Analysis of Code-Mixed Languages leveraging Resource Rich Languages
Apr 03, 2018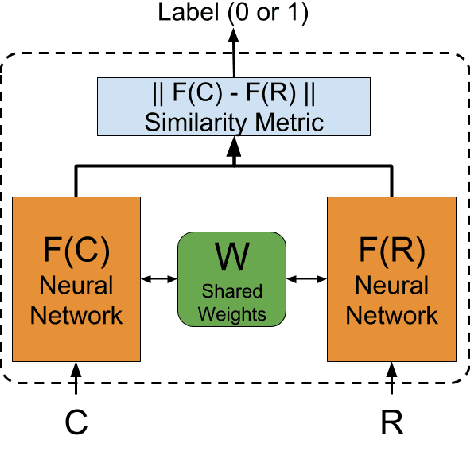
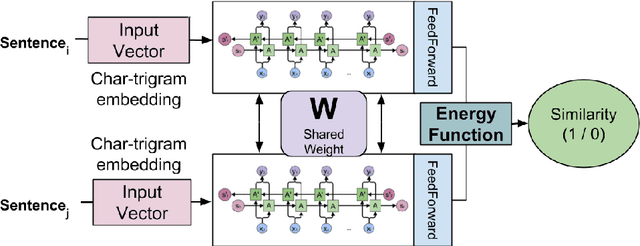

Code-mixed data is an important challenge of natural language processing because its characteristics completely vary from the traditional structures of standard languages. In this paper, we propose a novel approach called Sentiment Analysis of Code-Mixed Text (SACMT) to classify sentences into their corresponding sentiment - positive, negative or neutral, using contrastive learning. We utilize the shared parameters of siamese networks to map the sentences of code-mixed and standard languages to a common sentiment space. Also, we introduce a basic clustering based preprocessing method to capture variations of code-mixed transliterated words. Our experiments reveal that SACMT outperforms the state-of-the-art approaches in sentiment analysis for code-mixed text by 7.6% in accuracy and 10.1% in F-score.
Emotions are Universal: Learning Sentiment Based Representations of Resource-Poor Languages using Siamese Networks
Apr 03, 2018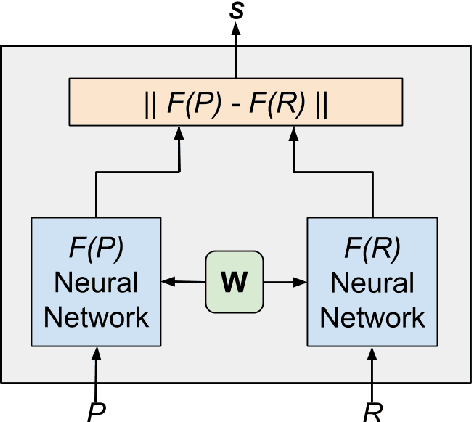
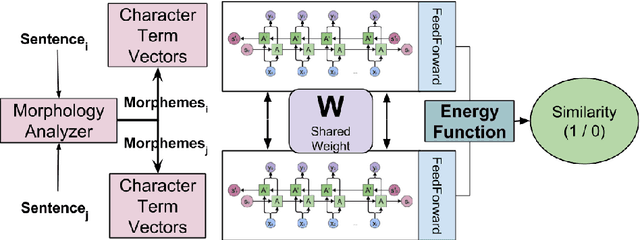
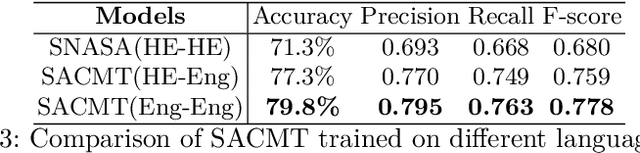
Machine learning approaches in sentiment analysis principally rely on the abundance of resources. To limit this dependence, we propose a novel method called Siamese Network Architecture for Sentiment Analysis (SNASA) to learn representations of resource-poor languages by jointly training them with resource-rich languages using a siamese network. SNASA model consists of twin Bi-directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN) with shared parameters joined by a contrastive loss function, based on a similarity metric. The model learns the sentence representations of resource-poor and resource-rich language in a common sentiment space by using a similarity metric based on their individual sentiments. The model, hence, projects sentences with similar sentiment closer to each other and the sentences with different sentiment farther from each other. Experiments on large-scale datasets of resource-rich languages - English and Spanish and resource-poor languages - Hindi and Telugu reveal that SNASA outperforms the state-of-the-art sentiment analysis approaches based on distributional semantics, semantic rules, lexicon lists and deep neural network representations without sh
Automatic Normalization of Word Variations in Code-Mixed Social Media Text
Apr 03, 2018
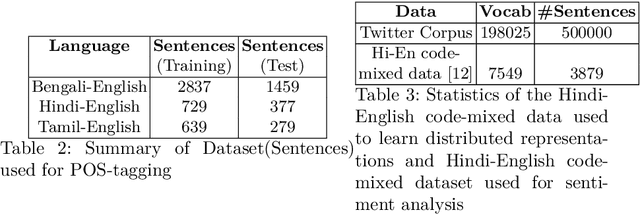
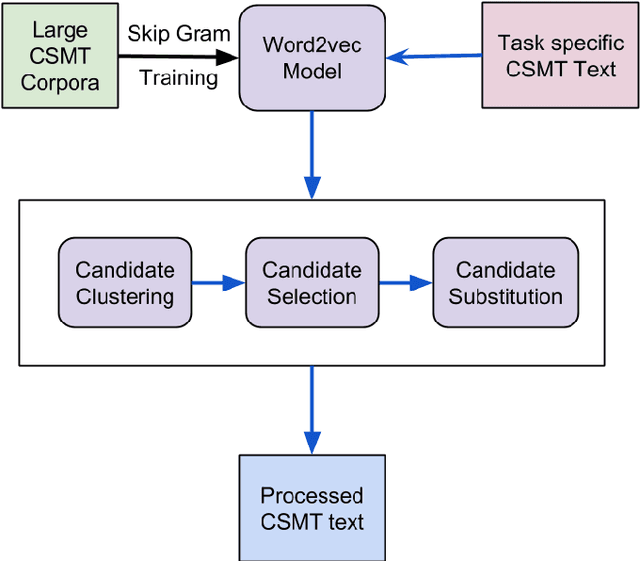
Social media platforms such as Twitter and Facebook are becoming popular in multilingual societies. This trend induces portmanteau of South Asian languages with English. The blend of multiple languages as code-mixed data has recently become popular in research communities for various NLP tasks. Code-mixed data consist of anomalies such as grammatical errors and spelling variations. In this paper, we leverage the contextual property of words where the different spelling variation of words share similar context in a large noisy social media text. We capture different variations of words belonging to same context in an unsupervised manner using distributed representations of words. Our experiments reveal that preprocessing of the code-mixed dataset based on our approach improves the performance in state-of-the-art part-of-speech tagging (POS-tagging) and sentiment analysis tasks.
Neural Network Architecture for Credibility Assessment of Textual Claims
Mar 30, 2018
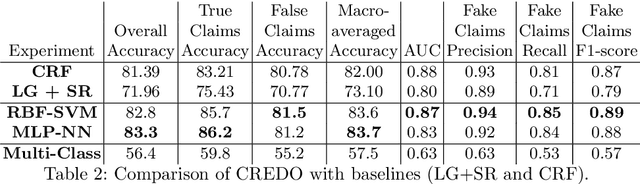
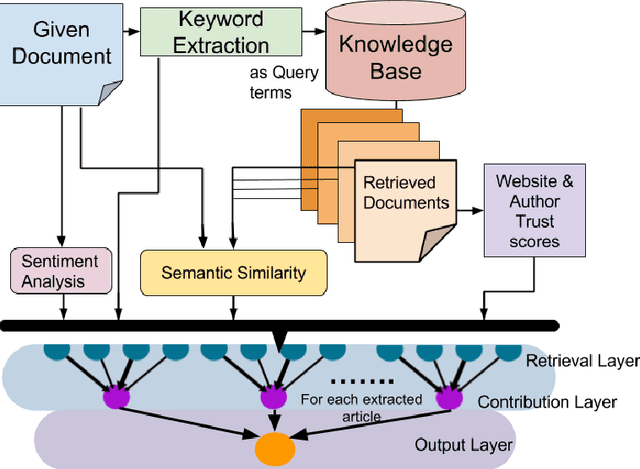
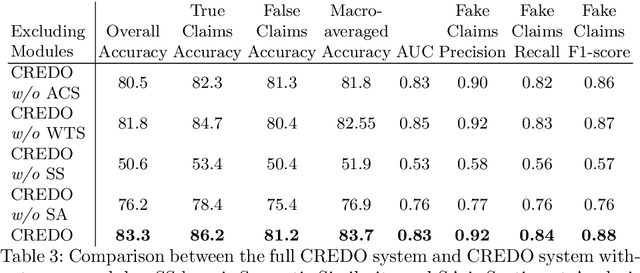
Text articles with false claims, especially news, have recently become aggravating for the Internet users. These articles are in wide circulation and readers face difficulty discerning fact from fiction. Previous work on credibility assessment has focused on factual analysis and linguistic features. The task's main challenge is the distinction between the features of true and false articles. In this paper, we propose a novel approach called Credibility Outcome (CREDO) which aims at scoring the credibility of an article in an open domain setting. CREDO consists of different modules for capturing various features responsible for the credibility of an article. These features includes credibility of the article's source and author, semantic similarity between the article and related credible articles retrieved from a knowledge base, and sentiments conveyed by the article. A neural network architecture learns the contribution of each of these modules to the overall credibility of an article. Experiments on Snopes dataset reveals that CREDO outperforms the state-of-the-art approaches based on linguistic features.