 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Architecture for Credibility Assessment of Textual Claims
Paper and Code
Mar 30, 2018
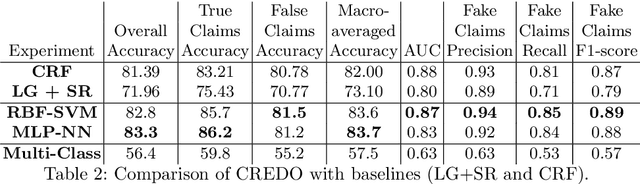
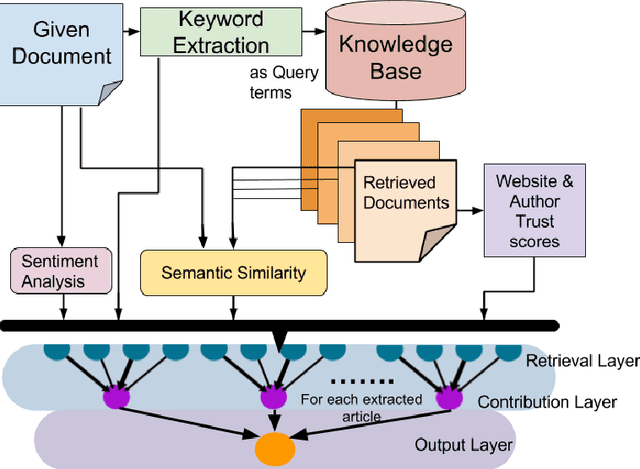
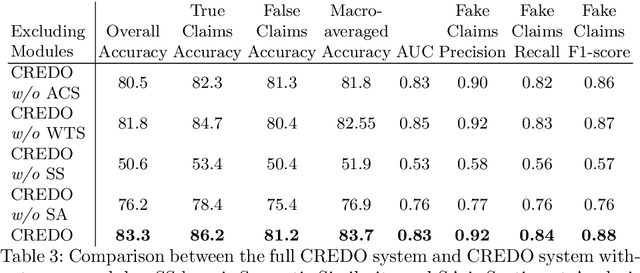
Text articles with false claims, especially news, have recently become aggravating for the Internet users. These articles are in wide circulation and readers face difficulty discerning fact from fiction. Previous work on credibility assessment has focused on factual analysis and linguistic features. The task's main challenge is the distinction between the features of true and false articles. In this paper, we propose a novel approach called Credibility Outcome (CREDO) which aims at scoring the credibility of an article in an open domain setting. CREDO consists of different modules for capturing various features responsible for the credibility of an article. These features includes credibility of the article's source and author, semantic similarity between the article and related credible articles retrieved from a knowledge base, and sentiments conveyed by the article. A neural network architecture learns the contribution of each of these modules to the overall credibility of an article. Experiments on Snopes dataset reveals that CREDO outperforms the state-of-the-art approaches based on linguistic features.