 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Emoji-based Representations for Resource-Poor Languages
Apr 03, 2018
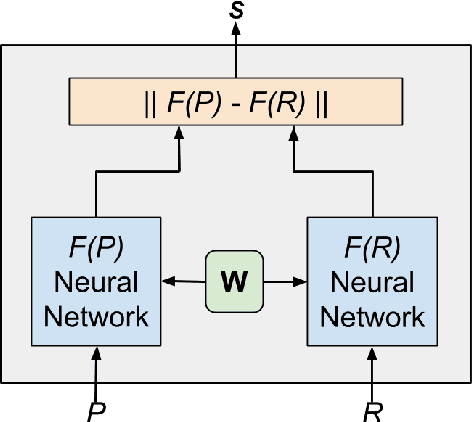
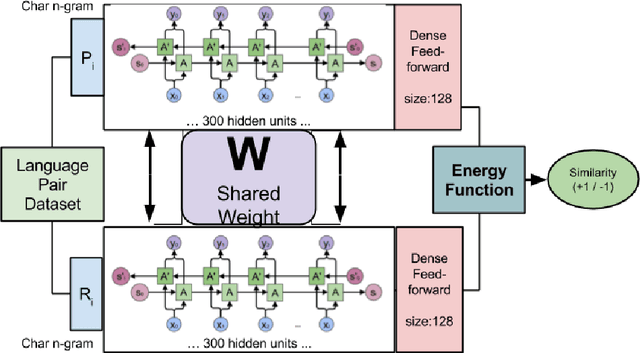
The introduction of emojis (or emoticons) in social media platforms has given the users an increased potential for expression. We propose a novel method called Classification of Emojis using Siamese Network Architecture (CESNA) to learn emoji-based representations of resource-poor languages by jointly training them with resource-rich languages using a siamese network. CESNA model consists of twin Bi-directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN) with shared parameters joined by a contrastive loss function based on a similarity metric. The model learns the representations of resource-poor and resource-rich language in a common emoji space by using a similarity metric based on the emojis present in sentences from both languages. The model, hence, projects sentences with similar emojis closer to each other and the sentences with different emojis farther from one another. Experiments on large-scale Twitter datasets of resource-rich languages - English and Spanish and resource-poor languages - Hindi and Telugu reveal that CESNA outperforms the state-of-the-art emoji prediction approaches based on distributional semantics, semantic rules, lexicon lists and deep neural network representations without shared parameters.
Sentiment Analysis of Code-Mixed Languages leveraging Resource Rich Languages
Apr 03, 2018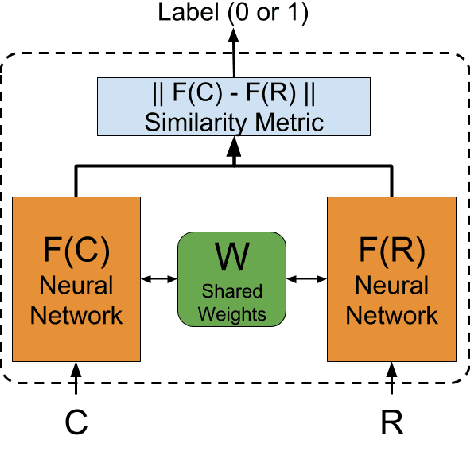
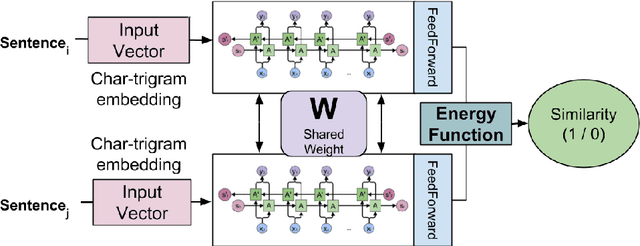

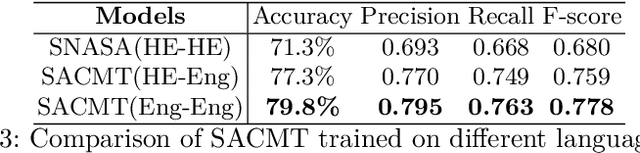
Code-mixed data is an important challenge of natural language processing because its characteristics completely vary from the traditional structures of standard languages. In this paper, we propose a novel approach called Sentiment Analysis of Code-Mixed Text (SACMT) to classify sentences into their corresponding sentiment - positive, negative or neutral, using contrastive learning. We utilize the shared parameters of siamese networks to map the sentences of code-mixed and standard languages to a common sentiment space. Also, we introduce a basic clustering based preprocessing method to capture variations of code-mixed transliterated words. Our experiments reveal that SACMT outperforms the state-of-the-art approaches in sentiment analysis for code-mixed text by 7.6% in accuracy and 10.1% in F-score.
Emotions are Universal: Learning Sentiment Based Representations of Resource-Poor Languages using Siamese Networks
Apr 03, 2018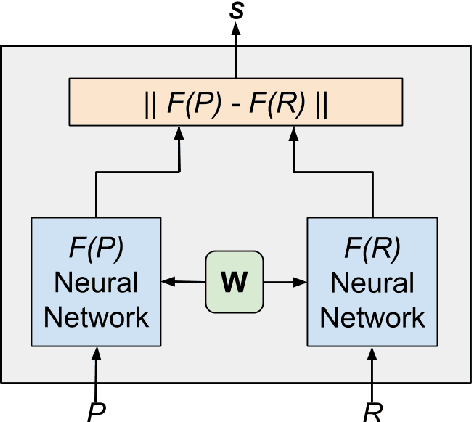
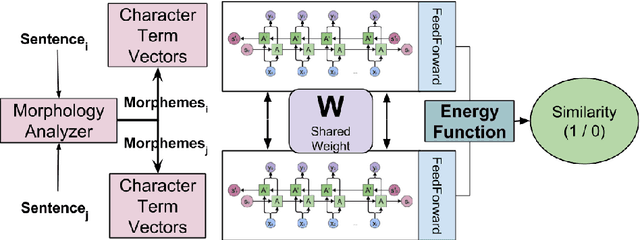
Machine learning approaches in sentiment analysis principally rely on the abundance of resources. To limit this dependence, we propose a novel method called Siamese Network Architecture for Sentiment Analysis (SNASA) to learn representations of resource-poor languages by jointly training them with resource-rich languages using a siamese network. SNASA model consists of twin Bi-directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN) with shared parameters joined by a contrastive loss function, based on a similarity metric. The model learns the sentence representations of resource-poor and resource-rich language in a common sentiment space by using a similarity metric based on their individual sentiments. The model, hence, projects sentences with similar sentiment closer to each other and the sentences with different sentiment farther from each other. Experiments on large-scale datasets of resource-rich languages - English and Spanish and resource-poor languages - Hindi and Telugu reveal that SNASA outperforms the state-of-the-art sentiment analysis approaches based on distributional semantics, semantic rules, lexicon lists and deep neural network representations without sh
Neural Network Architecture for Credibility Assessment of Textual Claims
Mar 30, 2018
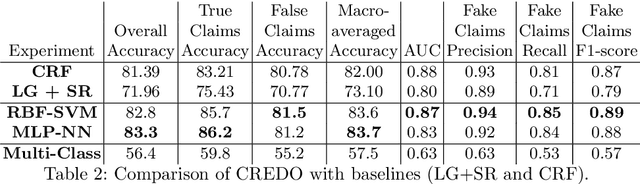
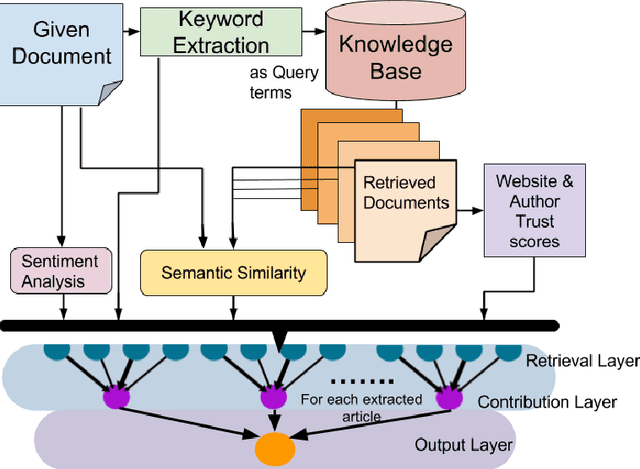
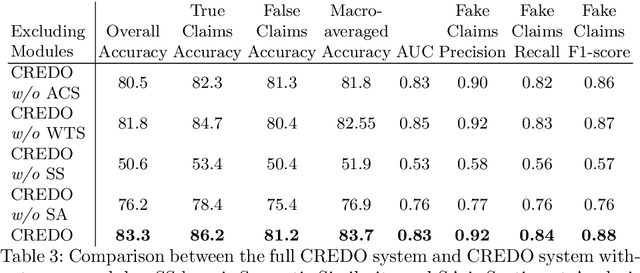
Text articles with false claims, especially news, have recently become aggravating for the Internet users. These articles are in wide circulation and readers face difficulty discerning fact from fiction. Previous work on credibility assessment has focused on factual analysis and linguistic features. The task's main challenge is the distinction between the features of true and false articles. In this paper, we propose a novel approach called Credibility Outcome (CREDO) which aims at scoring the credibility of an article in an open domain setting. CREDO consists of different modules for capturing various features responsible for the credibility of an article. These features includes credibility of the article's source and author, semantic similarity between the article and related credible articles retrieved from a knowledge base, and sentiments conveyed by the article. A neural network architecture learns the contribution of each of these modules to the overall credibility of an article. Experiments on Snopes dataset reveals that CREDO outperforms the state-of-the-art approaches based on linguistic features.