 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning of Emoji-based Representations for Resource-Poor Languages
Paper and Code
Apr 03, 2018
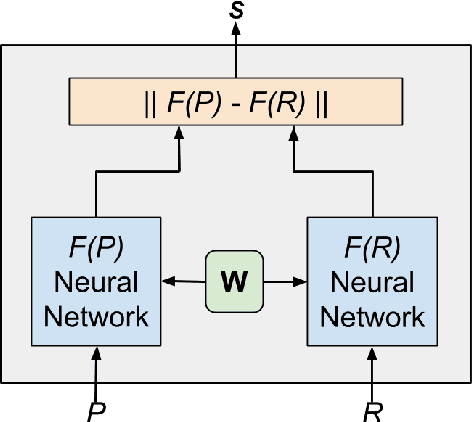
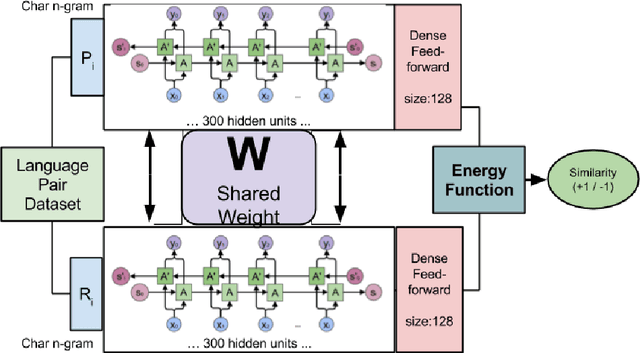
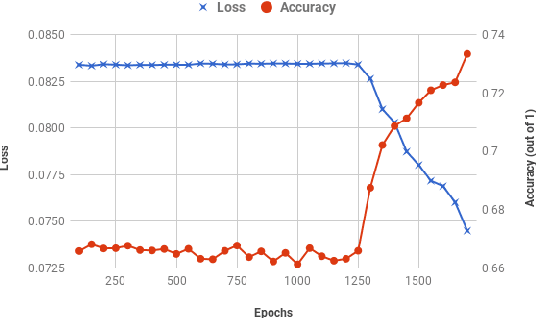
The introduction of emojis (or emoticons) in social media platforms has given the users an increased potential for expression. We propose a novel method called Classification of Emojis using Siamese Network Architecture (CESNA) to learn emoji-based representations of resource-poor languages by jointly training them with resource-rich languages using a siamese network. CESNA model consists of twin Bi-directional Long Short-Term Memory Recurrent Neural Networks (Bi-LSTM RNN) with shared parameters joined by a contrastive loss function based on a similarity metric. The model learns the representations of resource-poor and resource-rich language in a common emoji space by using a similarity metric based on the emojis present in sentences from both languages. The model, hence, projects sentences with similar emojis closer to each other and the sentences with different emojis farther from one another. Experiments on large-scale Twitter datasets of resource-rich languages - English and Spanish and resource-poor languages - Hindi and Telugu reveal that CESNA outperforms the state-of-the-art emoji prediction approaches based on distributional semantics, semantic rules, lexicon lists and deep neural network representations without shared parameters.