 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis of Code-Mixed Languages leveraging Resource Rich Languages
Paper and Code
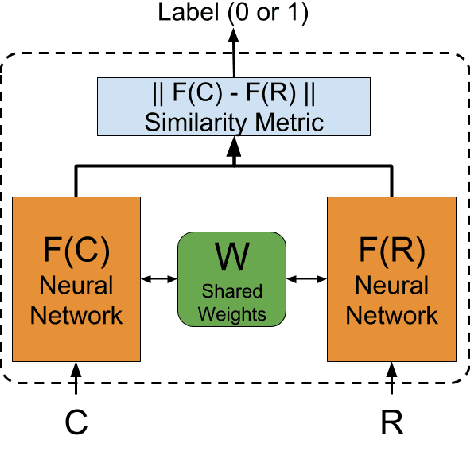
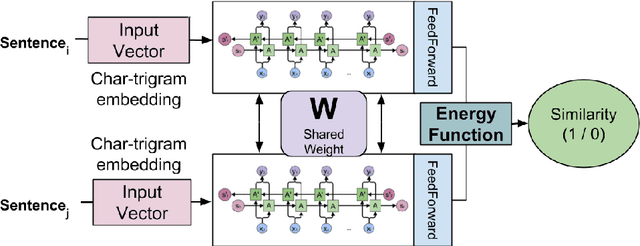

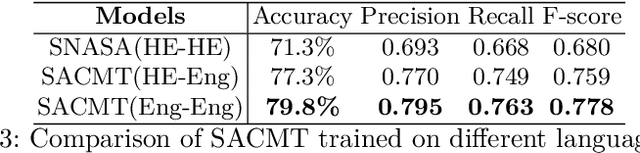
Code-mixed data is an important challenge of natural language processing because its characteristics completely vary from the traditional structures of standard languages. In this paper, we propose a novel approach called Sentiment Analysis of Code-Mixed Text (SACMT) to classify sentences into their corresponding sentiment - positive, negative or neutral, using contrastive learning. We utilize the shared parameters of siamese networks to map the sentences of code-mixed and standard languages to a common sentiment space. Also, we introduce a basic clustering based preprocessing method to capture variations of code-mixed transliterated words. Our experiments reveal that SACMT outperforms the state-of-the-art approaches in sentiment analysis for code-mixed text by 7.6% in accuracy and 10.1% in F-score.