 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of Black Box NLP Models: A Survey
Mar 31, 2022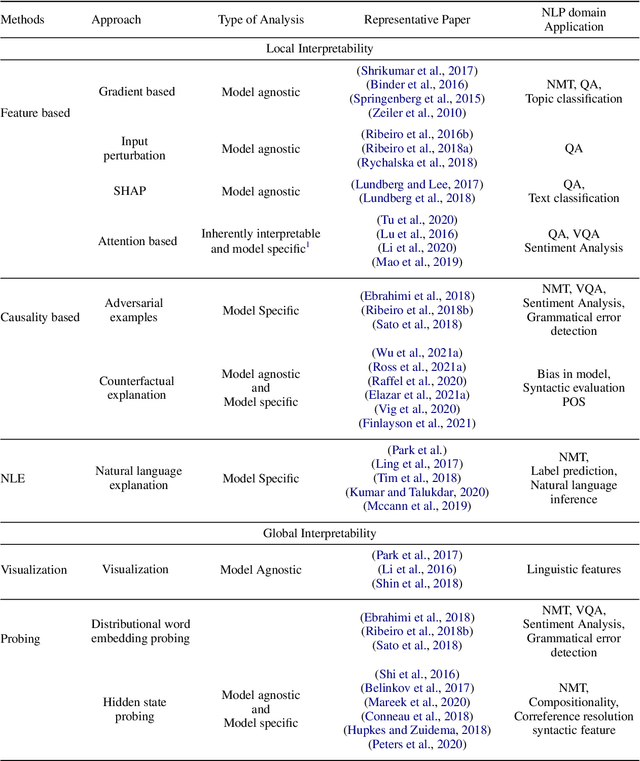

An increasing number of machine learning models have been deployed in domains with high stakes such as finance and healthcare. Despite their superior performances, many models are black boxes in nature which are hard to explain. There are growing efforts for researchers to develop methods to interpret these black-box models. Post hoc explanations based on perturbations, such as LIME, are widely used approaches to interpret a machine learning model after it has been built. This class of methods has been shown to exhibit large instability, posing serious challenges to the effectiveness of the method itself and harming user trust. In this paper, we propose S-LIME, which utilizes a hypothesis testing framework based on central limit theorem for determining the number of perturbation points needed to guarantee stability of the resulting explanation. Experiments on both simulated and real world data sets are provided to demonstrate the effectiveness of our method.
IITD-DBAI: Multi-Stage Retrieval with Pseudo-Relevance Feedback and Query Reformulation
Mar 31, 2022
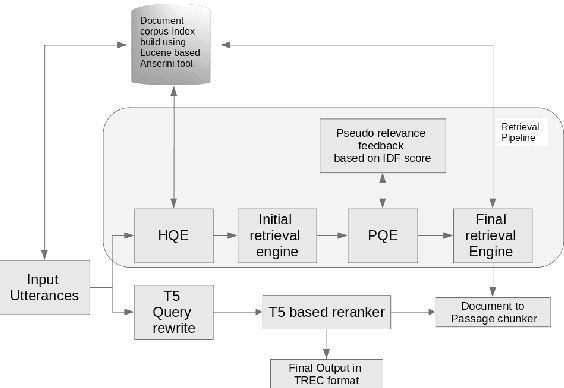

Resolving the contextual dependency is one of the most challenging tasks in the Conversational system. Our submission to CAsT-2021 aimed to preserve the key terms and the context in all subsequent turns and use classical Information retrieval methods. It was aimed to pull as relevant documents as possible from the corpus. We have participated in automatic track and submitted two runs in the CAsT-2021. Our submission has produced a mean NDCG@3 performance better than the median model.
A Survey of Knowledge Graph Embedding and Their Applications
Jul 16, 2021
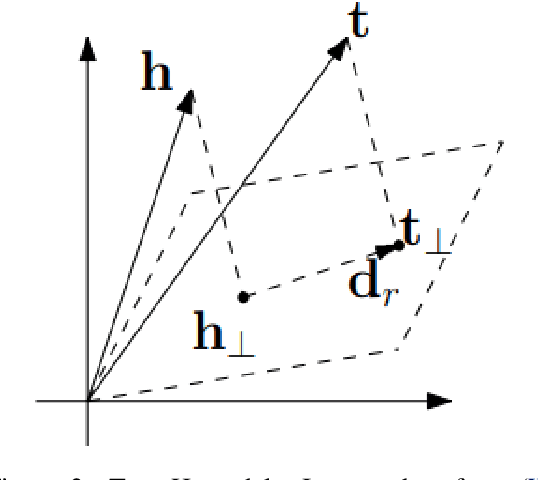
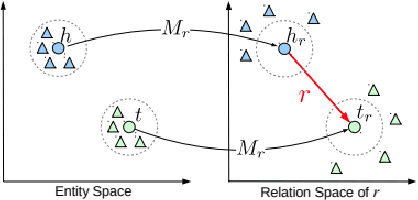
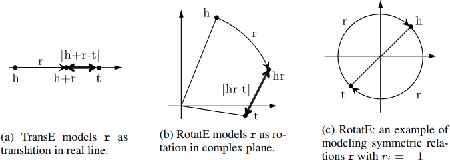
Knowledge Graph embedding provides a versatile technique for representing knowledge. These techniques can be used in a variety of applications such as completion of knowledge graph to predict missing information, recommender systems, question answering, query expansion, etc. The information embedded in Knowledge graph though being structured is challenging to consume in a real-world application. Knowledge graph embedding enables the real-world application to consume information to improve performance. Knowledge graph embedding is an active research area. Most of the embedding methods focus on structure-based information. Recent research has extended the boundary to include text-based information and image-based information in entity embedding. Efforts have been made to enhance the representation with context information. This paper introduces growth in the field of KG embedding from simple translation-based models to enrichment-based models. This paper includes the utility of the Knowledge graph in real-world applications.