Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITD-DBAI: Multi-Stage Retrieval with Pseudo-Relevance Feedback and Query Reformulation
Paper and Code

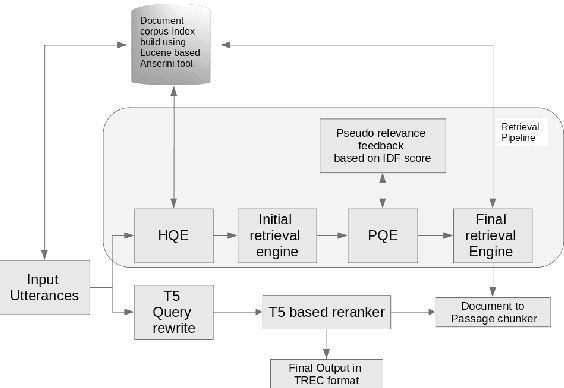

Resolving the contextual dependency is one of the most challenging tasks in the Conversational system. Our submission to CAsT-2021 aimed to preserve the key terms and the context in all subsequent turns and use classical Information retrieval methods. It was aimed to pull as relevant documents as possible from the corpus. We have participated in automatic track and submitted two runs in the CAsT-2021. Our submission has produced a mean NDCG@3 performance better than the median model.
View paper on