 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of (Hidden) Emotions from Videos using Muscles Movements and Face Manifold Embedding
Paper and Code
Nov 01, 2022
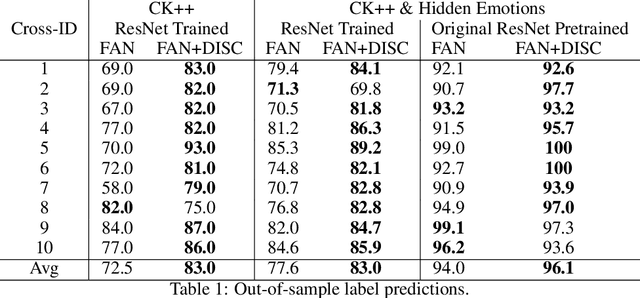
We provide a new non-invasive, easy-to-scale for large amounts of subjects and a remotely accessible method for (hidden) emotion detection from videos of human faces. Our approach combines face manifold detection for accurate location of the face in the video with local face manifold embedding to create a common domain for the measurements of muscle micro-movements that is invariant to the movement of the subject in the video. In the next step, we employ the Digital Image Speckle Correlation (DISC) and the optical flow algorithm to compute the pattern of micro-movements in the face. The corresponding vector field is mapped back to the original space and superimposed on the original frames of the videos. Hence, the resulting videos include additional information about the direction of the movement of the muscles in the face. We take the publicly available CK++ dataset of visible emotions and add to it videos of the same format but with hidden emotions. We process all the videos using our micro-movement detection and use the results to train a state-of-the-art network for emotions classification from videos -- Frame Attention Network (FAN). Although the original FAN model achieves very high out-of-sample performance on the original CK++ videos, it does not perform so well on hidden emotions videos. The performance improves significantly when the model is trained and tested on videos with the vector fields of muscle movements. Intuitively, the corresponding arrows serve as edges in the image that are easily captured by the convolutions filters in the FAN network.