 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEva: A General Vectorized Approximation Framework for Second-order Optimization
Paper and Code
Aug 04, 2023


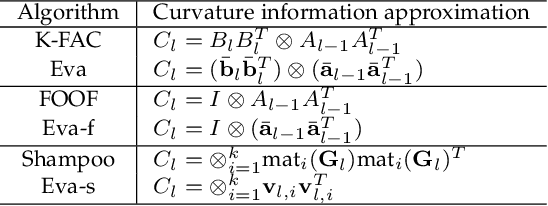
Second-order optimization algorithms exhibit excellent convergence properties for training deep learning models, but often incur significant computation and memory overheads. This can result in lower training efficiency than the first-order counterparts such as stochastic gradient descent (SGD). In this work, we present a memory- and time-efficient second-order algorithm named Eva with two novel techniques: 1) we construct the second-order information with the Kronecker factorization of small stochastic vectors over a mini-batch of training data to reduce memory consumption, and 2) we derive an efficient update formula without explicitly computing the inverse of matrices using the Sherman-Morrison formula. We further extend Eva to a general vectorized approximation framework to improve the compute and memory efficiency of two existing second-order algorithms (FOOF and Shampoo) without affecting their convergence performance. Extensive experimental results on different models and datasets show that Eva reduces the end-to-end training time up to 2.05x and 2.42x compared to first-order SGD and second-order algorithms (K-FAC and Shampoo), respectively.