 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020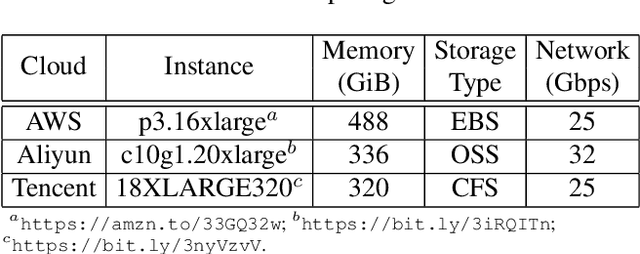
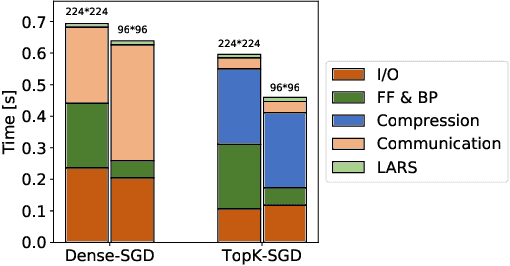
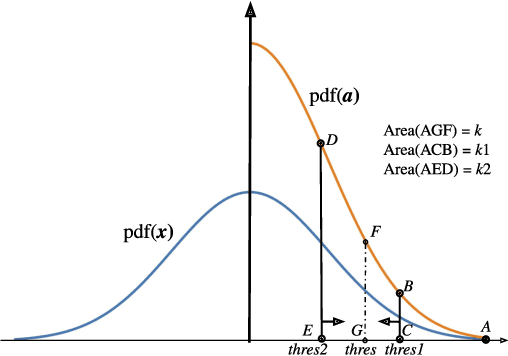
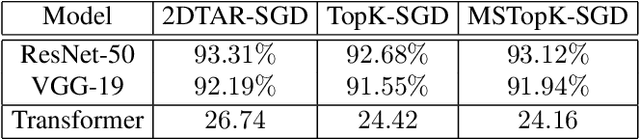
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
Jul 30, 2018
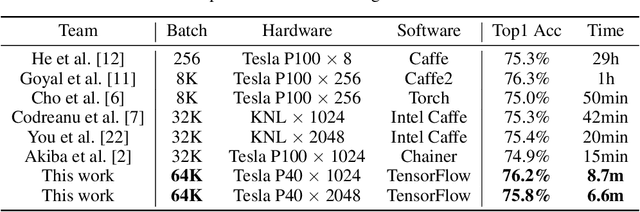

Synchronized stochastic gradient descent (SGD) optimizers with data parallelism are widely used in training large-scale deep neural networks. Although using larger mini-batch sizes can improve the system scalability by reducing the communication-to-computation ratio, it may hurt the generalization ability of the models. To this end, we build a highly scalable deep learning training system for dense GPU clusters with three main contributions: (1) We propose a mixed-precision training method that significantly improves the training throughput of a single GPU without losing accuracy. (2) We propose an optimization approach for extremely large mini-batch size (up to 64k) that can train CNN models on the ImageNet dataset without losing accuracy. (3) We propose highly optimized all-reduce algorithms that achieve up to 3x and 11x speedup on AlexNet and ResNet-50 respectively than NCCL-based training on a cluster with 1024 Tesla P40 GPUs. On training ResNet-50 with 90 epochs, the state-of-the-art GPU-based system with 1024 Tesla P100 GPUs spent 15 minutes and achieved 74.9\% top-1 test accuracy, and another KNL-based system with 2048 Intel KNLs spent 20 minutes and achieved 75.4\% accuracy. Our training system can achieve 75.8\% top-1 test accuracy in only 6.6 minutes using 2048 Tesla P40 GPUs. When training AlexNet with 95 epochs, our system can achieve 58.7\% top-1 test accuracy within 4 minutes, which also outperforms all other existing systems.