 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
Jan 05, 2026Visual generation is dominated by three paradigms: AutoRegressive (AR), diffusion, and Visual AutoRegressive (VAR) models. Unlike AR and diffusion, VARs operate on heterogeneous input structures across their generation steps, which creates severe asynchronous policy conflicts. This issue becomes particularly acute in reinforcement learning (RL) scenarios, leading to unstable training and suboptimal alignment. To resolve this, we propose a novel framework to enhance Group Relative Policy Optimization (GRPO) by explicitly managing these conflicts. Our method integrates three synergistic components: 1) a stabilizing intermediate reward to guide early-stage generation; 2) a dynamic time-step reweighting scheme for precise credit assignment; and 3) a novel mask propagation algorithm, derived from principles of Reward Feedback Learning (ReFL), designed to isolate optimization effects both spatially and temporally. Our approach demonstrates significant improvements in sample quality and objective alignment over the vanilla GRPO baseline, enabling robust and effective optimization for VAR models.
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
DetailFlow: 1D Coarse-to-Fine Autoregressive Image Generation via Next-Detail Prediction
May 27, 2025This paper presents DetailFlow, a coarse-to-fine 1D autoregressive (AR) image generation method that models images through a novel next-detail prediction strategy. By learning a resolution-aware token sequence supervised with progressively degraded images, DetailFlow enables the generation process to start from the global structure and incrementally refine details. This coarse-to-fine 1D token sequence aligns well with the autoregressive inference mechanism, providing a more natural and efficient way for the AR model to generate complex visual content. Our compact 1D AR model achieves high-quality image synthesis with significantly fewer tokens than previous approaches, i.e. VAR/VQGAN. We further propose a parallel inference mechanism with self-correction that accelerates generation speed by approximately 8x while reducing accumulation sampling error inherent in teacher-forcing supervision. On the ImageNet 256x256 benchmark, our method achieves 2.96 gFID with 128 tokens, outperforming VAR (3.3 FID) and FlexVAR (3.05 FID), which both require 680 tokens in their AR models. Moreover, due to the significantly reduced token count and parallel inference mechanism, our method runs nearly 2x faster inference speed compared to VAR and FlexVAR. Extensive experimental results demonstrate DetailFlow's superior generation quality and efficiency compared to existing state-of-the-art methods.
TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
Dec 04, 2024



We present TokenFlow, a novel unified image tokenizer that bridges the long-standing gap between multimodal understanding and generation. Prior research attempt to employ a single reconstruction-targeted Vector Quantization (VQ) encoder for unifying these two tasks. We observe that understanding and generation require fundamentally different granularities of visual information. This leads to a critical trade-off, particularly compromising performance in multimodal understanding tasks. TokenFlow addresses this challenge through an innovative dual-codebook architecture that decouples semantic and pixel-level feature learning while maintaining their alignment via a shared mapping mechanism. This design enables direct access to both high-level semantic representations crucial for understanding tasks and fine-grained visual features essential for generation through shared indices. Our extensive experiments demonstrate TokenFlow's superiority across multiple dimensions. Leveraging TokenFlow, we demonstrate for the first time that discrete visual input can surpass LLaVA-1.5 13B in understanding performance, achieving a 7.2\% average improvement. For image reconstruction, we achieve a strong FID score of 0.63 at 384*384 resolution. Moreover, TokenFlow establishes state-of-the-art performance in autoregressive image generation with a GenEval score of 0.55 at 256*256 resolution, achieving comparable results to SDXL.
Towards Unsupervised Eye-Region Segmentation for Eye Tracking
Oct 08, 2024



Finding the eye and parsing out the parts (e.g. pupil and iris) is a key prerequisite for image-based eye tracking, which has become an indispensable module in today's head-mounted VR/AR devices. However, a typical route for training a segmenter requires tedious handlabeling. In this work, we explore an unsupervised way. First, we utilize priors of human eye and extract signals from the image to establish rough clues indicating the eye-region structure. Upon these sparse and noisy clues, a segmentation network is trained to gradually identify the precise area for each part. To achieve accurate parsing of the eye-region, we first leverage the pretrained foundation model Segment Anything (SAM) in an automatic way to refine the eye indications. Then, the learning process is designed in an end-to-end manner following progressive and prior-aware principle. Experiments show that our unsupervised approach can easily achieve 90% (the pupil and iris) and 85% (the whole eye-region) of the performances under supervised learning.
CondSeg: Ellipse Estimation of Pupil and Iris via Conditioned Segmentation
Aug 30, 2024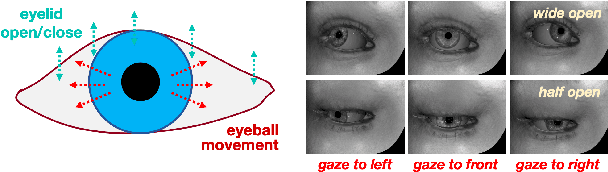

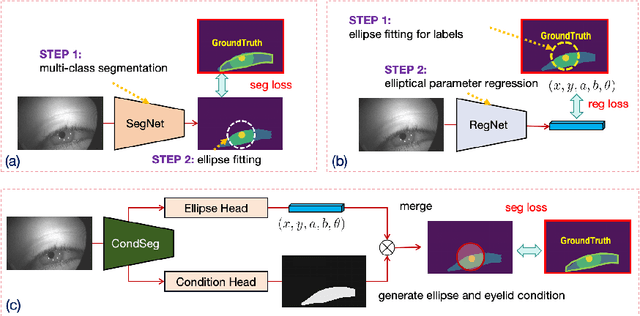

Parsing of eye components (i.e. pupil, iris and sclera) is fundamental for eye tracking and gaze estimation for AR/VR products. Mainstream approaches tackle this problem as a multi-class segmentation task, providing only visible part of pupil/iris, other methods regress elliptical parameters using human-annotated full pupil/iris parameters. In this paper, we consider two priors: projected full pupil/iris circle can be modelled with ellipses (ellipse prior), and the visibility of pupil/iris is controlled by openness of eye-region (condition prior), and design a novel method CondSeg to estimate elliptical parameters of pupil/iris directly from segmentation labels, without explicitly annotating full ellipses, and use eye-region mask to control the visibility of estimated pupil/iris ellipses. Conditioned segmentation loss is used to optimize the parameters by transforming parameterized ellipses into pixel-wise soft masks in a differentiable way. Our method is tested on public datasets (OpenEDS-2019/-2020) and shows competitive results on segmentation metrics, and provides accurate elliptical parameters for further applications of eye tracking simultaneously.
Dressing in the Wild by Watching Dance Videos
Mar 29, 2022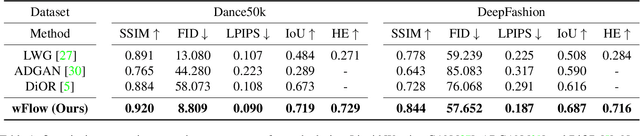
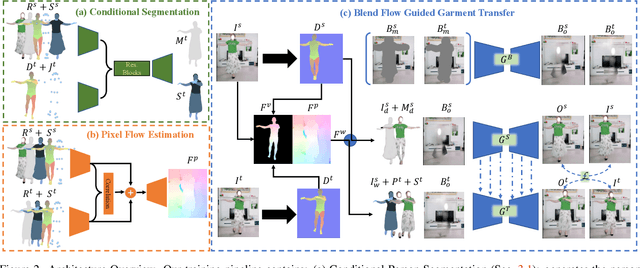
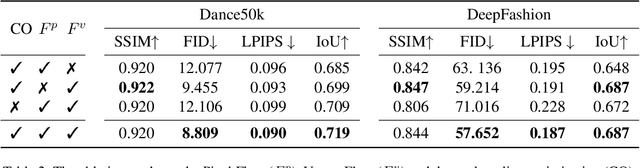
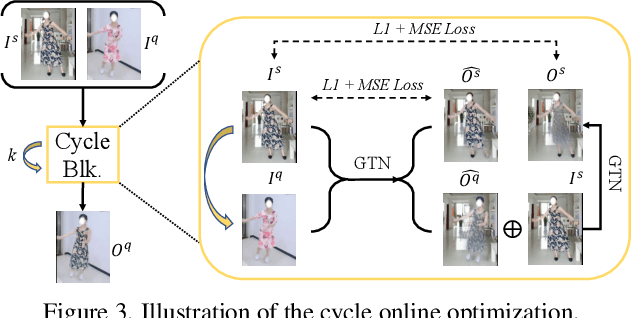
While significant progress has been made in garment transfer, one of the most applicable directions of human-centric image generation, existing works overlook the in-the-wild imagery, presenting severe garment-person misalignment as well as noticeable degradation in fine texture details. This paper, therefore, attends to virtual try-on in real-world scenes and brings essential improvements in authenticity and naturalness especially for loose garment (e.g., skirts, formal dresses), challenging poses (e.g., cross arms, bent legs), and cluttered backgrounds. Specifically, we find that the pixel flow excels at handling loose garments whereas the vertex flow is preferred for hard poses, and by combining their advantages we propose a novel generative network called wFlow that can effectively push up garment transfer to in-the-wild context. Moreover, former approaches require paired images for training. Instead, we cut down the laboriousness by working on a newly constructed large-scale video dataset named Dance50k with self-supervised cross-frame training and an online cycle optimization. The proposed Dance50k can boost real-world virtual dressing by covering a wide variety of garments under dancing poses. Extensive experiments demonstrate the superiority of our wFlow in generating realistic garment transfer results for in-the-wild images without resorting to expensive paired datasets.
PyramidBox: A Context-assisted Single Shot Face Detector
Aug 17, 2018
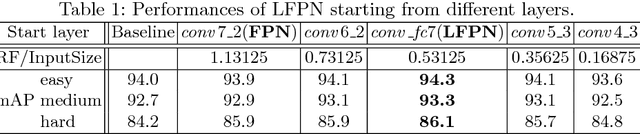
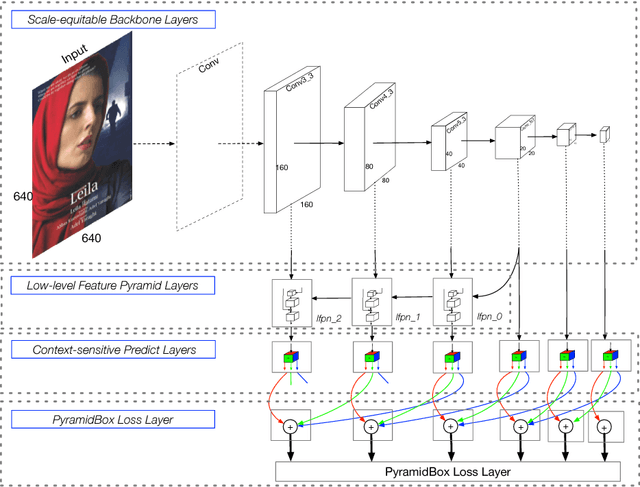
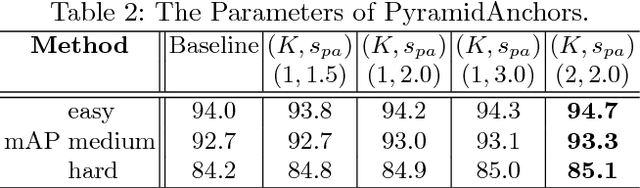
Face detection has been well studied for many years and one of remaining challenges is to detect small, blurred and partially occluded faces in uncontrolled environment. This paper proposes a novel context-assisted single shot face detector, named \emph{PyramidBox} to handle the hard face detection problem. Observing the importance of the context, we improve the utilization of contextual information in the following three aspects. First, we design a novel context anchor to supervise high-level contextual feature learning by a semi-supervised method, which we call it PyramidAnchors. Second, we propose the Low-level Feature Pyramid Network to combine adequate high-level context semantic feature and Low-level facial feature together, which also allows the PyramidBox to predict faces of all scales in a single shot. Third, we introduce a context-sensitive structure to increase the capacity of prediction network to improve the final accuracy of output. In addition, we use the method of Data-anchor-sampling to augment the training samples across different scales, which increases the diversity of training data for smaller faces. By exploiting the value of context, PyramidBox achieves superior performance among the state-of-the-art over the two common face detection benchmarks, FDDB and WIDER FACE. Our code is available in PaddlePaddle: \href{https://github.com/PaddlePaddle/models/tree/develop/fluid/face_detection}{\url{https://github.com/PaddlePaddle/models/tree/develop/fluid/face_detection}}.
* 21 pages, 12 figures