 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectify ViT Shortcut Learning by Visual Saliency
Paper and Code
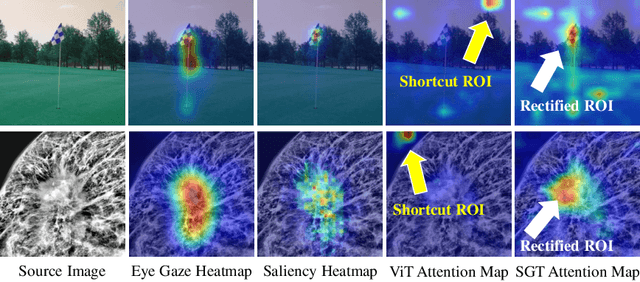

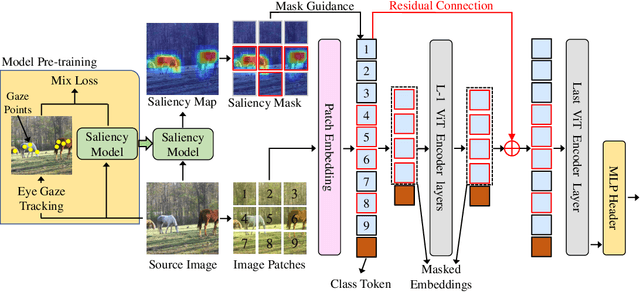

Shortcut learning is common but harmful to deep learning models, leading to degenerated feature representations and consequently jeopardizing the model's generalizability and interpretability. However, shortcut learning in the widely used Vision Transformer framework is largely unknown. Meanwhile, introducing domain-specific knowledge is a major approach to rectifying the shortcuts, which are predominated by background related factors. For example, in the medical imaging field, eye-gaze data from radiologists is an effective human visual prior knowledge that has the great potential to guide the deep learning models to focus on meaningful foreground regions of interest. However, obtaining eye-gaze data is time-consuming, labor-intensive and sometimes even not practical. In this work, we propose a novel and effective saliency-guided vision transformer (SGT) model to rectify shortcut learning in ViT with the absence of eye-gaze data. Specifically, a computational visual saliency model is adopted to predict saliency maps for input image samples. Then, the saliency maps are used to distil the most informative image patches. In the proposed SGT, the self-attention among image patches focus only on the distilled informative ones. Considering this distill operation may lead to global information lost, we further introduce, in the last encoder layer, a residual connection that captures the self-attention across all the image patches. The experiment results on four independent public datasets show that our SGT framework can effectively learn and leverage human prior knowledge without eye gaze data and achieves much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the interpretability of the ViT model, demonstrating the promise of transferring human prior knowledge derived visual saliency in rectifying shortcut learning