 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunduSAM: A Specialized Deep Learning Model for Enhanced Optic Disc and Cup Segmentation in Fundus Images
Feb 10, 2025The Segment Anything Model (SAM) has gained popularity as a versatile image segmentation method, thanks to its strong generalization capabilities across various domains. However, when applied to optic disc (OD) and optic cup (OC) segmentation tasks, SAM encounters challenges due to the complex structures, low contrast, and blurred boundaries typical of fundus images, leading to suboptimal performance. To overcome these challenges, we introduce a novel model, FunduSAM, which incorporates several Adapters into SAM to create a deep network specifically designed for OD and OC segmentation. The FunduSAM utilizes Adapter into each transformer block after encoder for parameter fine-tuning (PEFT). It enhances SAM's feature extraction capabilities by designing a Convolutional Block Attention Module (CBAM), addressing issues related to blurred boundaries and low contrast. Given the unique requirements of OD and OC segmentation, polar transformation is used to convert the original fundus OD images into a format better suited for training and evaluating FunduSAM. A joint loss is used to achieve structure preservation between the OD and OC, while accurate segmentation. Extensive experiments on the REFUGE dataset, comprising 1,200 fundus images, demonstrate the superior performance of FunduSAM compared to five mainstream approaches.
Uniform tensor clustering by jointly exploring sample affinities of various orders
Feb 03, 2023Conventional clustering methods based on pairwise affinity usually suffer from the concentration effect while processing huge dimensional features yet low sample sizes data, resulting in inaccuracy to encode the sample proximity and suboptimal performance in clustering. To address this issue, we propose a unified tensor clustering method (UTC) that characterizes sample proximity using multiple samples' affinity, thereby supplementing rich spatial sample distributions to boost clustering. Specifically, we find that the triadic tensor affinity can be constructed via the Khari-Rao product of two affinity matrices. Furthermore, our early work shows that the fourth-order tensor affinity is defined by the Kronecker product. Therefore, we utilize arithmetical products, Khatri-Rao and Kronecker products, to mathematically integrate different orders of affinity into a unified tensor clustering framework. Thus, the UTC jointly learns a joint low-dimensional embedding to combine various orders. Finally, a numerical scheme is designed to solve the problem. Experiments on synthetic datasets and real-world datasets demonstrate that 1) the usage of high-order tensor affinity could provide a supplementary characterization of sample proximity to the popular affinity matrix; 2) the proposed method of UTC is affirmed to enhance clustering by exploiting different order affinities when processing high-dimensional data.
PGNet: Real-time Arbitrarily-Shaped Text Spotting with Point Gathering Network
Apr 12, 2021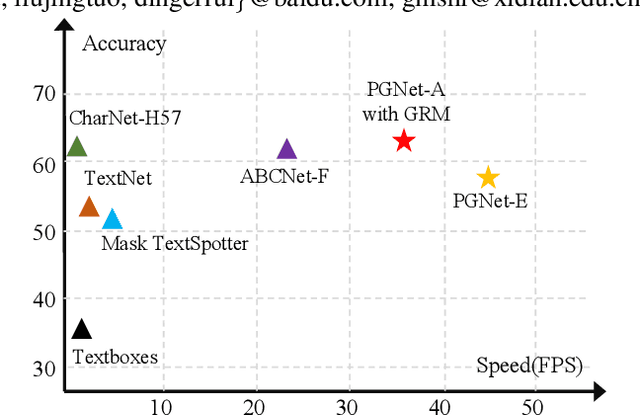
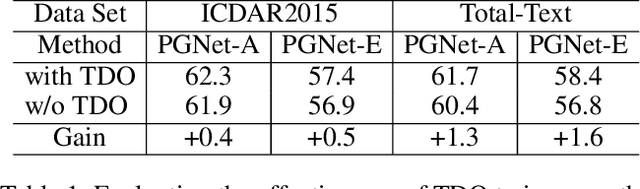
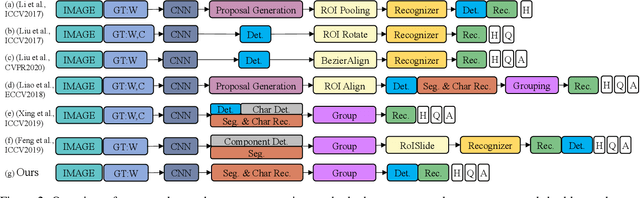
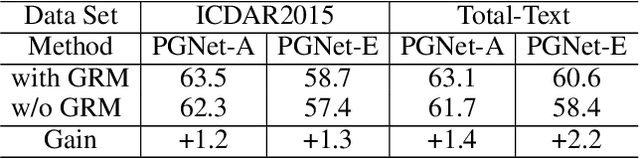
The reading of arbitrarily-shaped text has received increasing research attention. However, existing text spotters are mostly built on two-stage frameworks or character-based methods, which suffer from either Non-Maximum Suppression (NMS), Region-of-Interest (RoI) operations, or character-level annotations. In this paper, to address the above problems, we propose a novel fully convolutional Point Gathering Network (PGNet) for reading arbitrarily-shaped text in real-time. The PGNet is a single-shot text spotter, where the pixel-level character classification map is learned with proposed PG-CTC loss avoiding the usage of character-level annotations. With a PG-CTC decoder, we gather high-level character classification vectors from two-dimensional space and decode them into text symbols without NMS and RoI operations involved, which guarantees high efficiency. Additionally, reasoning the relations between each character and its neighbors, a graph refinement module (GRM) is proposed to optimize the coarse recognition and improve the end-to-end performance. Experiments prove that the proposed method achieves competitive accuracy, meanwhile significantly improving the running speed. In particular, in Total-Text, it runs at 46.7 FPS, surpassing the previous spotters with a large margin.
A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning
Aug 15, 2019



Detecting scene text of arbitrary shapes has been a challenging task over the past years. In this paper, we propose a novel segmentation-based text detector, namely SAST, which employs a context attended multi-task learning framework based on a Fully Convolutional Network (FCN) to learn various geometric properties for the reconstruction of polygonal representation of text regions. Taking sequential characteristics of text into consideration, a Context Attention Block is introduced to capture long-range dependencies of pixel information to obtain a more reliable segmentation. In post-processing, a Point-to-Quad assignment method is proposed to cluster pixels into text instances by integrating both high-level object knowledge and low-level pixel information in a single shot. Moreover, the polygonal representation of arbitrarily-shaped text can be extracted with the proposed geometric properties much more effectively. Experiments on several benchmarks, including ICDAR2015, ICDAR2017-MLT, SCUT-CTW1500, and Total-Text, demonstrate that SAST achieves better or comparable performance in terms of accuracy. Furthermore, the proposed algorithm runs at 27.63 FPS on SCUT-CTW1500 with a Hmean of 81.0% on a single NVIDIA Titan Xp graphics card, surpassing most of the existing segmentation-based methods.
* 9 pages, 6 figures, 7 tables, To appear in ACM Multimedia 2019