 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
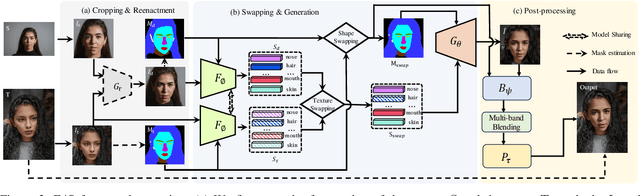
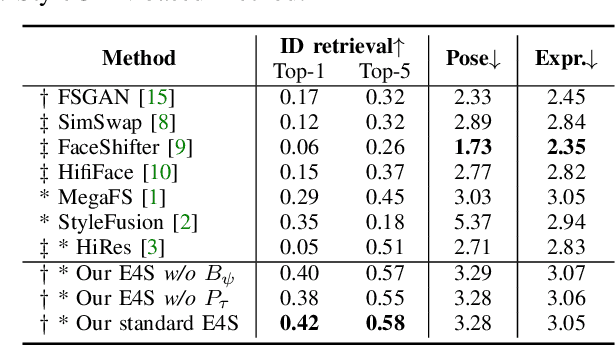
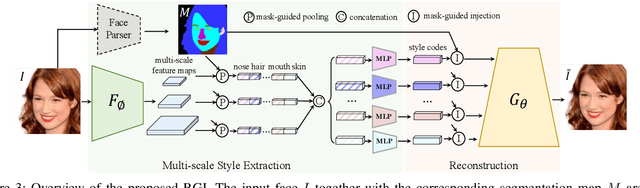
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
Fine-Grained Face Swapping via Regional GAN Inversion
Nov 25, 2022



We present a novel paradigm for high-fidelity face swapping that faithfully preserves the desired subtle geometry and texture details. We rethink face swapping from the perspective of fine-grained face editing, \textit{i.e., ``editing for swapping'' (E4S)}, and propose a framework that is based on the explicit disentanglement of the shape and texture of facial components. Following the E4S principle, our framework enables both global and local swapping of facial features, as well as controlling the amount of partial swapping specified by the user. Furthermore, the E4S paradigm is inherently capable of handling facial occlusions by means of facial masks. At the core of our system lies a novel Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. It also allows face swapping to be performed in the latent space of StyleGAN. Specifically, we design a multi-scale mask-guided encoder to project the texture of each facial component into regional style codes. We also design a mask-guided injection module to manipulate the feature maps with the style codes. Based on the disentanglement, face swapping is reformulated as a simplified problem of style and mask swapping. Extensive experiments and comparisons with current state-of-the-art methods demonstrate the superiority of our approach in preserving texture and shape details, as well as working with high resolution images at 1024$\times$1024.
A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction
Aug 16, 2021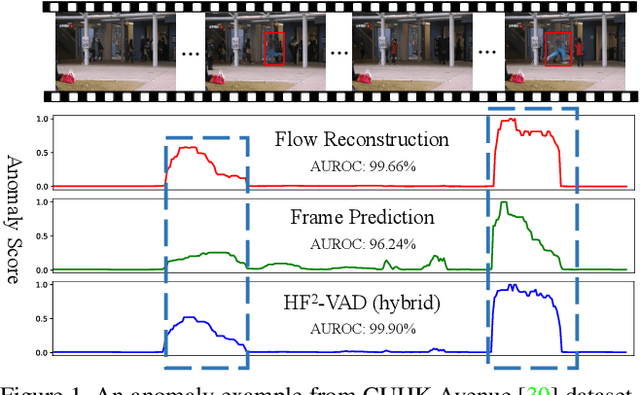
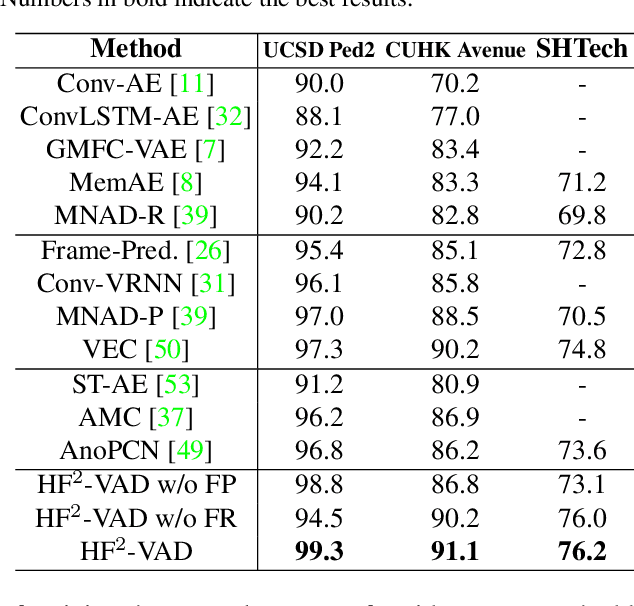
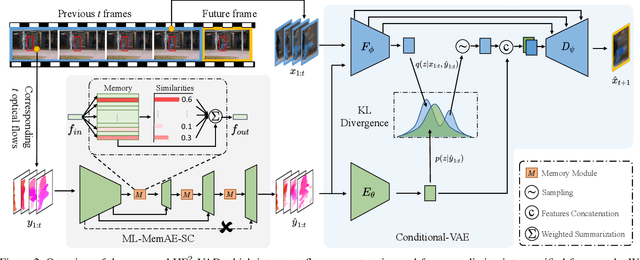
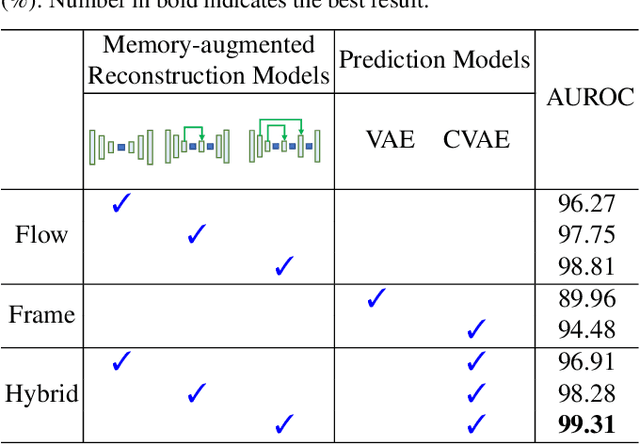
In this paper, we propose $\text{HF}^2$-VAD, a Hybrid framework that integrates Flow reconstruction and Frame prediction seamlessly to handle Video Anomaly Detection. Firstly, we design the network of ML-MemAE-SC (Multi-Level Memory modules in an Autoencoder with Skip Connections) to memorize normal patterns for optical flow reconstruction so that abnormal events can be sensitively identified with larger flow reconstruction errors. More importantly, conditioned on the reconstructed flows, we then employ a Conditional Variational Autoencoder (CVAE), which captures the high correlation between video frame and optical flow, to predict the next frame given several previous frames. By CVAE, the quality of flow reconstruction essentially influences that of frame prediction. Therefore, poorly reconstructed optical flows of abnormal events further deteriorate the quality of the final predicted future frame, making the anomalies more detectable. Experimental results demonstrate the effectiveness of the proposed method. Code is available at \href{https://github.com/LiUzHiAn/hf2vad}{https://github.com/LiUzHiAn/hf2vad}.