 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFREE-Edit: Using Editing-aware Injection in Rectified Flow Models for Zero-shot Image-Driven Video Editing
Mar 01, 2026Image-driven video editing aims to propagate edit contents from the modified first frame to the rest frames. The existing methods usually invert the source video to noise using a pre-trained image-to-video (I2V) model and then guide the sampling process using the edited first frame. Generally, a popular choice for maintaining motion and layout from the source video is intervening in the denoising process by injecting attention during reconstruction. However, such injection often leads to unsatisfactory results, where excessive injection leads to conflicting semantics from the source video while insufficient injection brings limited source representation. Recognizing this, we propose an Editing-awaRE (REE) injection method to modulate injection intensity of each token. Specifically, we first compute the pixel difference between the source and edited first frame to form a corresponding editing mask. Next, we track the editing area throughout the entire video by using optical flow to warp the first-frame mask. Then, editing-aware feature injection intensity for each token is generated accordingly, where injection is not conducted on editing areas. Building upon REE injection, we further propose a zero-shot image-driven video editing framework with recent-emerging rectified-Flow models, dubbed FREE-Edit. Without fine-tuning or training, our FREE-Edit demonstrates effectiveness in various image-driven video editing scenarios, showing its capability to produce higher-quality outputs compared with existing techniques. Project page: https://free-edit.github.io/page/.
OmniCustom: Sync Audio-Video Customization Via Joint Audio-Video Generation Model
Feb 12, 2026Existing mainstream video customization methods focus on generating identity-consistent videos based on given reference images and textual prompts. Benefiting from the rapid advancement of joint audio-video generation, this paper proposes a more compelling new task: sync audio-video customization, which aims to synchronously customize both video identity and audio timbre. Specifically, given a reference image $I^{r}$ and a reference audio $A^{r}$, this novel task requires generating videos that maintain the identity of the reference image while imitating the timbre of the reference audio, with spoken content freely specifiable through user-provided textual prompts. To this end, we propose OmniCustom, a powerful DiT-based audio-video customization framework that can synthesize a video following reference image identity, audio timbre, and text prompts all at once in a zero-shot manner. Our framework is built on three key contributions. First, identity and audio timbre control are achieved through separate reference identity and audio LoRA modules that operate through self-attention layers within the base audio-video generation model. Second, we introduce a contrastive learning objective alongside the standard flow matching objective. It uses predicted flows conditioned on reference inputs as positive examples and those without reference conditions as negative examples, thereby enhancing the model ability to preserve identity and timbre. Third, we train OmniCustom on our constructed large-scale, high-quality audio-visual human dataset. Extensive experiments demonstrate that OmniCustom outperforms existing methods in generating audio-video content with consistent identity and timbre fidelity.
Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning
Jan 11, 2025This paper presents Qffusion, a dual-frame-guided framework for portrait video editing. Specifically, we consider a design principle of ``animation for editing'', and train Qffusion as a general animation framework from two still reference images while we can use it for portrait video editing easily by applying modified start and end frames as references during inference. Leveraging the powerful generative power of Stable Diffusion, we propose a Quadrant-grid Arrangement (QGA) scheme for latent re-arrangement, which arranges the latent codes of two reference images and that of four facial conditions into a four-grid fashion, separately. Then, we fuse features of these two modalities and use self-attention for both appearance and temporal learning, where representations at different times are jointly modeled under QGA. Our Qffusion can achieve stable video editing without additional networks or complex training stages, where only the input format of Stable Diffusion is modified. Further, we propose a Quadrant-grid Propagation (QGP) inference strategy, which enjoys a unique advantage on stable arbitrary-length video generation by processing reference and condition frames recursively. Through extensive experiments, Qffusion consistently outperforms state-of-the-art techniques on portrait video editing.
Exploring Optimal Latent Trajetory for Zero-shot Image Editing
Jan 07, 2025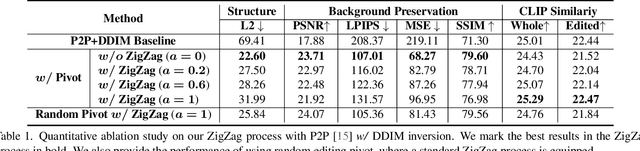
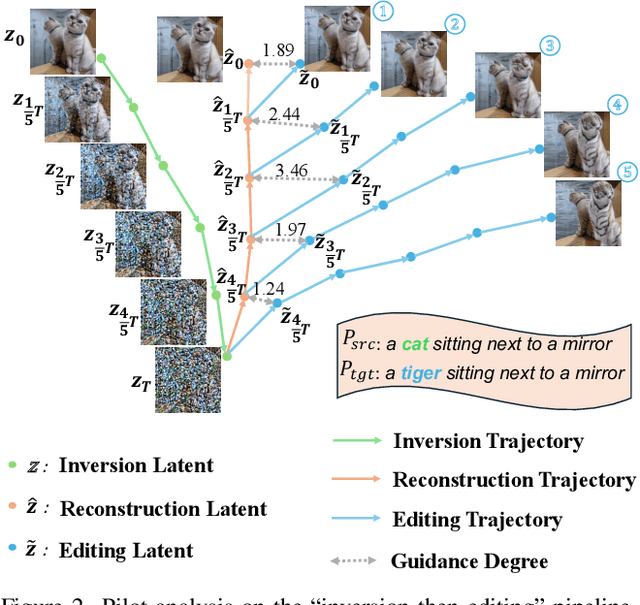
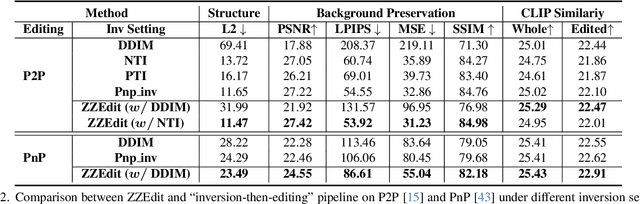
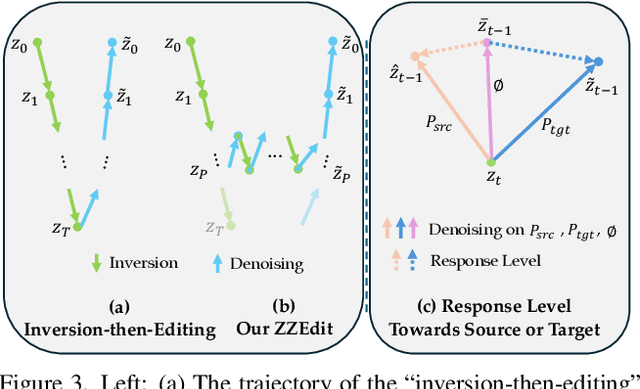
Editability and fidelity are two essential demands for text-driven image editing, which expects that the editing area should align with the target prompt and the rest should remain unchanged separately. The current cutting-edge editing methods usually obey an "inversion-then-editing" pipeline, where the source image is first inverted to an approximate Gaussian noise ${z}_T$, based on which a sampling process is conducted using the target prompt. Nevertheless, we argue that it is not a good choice to use a near-Gaussian noise as a pivot for further editing since it almost lost all structure fidelity. We verify this by a pilot experiment, discovering that some intermediate-inverted latents can achieve a better trade-off between editability and fidelity than the fully-inverted ${z}_T$. Based on this, we propose a novel editing paradigm dubbed ZZEdit, which gentlely strengthens the target guidance on a sufficient-for-editing while structure-preserving latent. Specifically, we locate such an editing pivot by searching the first point on the inversion trajectory which has larger response levels toward the target prompt than the source one. Then, we propose a ZigZag process to perform mild target guiding on this pivot, which fulfills denoising and inversion iteratively, approaching the target while still holding fidelity. Afterwards, to achieve the same number of inversion and denoising steps, we perform a pure sampling process under the target prompt. Extensive experiments highlight the effectiveness of our ZZEdit in diverse image editing scenarios compared with the "inversion-then-editing" pipeline.
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing
Dec 10, 2023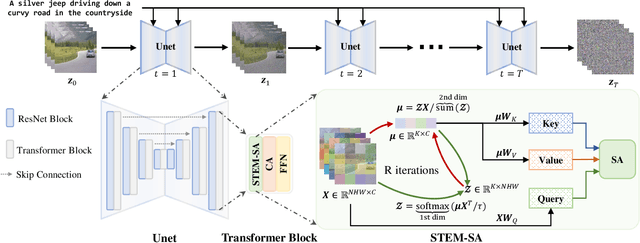
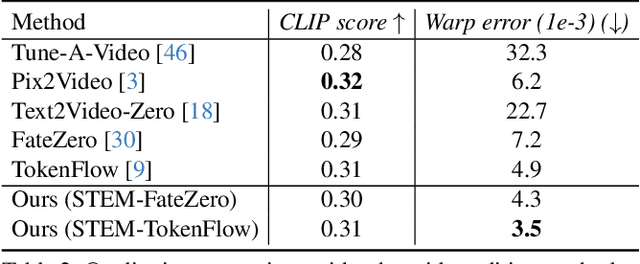


This paper presents a video inversion approach for zero-shot video editing, which aims to model the input video with low-rank representation during the inversion process. The existing video editing methods usually apply the typical 2D DDIM inversion or na\"ive spatial-temporal DDIM inversion before editing, which leverages time-varying representation for each frame to derive noisy latent. Unlike most existing approaches, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion, which formulates the dense video feature under an expectation-maximization manner and iteratively estimates a more compact basis set to represent the whole video. Each frame applies the fixed and global representation for inversion, which is more friendly for temporal consistency during reconstruction and editing. Extensive qualitative and quantitative experiments demonstrate that our STEM inversion can achieve consistent improvement on two state-of-the-art video editing methods.
E4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
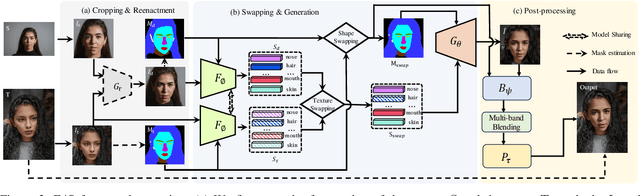
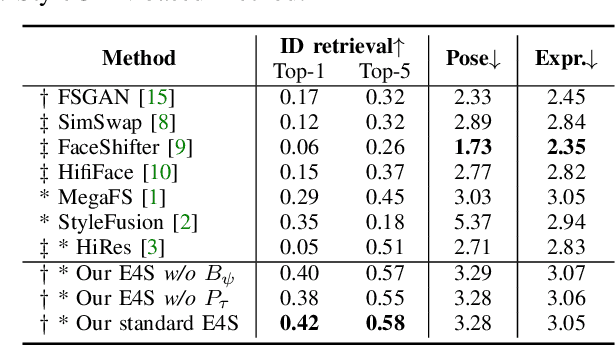
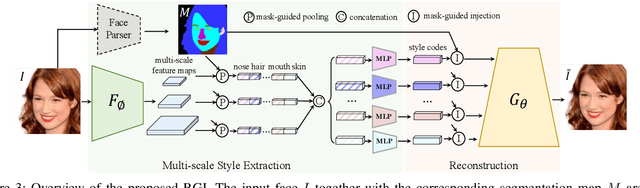
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
ReliableSwap: Boosting General Face Swapping Via Reliable Supervision
Jun 08, 2023Almost all advanced face swapping approaches use reconstruction as the proxy task, i.e., supervision only exists when the target and source belong to the same person. Otherwise, lacking pixel-level supervision, these methods struggle for source identity preservation. This paper proposes to construct reliable supervision, dubbed cycle triplets, which serves as the image-level guidance when the source identity differs from the target one during training. Specifically, we use face reenactment and blending techniques to synthesize the swapped face from real images in advance, where the synthetic face preserves source identity and target attributes. However, there may be some artifacts in such a synthetic face. To avoid the potential artifacts and drive the distribution of the network output close to the natural one, we reversely take synthetic images as input while the real face as reliable supervision during the training stage of face swapping. Besides, we empirically find that the existing methods tend to lose lower-face details like face shape and mouth from the source. This paper additionally designs a FixerNet, providing discriminative embeddings of lower faces as an enhancement. Our face swapping framework, named ReliableSwap, can boost the performance of any existing face swapping network with negligible overhead. Extensive experiments demonstrate the efficacy of our ReliableSwap, especially in identity preservation. The project page is https://reliable-swap.github.io/.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023



Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.
Fine-Grained Face Swapping via Regional GAN Inversion
Nov 25, 2022



We present a novel paradigm for high-fidelity face swapping that faithfully preserves the desired subtle geometry and texture details. We rethink face swapping from the perspective of fine-grained face editing, \textit{i.e., ``editing for swapping'' (E4S)}, and propose a framework that is based on the explicit disentanglement of the shape and texture of facial components. Following the E4S principle, our framework enables both global and local swapping of facial features, as well as controlling the amount of partial swapping specified by the user. Furthermore, the E4S paradigm is inherently capable of handling facial occlusions by means of facial masks. At the core of our system lies a novel Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. It also allows face swapping to be performed in the latent space of StyleGAN. Specifically, we design a multi-scale mask-guided encoder to project the texture of each facial component into regional style codes. We also design a mask-guided injection module to manipulate the feature maps with the style codes. Based on the disentanglement, face swapping is reformulated as a simplified problem of style and mask swapping. Extensive experiments and comparisons with current state-of-the-art methods demonstrate the superiority of our approach in preserving texture and shape details, as well as working with high resolution images at 1024$\times$1024.
SWEM: Towards Real-Time Video Object Segmentation with Sequential Weighted Expectation-Maximization
Aug 22, 2022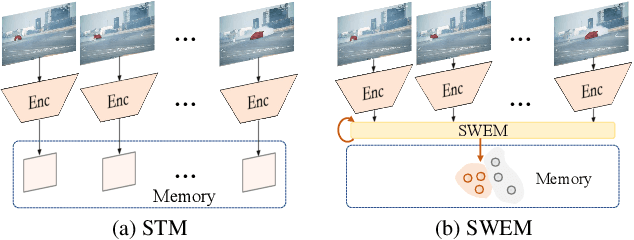
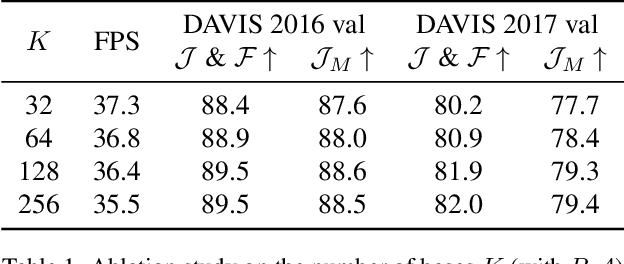
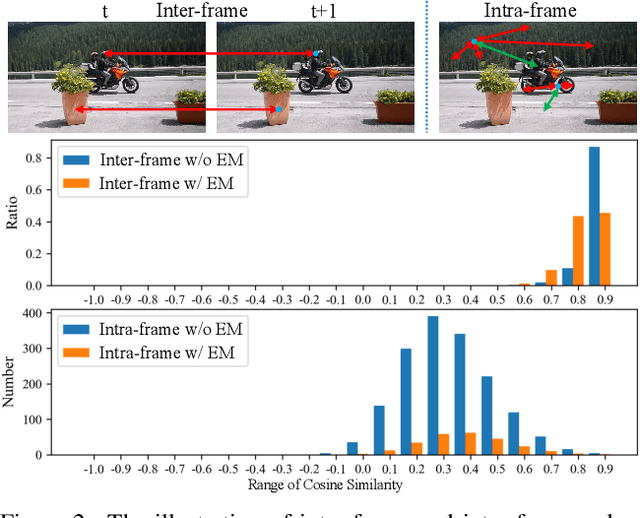
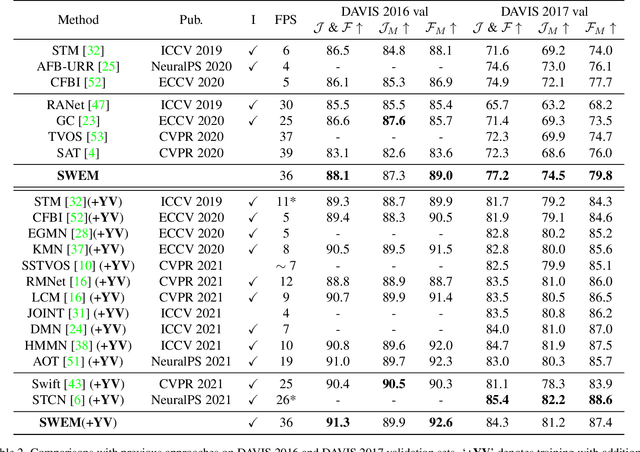
Matching-based methods, especially those based on space-time memory, are significantly ahead of other solutions in semi-supervised video object segmentation (VOS). However, continuously growing and redundant template features lead to an inefficient inference. To alleviate this, we propose a novel Sequential Weighted Expectation-Maximization (SWEM) network to greatly reduce the redundancy of memory features. Different from the previous methods which only detect feature redundancy between frames, SWEM merges both intra-frame and inter-frame similar features by leveraging the sequential weighted EM algorithm. Further, adaptive weights for frame features endow SWEM with the flexibility to represent hard samples, improving the discrimination of templates. Besides, the proposed method maintains a fixed number of template features in memory, which ensures the stable inference complexity of the VOS system. Extensive experiments on commonly used DAVIS and YouTube-VOS datasets verify the high efficiency (36 FPS) and high performance (84.3\% $\mathcal{J}\&\mathcal{F}$ on DAVIS 2017 validation dataset) of SWEM. Code is available at: https://github.com/lmm077/SWEM.
* 15 pages with Supplementary Material