 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing
Dec 10, 2023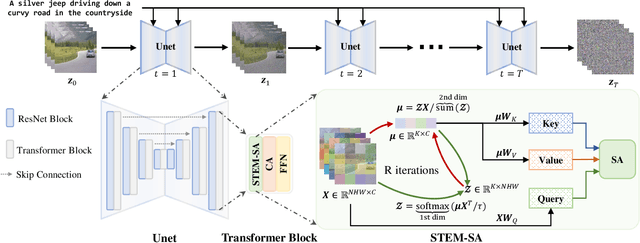


This paper presents a video inversion approach for zero-shot video editing, which aims to model the input video with low-rank representation during the inversion process. The existing video editing methods usually apply the typical 2D DDIM inversion or na\"ive spatial-temporal DDIM inversion before editing, which leverages time-varying representation for each frame to derive noisy latent. Unlike most existing approaches, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion, which formulates the dense video feature under an expectation-maximization manner and iteratively estimates a more compact basis set to represent the whole video. Each frame applies the fixed and global representation for inversion, which is more friendly for temporal consistency during reconstruction and editing. Extensive qualitative and quantitative experiments demonstrate that our STEM inversion can achieve consistent improvement on two state-of-the-art video editing methods.
SWEM: Towards Real-Time Video Object Segmentation with Sequential Weighted Expectation-Maximization
Aug 22, 2022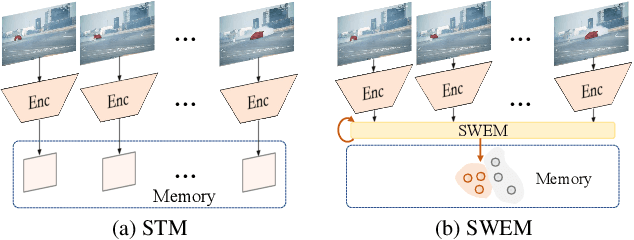
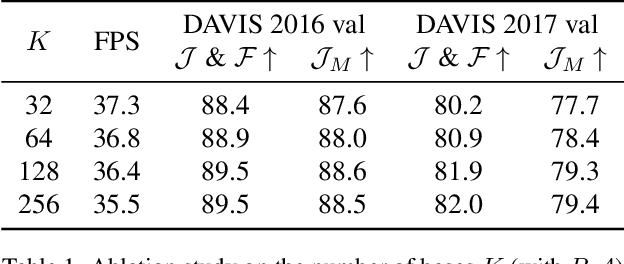
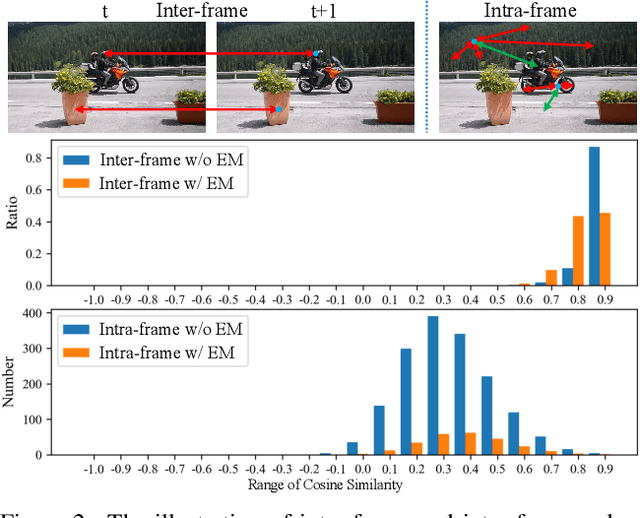
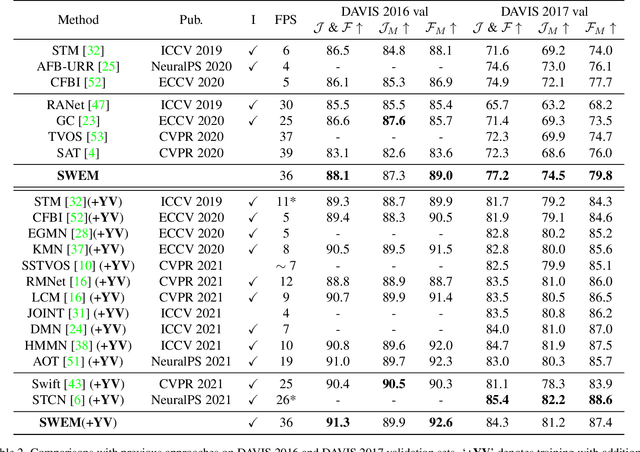
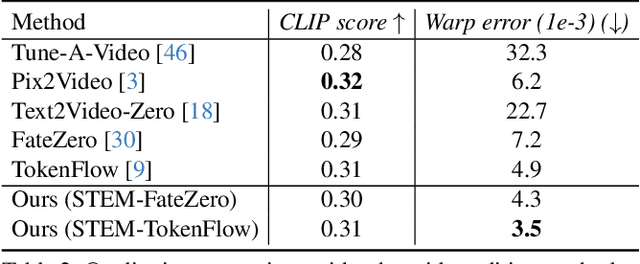
Matching-based methods, especially those based on space-time memory, are significantly ahead of other solutions in semi-supervised video object segmentation (VOS). However, continuously growing and redundant template features lead to an inefficient inference. To alleviate this, we propose a novel Sequential Weighted Expectation-Maximization (SWEM) network to greatly reduce the redundancy of memory features. Different from the previous methods which only detect feature redundancy between frames, SWEM merges both intra-frame and inter-frame similar features by leveraging the sequential weighted EM algorithm. Further, adaptive weights for frame features endow SWEM with the flexibility to represent hard samples, improving the discrimination of templates. Besides, the proposed method maintains a fixed number of template features in memory, which ensures the stable inference complexity of the VOS system. Extensive experiments on commonly used DAVIS and YouTube-VOS datasets verify the high efficiency (36 FPS) and high performance (84.3\% $\mathcal{J}\&\mathcal{F}$ on DAVIS 2017 validation dataset) of SWEM. Code is available at: https://github.com/lmm077/SWEM.
* 15 pages with Supplementary Material
CMS-LSTM: Context-Embedding and Multi-Scale Spatiotemporal-Expression LSTM for Video Prediction
Feb 06, 2021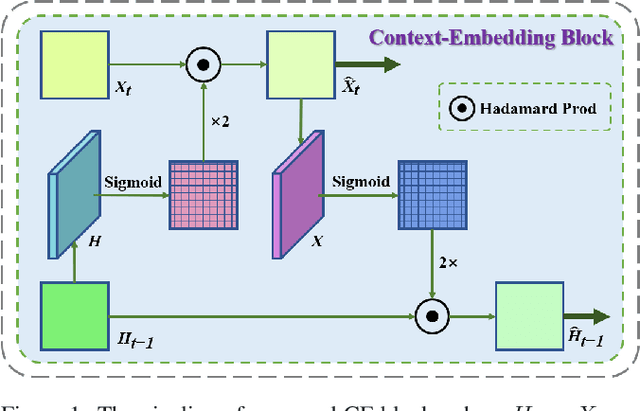
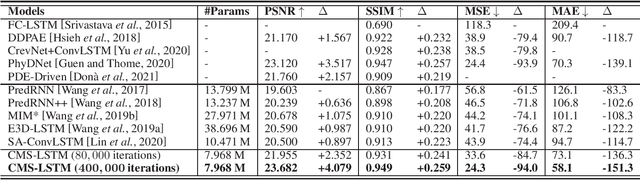
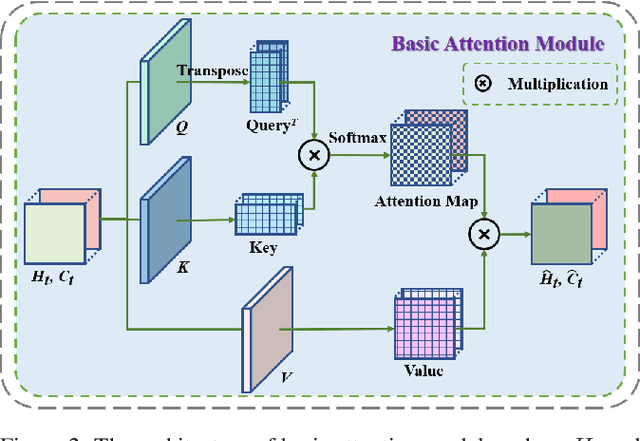

Extracting variation and spatiotemporal features via limited frames remains as an unsolved and challenging problem in video prediction. Inherent uncertainty among consecutive frames exacerbates the difficulty in long-term prediction. To tackle the problem, we focus on capturing context correlations and multi-scale spatiotemporal flows, then propose CMS-LSTM by integrating two effective and lightweight blocks, namely Context-Embedding (CE) and Spatiotemporal-Expression (SE) block, into ConvLSTM backbone. CE block is designed for abundant context interactions, while SE block focuses on multi-scale spatiotemporal expression in hidden states. The newly introduced blocks also facilitate other spatiotemporal models (e.g., PredRNN, SA-ConvLSTM) to produce representative implicit features for video prediction. Qualitative and quantitative experiments demonstrate the effectiveness and flexibility of our proposed method. We use fewer parameters to reach markedly state-of-the-art results on Moving MNIST and TaxiBJ datasets in numbers of metrics. All source code is available at https://github.com/czh-98/CMS-LSTM.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018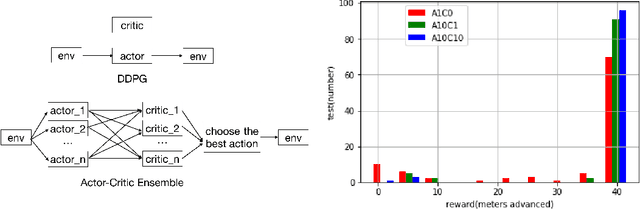

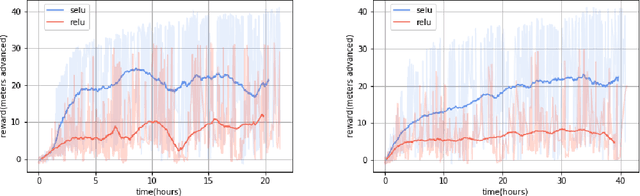
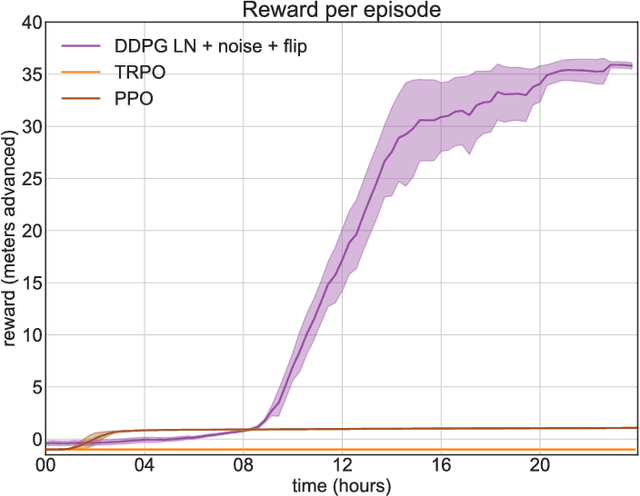
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.