 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMS-LSTM: Context-Embedding and Multi-Scale Spatiotemporal-Expression LSTM for Video Prediction
Paper and Code
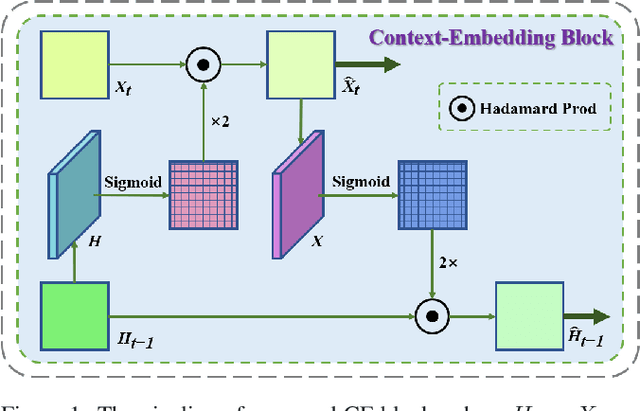
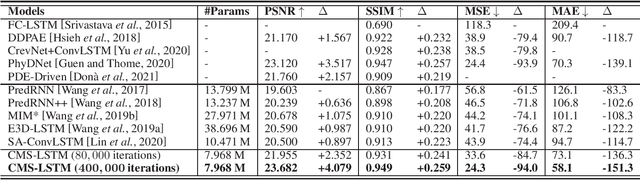
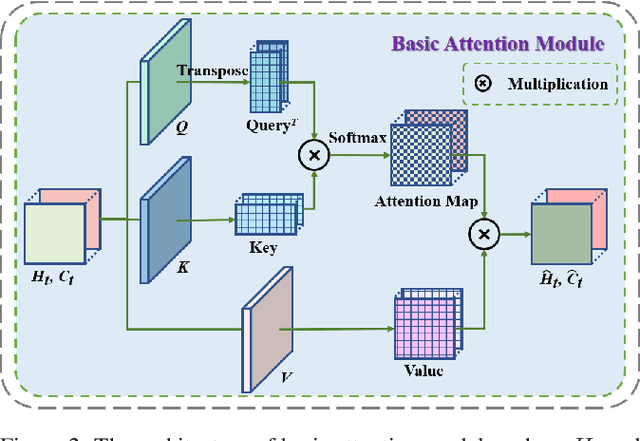

Extracting variation and spatiotemporal features via limited frames remains as an unsolved and challenging problem in video prediction. Inherent uncertainty among consecutive frames exacerbates the difficulty in long-term prediction. To tackle the problem, we focus on capturing context correlations and multi-scale spatiotemporal flows, then propose CMS-LSTM by integrating two effective and lightweight blocks, namely Context-Embedding (CE) and Spatiotemporal-Expression (SE) block, into ConvLSTM backbone. CE block is designed for abundant context interactions, while SE block focuses on multi-scale spatiotemporal expression in hidden states. The newly introduced blocks also facilitate other spatiotemporal models (e.g., PredRNN, SA-ConvLSTM) to produce representative implicit features for video prediction. Qualitative and quantitative experiments demonstrate the effectiveness and flexibility of our proposed method. We use fewer parameters to reach markedly state-of-the-art results on Moving MNIST and TaxiBJ datasets in numbers of metrics. All source code is available at https://github.com/czh-98/CMS-LSTM.