 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMC: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation
Jul 03, 2025Although significant advancements have been achieved in the progress of keypoint-guided Text-to-Image diffusion models, existing mainstream keypoint-guided models encounter challenges in controlling the generation of more general non-rigid objects beyond humans (e.g., animals). Moreover, it is difficult to generate multiple overlapping humans and animals based on keypoint controls solely. These challenges arise from two main aspects: the inherent limitations of existing controllable methods and the lack of suitable datasets. First, we design a DiT-based framework, named UniMC, to explore unifying controllable multi-class image generation. UniMC integrates instance- and keypoint-level conditions into compact tokens, incorporating attributes such as class, bounding box, and keypoint coordinates. This approach overcomes the limitations of previous methods that struggled to distinguish instances and classes due to their reliance on skeleton images as conditions. Second, we propose HAIG-2.9M, a large-scale, high-quality, and diverse dataset designed for keypoint-guided human and animal image generation. HAIG-2.9M includes 786K images with 2.9M instances. This dataset features extensive annotations such as keypoints, bounding boxes, and fine-grained captions for both humans and animals, along with rigorous manual inspection to ensure annotation accuracy. Extensive experiments demonstrate the high quality of HAIG-2.9M and the effectiveness of UniMC, particularly in heavy occlusions and multi-class scenarios.
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing
Dec 10, 2023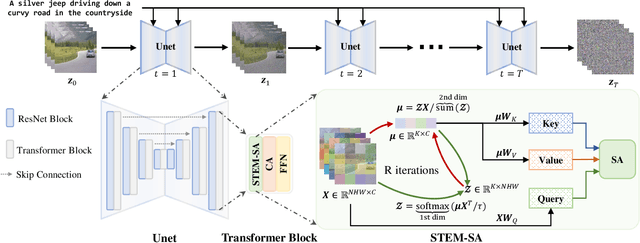
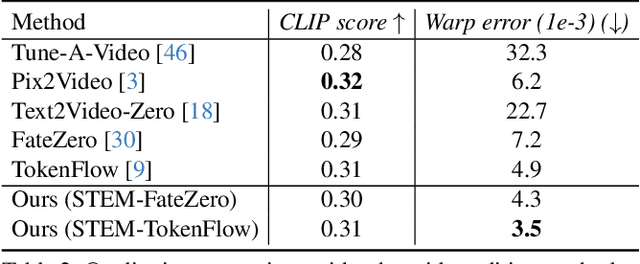


This paper presents a video inversion approach for zero-shot video editing, which aims to model the input video with low-rank representation during the inversion process. The existing video editing methods usually apply the typical 2D DDIM inversion or na\"ive spatial-temporal DDIM inversion before editing, which leverages time-varying representation for each frame to derive noisy latent. Unlike most existing approaches, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion, which formulates the dense video feature under an expectation-maximization manner and iteratively estimates a more compact basis set to represent the whole video. Each frame applies the fixed and global representation for inversion, which is more friendly for temporal consistency during reconstruction and editing. Extensive qualitative and quantitative experiments demonstrate that our STEM inversion can achieve consistent improvement on two state-of-the-art video editing methods.
ChatFace: Chat-Guided Real Face Editing via Diffusion Latent Space Manipulation
May 24, 2023Editing real facial images is a crucial task in computer vision with significant demand in various real-world applications. While GAN-based methods have showed potential in manipulating images especially when combined with CLIP, these methods are limited in their ability to reconstruct real images due to challenging GAN inversion capability. Despite the successful image reconstruction achieved by diffusion-based methods, there are still challenges in effectively manipulating fine-gained facial attributes with textual instructions.To address these issues and facilitate convenient manipulation of real facial images, we propose a novel approach that conduct text-driven image editing in the semantic latent space of diffusion model. By aligning the temporal feature of the diffusion model with the semantic condition at generative process, we introduce a stable manipulation strategy, which perform precise zero-shot manipulation effectively. Furthermore, we develop an interactive system named ChatFace, which combines the zero-shot reasoning ability of large language models to perform efficient manipulations in diffusion semantic latent space. This system enables users to perform complex multi-attribute manipulations through dialogue, opening up new possibilities for interactive image editing. Extensive experiments confirmed that our approach outperforms previous methods and enables precise editing of real facial images, making it a promising candidate for real-world applications. Project page: https://dongxuyue.github.io/chatface/