 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-constrained Hamilton-Jacobi Reachability Learning for Decentralized Multi-Agent Motion Planning
Nov 05, 2025Safe multi-agent motion planning (MAMP) under task-induced constraints is a critical challenge in robotics. Many real-world scenarios require robots to navigate dynamic environments while adhering to manifold constraints imposed by tasks. For example, service robots must carry cups upright while avoiding collisions with humans or other robots. Despite recent advances in decentralized MAMP for high-dimensional systems, incorporating manifold constraints remains difficult. To address this, we propose a manifold-constrained Hamilton-Jacobi reachability (HJR) learning framework for decentralized MAMP. Our method solves HJR problems under manifold constraints to capture task-aware safety conditions, which are then integrated into a decentralized trajectory optimization planner. This enables robots to generate motion plans that are both safe and task-feasible without requiring assumptions about other agents' policies. Our approach generalizes across diverse manifold-constrained tasks and scales effectively to high-dimensional multi-agent manipulation problems. Experiments show that our method outperforms existing constrained motion planners and operates at speeds suitable for real-world applications. Video demonstrations are available at https://youtu.be/RYcEHMnPTH8 .
Reachability-based Trajectory Design via Exact Formulation of Implicit Neural Signed Distance Functions
Mar 18, 2024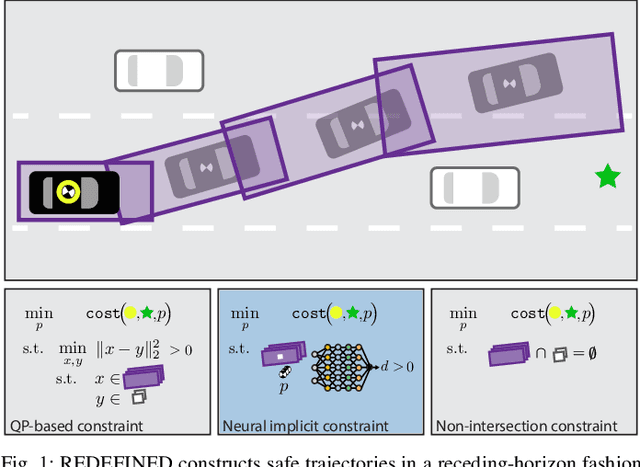
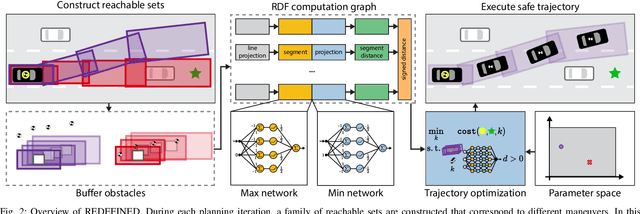
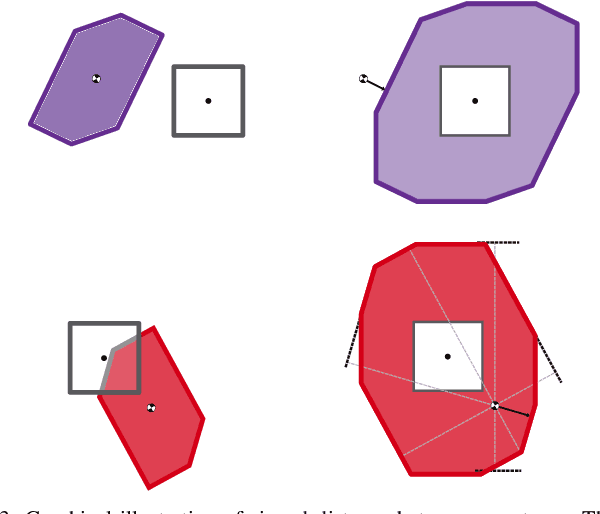
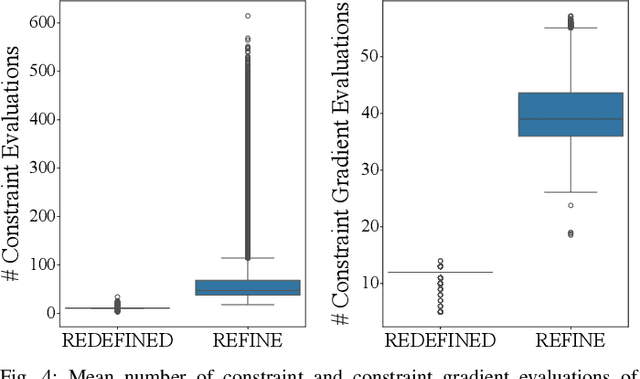
Generating receding-horizon motion trajectories for autonomous vehicles in real-time while also providing safety guarantees is challenging. This is because a future trajectory needs to be planned before the previously computed trajectory is completely executed. This becomes even more difficult if the trajectory is required to satisfy continuous-time collision-avoidance constraints while accounting for a large number of obstacles. To address these challenges, this paper proposes a novel real-time, receding-horizon motion planning algorithm named REachability-based trajectory Design via Exact Formulation of Implicit NEural signed Distance functions (REDEFINED). REDEFINED first applies offline reachability analysis to compute zonotope-based reachable sets that overapproximate the motion of the ego vehicle. During online planning, REDEFINED leverages zonotope arithmetic to construct a neural implicit representation that computes the exact signed distance between a parameterized swept volume of the ego vehicle and obstacle vehicles. REDEFINED then implements a novel, real-time optimization framework that utilizes the neural network to construct a collision avoidance constraint. REDEFINED is compared to a variety of state-of-the-art techniques and is demonstrated to successfully enable the vehicle to safely navigate through complex environments. Code, data, and video demonstrations can be found at https://roahmlab.github.io/redefined/.
Safe Planning for Articulated Robots Using Reachability-based Obstacle Avoidance With Spheres
Feb 13, 2024
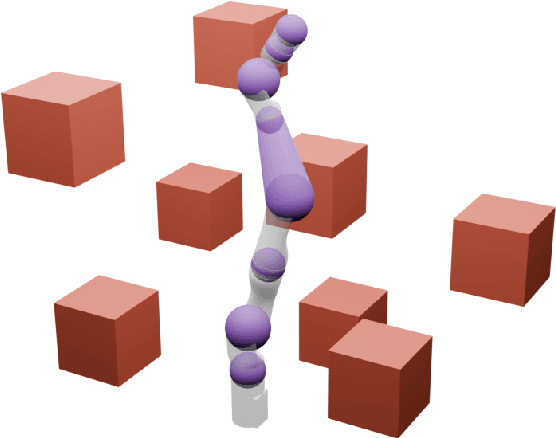
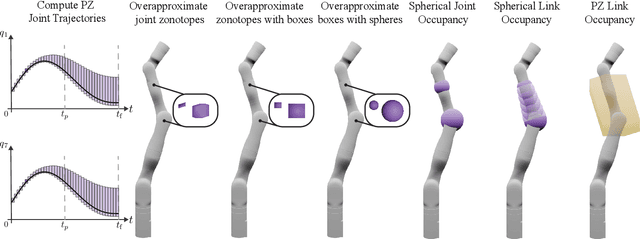
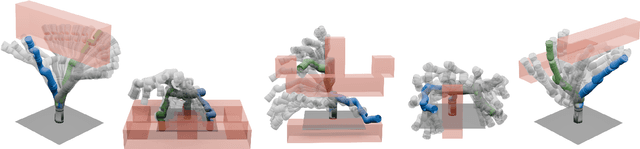
Generating safe motion plans in real-time is necessary for the wide-scale deployment of robots in unstructured and human-centric environments. These motion plans must be safe to ensure humans are not harmed and nearby objects are not damaged. However, they must also be generated in real-time to ensure the robot can quickly adapt to changes in the environment. Many trajectory optimization methods introduce heuristics that trade-off safety and real-time performance, which can lead to potentially unsafe plans. This paper addresses this challenge by proposing Safe Planning for Articulated Robots Using Reachability-based Obstacle Avoidance With Spheres (SPARROWS). SPARROWS is a receding-horizon trajectory planner that utilizes the combination of a novel reachable set representation and an exact signed distance function to generate provably-safe motion plans. At runtime, SPARROWS uses parameterized trajectories to compute reachable sets composed entirely of spheres that overapproximate the swept volume of the robot's motion. SPARROWS then performs trajectory optimization to select a safe trajectory that is guaranteed to be collision-free. We demonstrate that SPARROWS' novel reachable set is significantly less conservative than previous approaches. We also demonstrate that SPARROWS outperforms a variety of state-of-the-art methods in solving challenging motion planning tasks in cluttered environments. Code, data, and video demonstrations can be found at \url{https://roahmlab.github.io/sparrows/}.
Reachability-based Trajectory Design with Neural Implicit Safety Constraints
Feb 14, 2023



Generating safe motion plans in real-time is a key requirement for deploying robot manipulators to assist humans in collaborative settings. In particular, robots must satisfy strict safety requirements to avoid self-damage or harming nearby humans. Satisfying these requirements is particularly challenging if the robot must also operate in real-time to adjust to changes in its environment.This paper addresses these challenges by proposing Reachability-based Signed Distance Functions (RDFs) as a neural implicit representation for robot safety. RDF, which can be constructed using supervised learning in a tractable fashion, accurately predicts the distance between the swept volume of a robot arm and an obstacle. RDF's inference and gradient computations are fast and scale linearly with the dimension of the system; these features enable its use within a novel real-time trajectory planning framework as a continuous-time collision-avoidance constraint. The planning method using RDF is compared to a variety of state-of-the-art techniques and is demonstrated to successfully solve challenging motion planning tasks for high-dimensional systems faster and more reliably than all tested methods.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021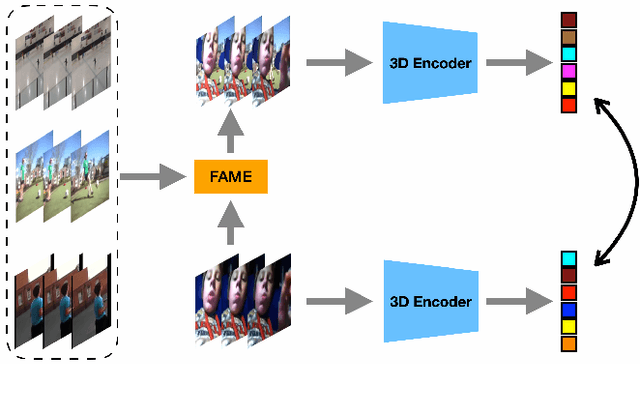
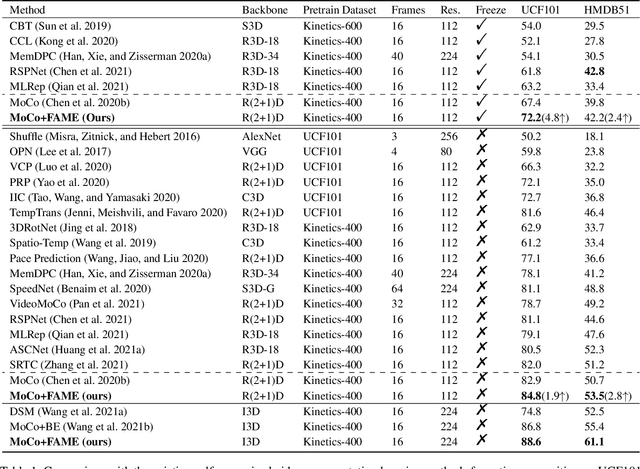


In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.