 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Paper and Code
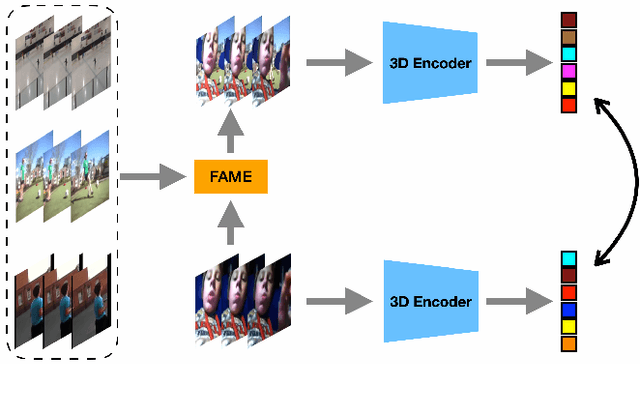
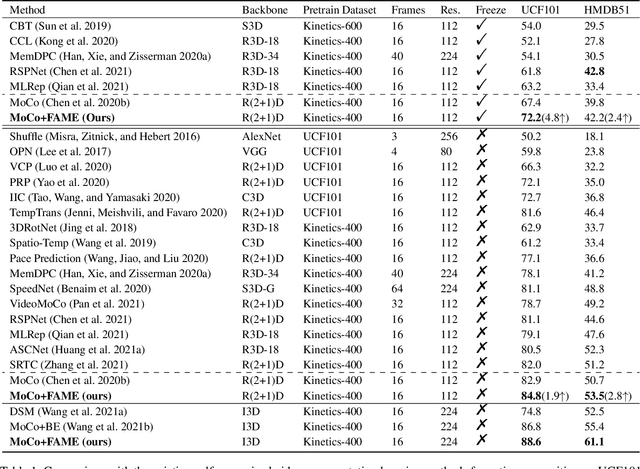


In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.