 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
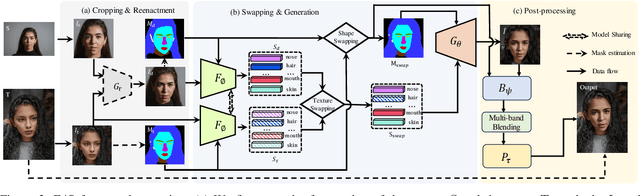
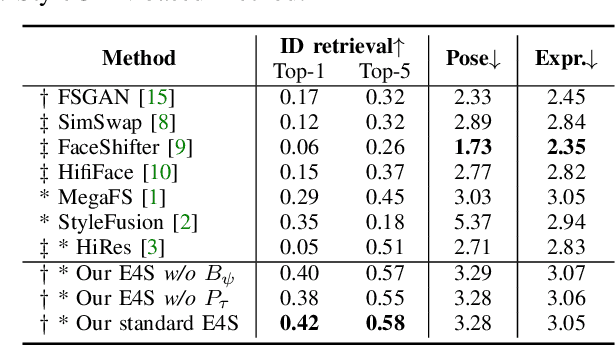
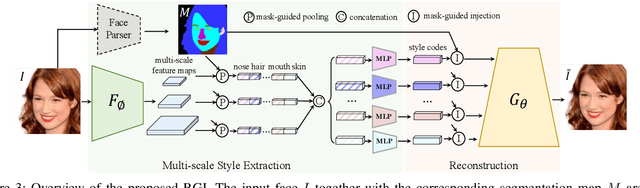
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
ReliableSwap: Boosting General Face Swapping Via Reliable Supervision
Jun 08, 2023Almost all advanced face swapping approaches use reconstruction as the proxy task, i.e., supervision only exists when the target and source belong to the same person. Otherwise, lacking pixel-level supervision, these methods struggle for source identity preservation. This paper proposes to construct reliable supervision, dubbed cycle triplets, which serves as the image-level guidance when the source identity differs from the target one during training. Specifically, we use face reenactment and blending techniques to synthesize the swapped face from real images in advance, where the synthetic face preserves source identity and target attributes. However, there may be some artifacts in such a synthetic face. To avoid the potential artifacts and drive the distribution of the network output close to the natural one, we reversely take synthetic images as input while the real face as reliable supervision during the training stage of face swapping. Besides, we empirically find that the existing methods tend to lose lower-face details like face shape and mouth from the source. This paper additionally designs a FixerNet, providing discriminative embeddings of lower faces as an enhancement. Our face swapping framework, named ReliableSwap, can boost the performance of any existing face swapping network with negligible overhead. Extensive experiments demonstrate the efficacy of our ReliableSwap, especially in identity preservation. The project page is https://reliable-swap.github.io/.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023



Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.