 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
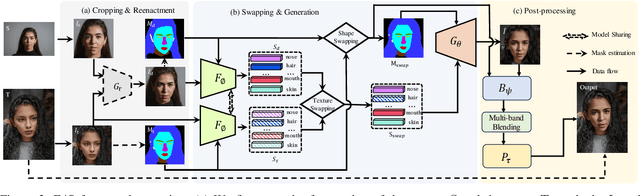
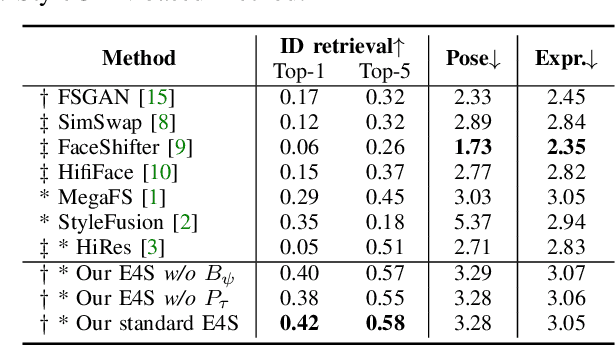
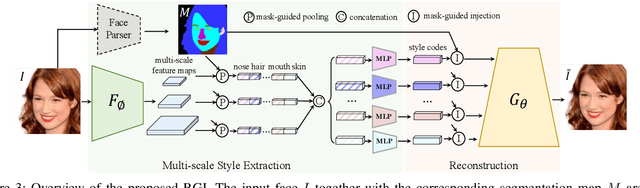
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
TextIR: A Simple Framework for Text-based Editable Image Restoration
Feb 28, 2023
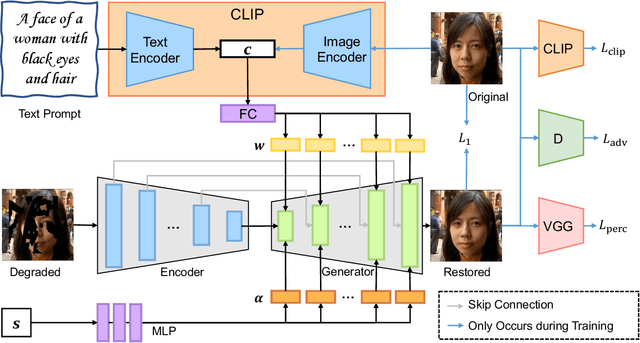
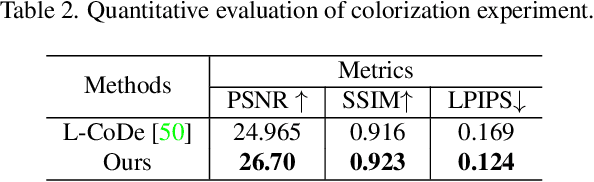

Most existing image restoration methods use neural networks to learn strong image-level priors from huge data to estimate the lost information. However, these works still struggle in cases when images have severe information deficits. Introducing external priors or using reference images to provide information also have limitations in the application domain. In contrast, text input is more readily available and provides information with higher flexibility. In this work, we design an effective framework that allows the user to control the restoration process of degraded images with text descriptions. We use the text-image feature compatibility of the CLIP to alleviate the difficulty of fusing text and image features. Our framework can be used for various image restoration tasks, including image inpainting, image super-resolution, and image colorization. Extensive experiments demonstrate the effectiveness of our method.
Fine-Grained Face Swapping via Regional GAN Inversion
Nov 25, 2022



We present a novel paradigm for high-fidelity face swapping that faithfully preserves the desired subtle geometry and texture details. We rethink face swapping from the perspective of fine-grained face editing, \textit{i.e., ``editing for swapping'' (E4S)}, and propose a framework that is based on the explicit disentanglement of the shape and texture of facial components. Following the E4S principle, our framework enables both global and local swapping of facial features, as well as controlling the amount of partial swapping specified by the user. Furthermore, the E4S paradigm is inherently capable of handling facial occlusions by means of facial masks. At the core of our system lies a novel Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. It also allows face swapping to be performed in the latent space of StyleGAN. Specifically, we design a multi-scale mask-guided encoder to project the texture of each facial component into regional style codes. We also design a mask-guided injection module to manipulate the feature maps with the style codes. Based on the disentanglement, face swapping is reformulated as a simplified problem of style and mask swapping. Extensive experiments and comparisons with current state-of-the-art methods demonstrate the superiority of our approach in preserving texture and shape details, as well as working with high resolution images at 1024$\times$1024.
PS-NeRV: Patch-wise Stylized Neural Representations for Videos
Aug 07, 2022



We study how to represent a video with implicit neural representations (INRs). Classical INRs methods generally utilize MLPs to map input coordinates to output pixels. While some recent works have tried to directly reconstruct the whole image with CNNs. However, we argue that both the above pixel-wise and image-wise strategies are not favorable to video data. Instead, we propose a patch-wise solution, PS-NeRV, which represents videos as a function of patches and the corresponding patch coordinate. It naturally inherits the advantages of image-wise methods, and achieves excellent reconstruction performance with fast decoding speed. The whole method includes conventional modules, like positional embedding, MLPs and CNNs, while also introduces AdaIN to enhance intermediate features. These simple yet essential changes could help the network easily fit high-frequency details. Extensive experiments have demonstrated its effectiveness in several video-related tasks, such as video compression and video inpainting.
Improving the Latent Space of Image Style Transfer
May 24, 2022
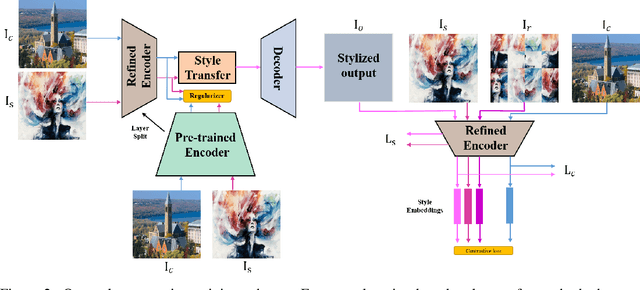
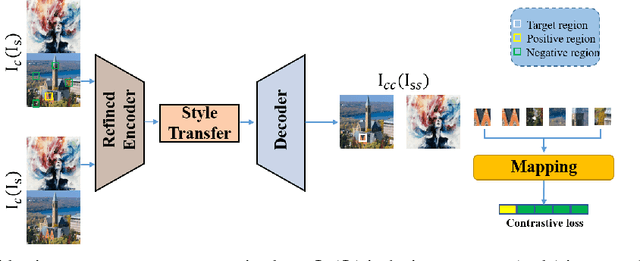

Existing neural style transfer researches have studied to match statistical information between the deep features of content and style images, which were extracted by a pre-trained VGG, and achieved significant improvement in synthesizing artistic images. However, in some cases, the feature statistics from the pre-trained encoder may not be consistent with the visual style we perceived. For example, the style distance between images of different styles is less than that of the same style. In such an inappropriate latent space, the objective function of the existing methods will be optimized in the wrong direction, resulting in bad stylization results. In addition, the lack of content details in the features extracted by the pre-trained encoder also leads to the content leak problem. In order to solve these issues in the latent space used by style transfer, we propose two contrastive training schemes to get a refined encoder that is more suitable for this task. The style contrastive loss pulls the stylized result closer to the same visual style image and pushes it away from the content image. The content contrastive loss enables the encoder to retain more available details. We can directly add our training scheme to some existing style transfer methods and significantly improve their results. Extensive experimental results demonstrate the effectiveness and superiority of our methods.