 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Gradient: PPO with Policy Gradient
Paper and Code
Oct 20, 2020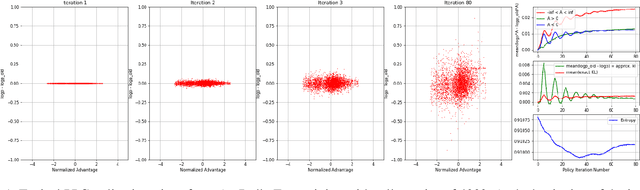
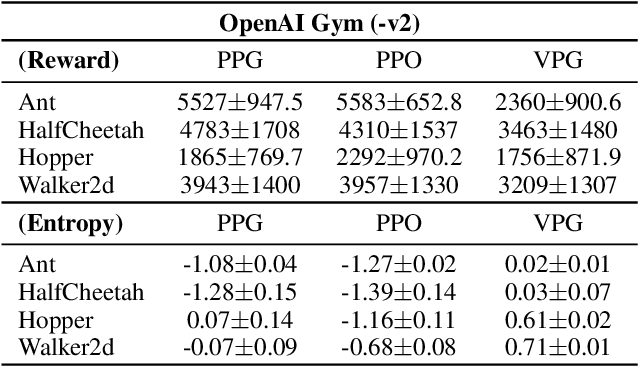
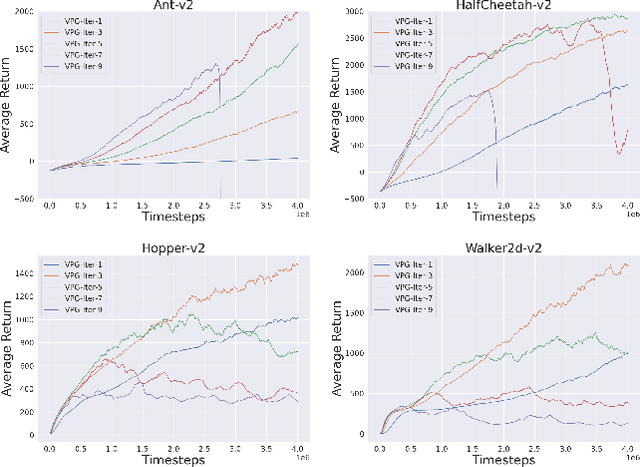
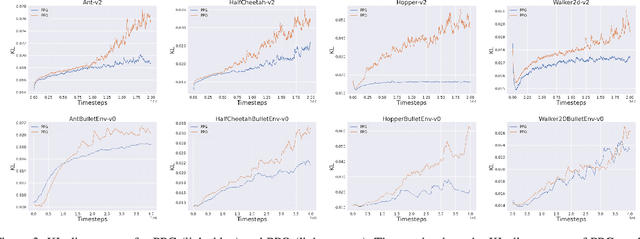
In this paper, we propose a new algorithm PPG (Proximal Policy Gradient), which is close to both VPG (vanilla policy gradient) and PPO (proximal policy optimization). The PPG objective is a partial variation of the VPG objective and the gradient of the PPG objective is exactly same as the gradient of the VPG objective. To increase the number of policy update iterations, we introduce the advantage-policy plane and design a new clipping strategy. We perform experiments in OpenAI Gym and Bullet robotics environments for ten random seeds. The performance of PPG is comparable to PPO, and the entropy decays slower than PPG. Thus we show that performance similar to PPO can be obtained by using the gradient formula from the original policy gradient theorem.