 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs
Dec 08, 2025Rotary Position Embeddings (RoPE) have become a standard for encoding sequence order in Large Language Models (LLMs) by applying rotations to query and key vectors in the complex plane. Standard implementations, however, utilize only the real component of the complex-valued dot product for attention score calculation. This simplification discards the imaginary component, which contains valuable phase information, leading to a potential loss of relational details crucial for modeling long-context dependencies. In this paper, we propose an extension that re-incorporates this discarded imaginary component. Our method leverages the full complex-valued representation to create a dual-component attention score. We theoretically and empirically demonstrate that this approach enhances the modeling of long-context dependencies by preserving more positional information. Furthermore, evaluations on a suite of long-context language modeling benchmarks show that our method consistently improves performance over the standard RoPE, with the benefits becoming more significant as context length increases. The code is available at https://github.com/OpenMOSS/rope_pp.
Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
Jun 13, 2025Large Language Models struggle with memory demands from the growing Key-Value (KV) cache as context lengths increase. Existing compression methods homogenize head dimensions or rely on attention-guided token pruning, often sacrificing accuracy or introducing computational overhead. We propose FourierAttention, a training-free framework that exploits the heterogeneous roles of transformer head dimensions: lower dimensions prioritize local context, while upper ones capture long-range dependencies. By projecting the long-context-insensitive dimensions onto orthogonal Fourier bases, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluations on LLaMA models show that FourierAttention achieves the best long-context accuracy on LongBench and Needle-In-A-Haystack (NIAH). Besides, a custom Triton kernel, FlashFourierAttention, is designed to optimize memory via streamlined read-write operations, enabling efficient deployment without performance compromise.
Thus Spake Long-Context Large Language Model
Feb 24, 2025Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans. Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs. In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality. In this survey, We will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies. At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.
Farewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
Jul 21, 2024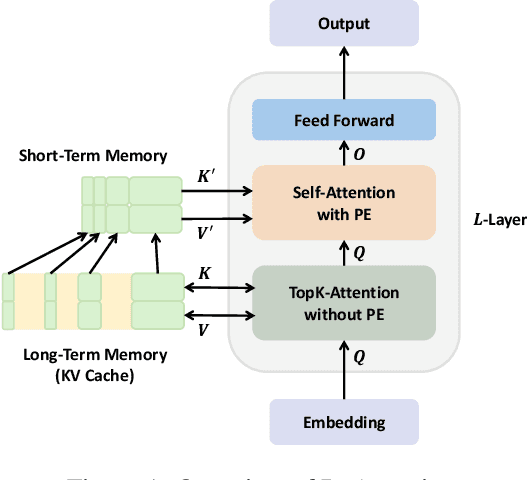

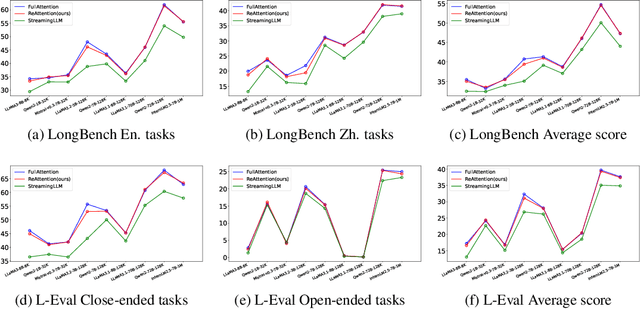
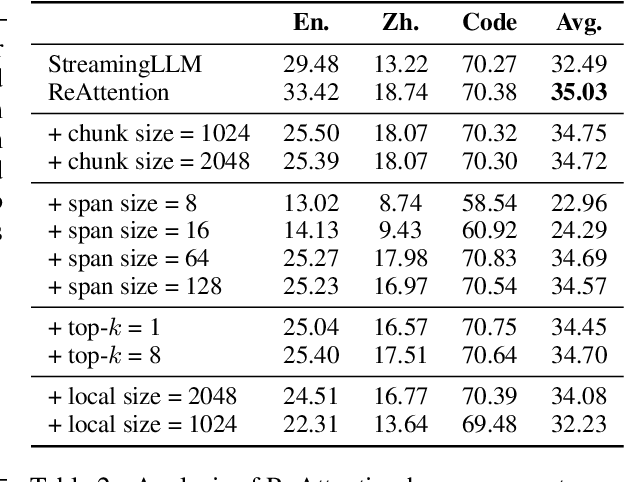
The maximum supported context length is a critical bottleneck limiting the practical application of the Large Language Model (LLM). Although existing length extrapolation methods can extend the context of LLMs to millions of tokens, these methods all have an explicit upper bound. In this work, we propose LongCache, a training-free approach that enables LLM to support an infinite context with finite context scope, through full-context cache selection and training-free integration. This effectively frees LLMs from the length extrapolation issue. We validate LongCache on the LongBench and L-Eval and demonstrate its performance is on par with traditional full-attention mechanisms. Furthermore, we have applied LongCache on mainstream LLMs, including LLaMA3 and Mistral-v0.3, enabling them to support context lengths of at least 400K in Needle-In-A-Haystack tests. We will improve the efficiency of LongCache by GPU-aware optimization soon.