 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
DiRL: An Efficient Post-Training Framework for Diffusion Language Models
Dec 23, 2025Diffusion Language Models (dLLMs) have emerged as promising alternatives to Auto-Regressive (AR) models. While recent efforts have validated their pre-training potential and accelerated inference speeds, the post-training landscape for dLLMs remains underdeveloped. Existing methods suffer from computational inefficiency and objective mismatches between training and inference, severely limiting performance on complex reasoning tasks such as mathematics. To address this, we introduce DiRL, an efficient post-training framework that tightly integrates FlexAttention-accelerated blockwise training with LMDeploy-optimized inference. This architecture enables a streamlined online model update loop, facilitating efficient two-stage post-training (Supervised Fine-Tuning followed by Reinforcement Learning). Building on this framework, we propose DiPO, the first unbiased Group Relative Policy Optimization (GRPO) implementation tailored for dLLMs. We validate our approach by training DiRL-8B-Instruct on high-quality math data. Our model achieves state-of-the-art math performance among dLLMs and surpasses comparable models in the Qwen2.5 series on several benchmarks.
Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
Jun 13, 2025Large Language Models struggle with memory demands from the growing Key-Value (KV) cache as context lengths increase. Existing compression methods homogenize head dimensions or rely on attention-guided token pruning, often sacrificing accuracy or introducing computational overhead. We propose FourierAttention, a training-free framework that exploits the heterogeneous roles of transformer head dimensions: lower dimensions prioritize local context, while upper ones capture long-range dependencies. By projecting the long-context-insensitive dimensions onto orthogonal Fourier bases, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluations on LLaMA models show that FourierAttention achieves the best long-context accuracy on LongBench and Needle-In-A-Haystack (NIAH). Besides, a custom Triton kernel, FlashFourierAttention, is designed to optimize memory via streamlined read-write operations, enabling efficient deployment without performance compromise.
Thus Spake Long-Context Large Language Model
Feb 24, 2025Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans. Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs. In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality. In this survey, We will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies. At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.
CSG: Curriculum Representation Learning for Signed Graph
Oct 17, 2023



Signed graphs are valuable for modeling complex relationships with positive and negative connections, and Signed Graph Neural Networks (SGNNs) have become crucial tools for their analysis. However, prior to our work, no specific training plan existed for SGNNs, and the conventional random sampling approach did not address varying learning difficulties within the graph's structure. We proposed a curriculum-based training approach, where samples progress from easy to complex, inspired by human learning. To measure learning difficulty, we introduced a lightweight mechanism and created the Curriculum representation learning framework for Signed Graphs (CSG). This framework optimizes the order in which samples are presented to the SGNN model. Empirical validation across six real-world datasets showed impressive results, enhancing SGNN model accuracy by up to 23.7% in link sign prediction (AUC) and significantly improving stability with an up to 8.4 reduction in the standard deviation of AUC scores.
DRVC: A Framework of Any-to-Any Voice Conversion with Self-Supervised Learning
Feb 22, 2022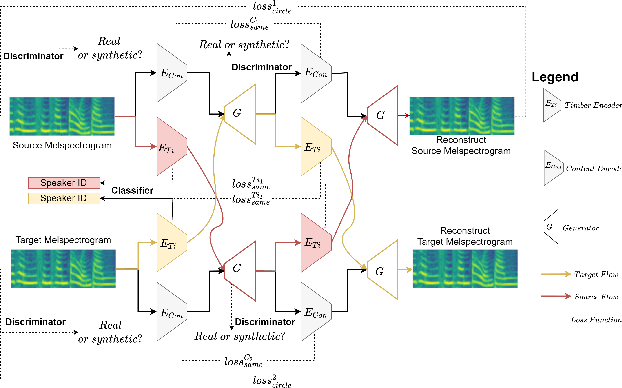
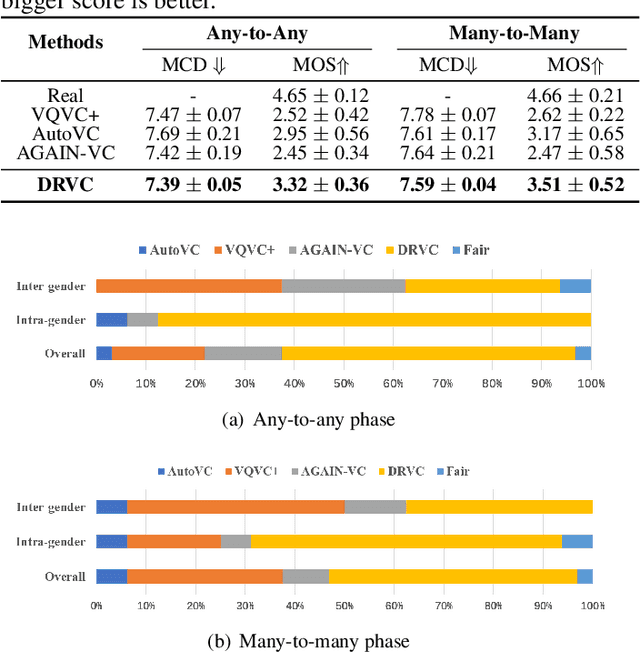

Any-to-any voice conversion problem aims to convert voices for source and target speakers, which are out of the training data. Previous works wildly utilize the disentangle-based models. The disentangle-based model assumes the speech consists of content and speaker style information and aims to untangle them to change the style information for conversion. Previous works focus on reducing the dimension of speech to get the content information. But the size is hard to determine to lead to the untangle overlapping problem. We propose the Disentangled Representation Voice Conversion (DRVC) model to address the issue. DRVC model is an end-to-end self-supervised model consisting of the content encoder, timbre encoder, and generator. Instead of the previous work for reducing speech size to get content, we propose a cycle for restricting the disentanglement by the Cycle Reconstruct Loss and Same Loss. The experiments show there is an improvement for converted speech on quality and voice similarity.