 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-T CRF: Spatial-Temporal Conditional Random Field for Human Trajectory Prediction
Nov 30, 2023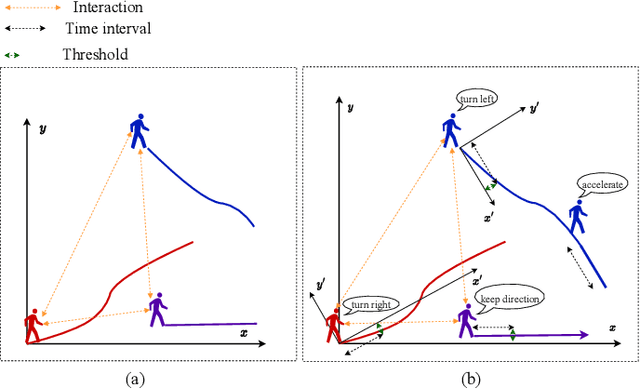
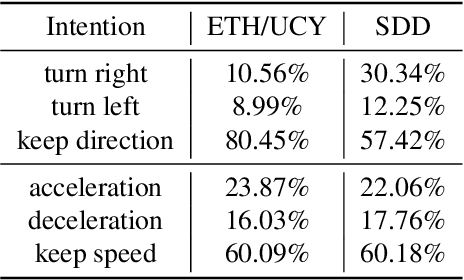
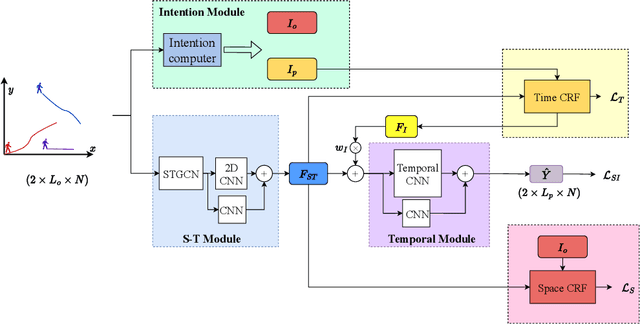
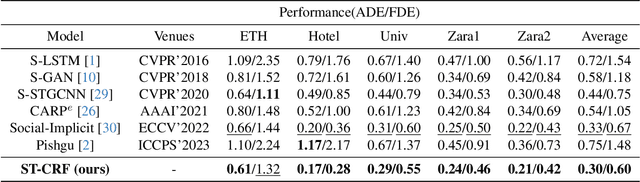
Trajectory prediction is of significant importance in computer vision. Accurate pedestrian trajectory prediction benefits autonomous vehicles and robots in planning their motion. Pedestrians' trajectories are greatly influenced by their intentions. Prior studies having introduced various deep learning methods only pay attention to the spatial and temporal information of trajectory, overlooking the explicit intention information. In this study, we introduce a novel model, termed the \textbf{S-T CRF}: \textbf{S}patial-\textbf{T}emporal \textbf{C}onditional \textbf{R}andom \textbf{F}ield, which judiciously incorporates intention information besides spatial and temporal information of trajectory. This model uses a Conditional Random Field (CRF) to generate a representation of future intentions, greatly improving the prediction of subsequent trajectories when combined with spatial-temporal representation. Furthermore, the study innovatively devises a space CRF loss and a time CRF loss, meticulously designed to enhance interaction constraints and temporal dynamics, respectively. Extensive experimental evaluations on dataset ETH/UCY and SDD demonstrate that the proposed method surpasses existing baseline approaches.
STF: Spatial Temporal Fusion for Trajectory Prediction
Nov 29, 2023



Trajectory prediction is a challenging task that aims to predict the future trajectory of vehicles or pedestrians over a short time horizon based on their historical positions. The main reason is that the trajectory is a kind of complex data, including spatial and temporal information, which is crucial for accurate prediction. Intuitively, the more information the model can capture, the more precise the future trajectory can be predicted. However, previous works based on deep learning methods processed spatial and temporal information separately, leading to inadequate spatial information capture, which means they failed to capture the complete spatial information. Therefore, it is of significance to capture information more fully and effectively on vehicle interactions. In this study, we introduced an integrated 3D graph that incorporates both spatial and temporal edges. Based on this, we proposed the integrated 3D graph, which considers the cross-time interaction information. In specific, we design a Spatial-Temporal Fusion (STF) model including Multi-layer perceptions (MLP) and Graph Attention (GAT) to capture the spatial and temporal information historical trajectories simultaneously on the 3D graph. Our experiment on the ApolloScape Trajectory Datasets shows that the proposed STF outperforms several baseline methods, especially on the long-time-horizon trajectory prediction.
CSG: Curriculum Representation Learning for Signed Graph
Oct 17, 2023



Signed graphs are valuable for modeling complex relationships with positive and negative connections, and Signed Graph Neural Networks (SGNNs) have become crucial tools for their analysis. However, prior to our work, no specific training plan existed for SGNNs, and the conventional random sampling approach did not address varying learning difficulties within the graph's structure. We proposed a curriculum-based training approach, where samples progress from easy to complex, inspired by human learning. To measure learning difficulty, we introduced a lightweight mechanism and created the Curriculum representation learning framework for Signed Graphs (CSG). This framework optimizes the order in which samples are presented to the SGNN model. Empirical validation across six real-world datasets showed impressive results, enhancing SGNN model accuracy by up to 23.7% in link sign prediction (AUC) and significantly improving stability with an up to 8.4 reduction in the standard deviation of AUC scores.