 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoice Outweighs Effort: Facilitating Complementary Knowledge Fusion in Federated Learning via Re-calibration and Merit-discrimination
Aug 25, 2025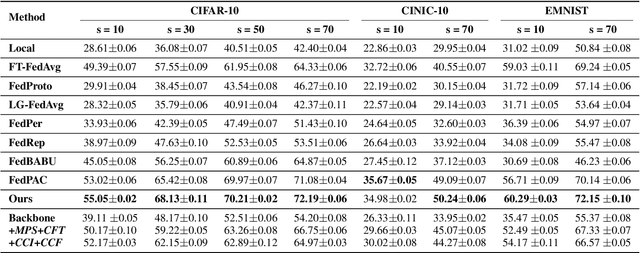
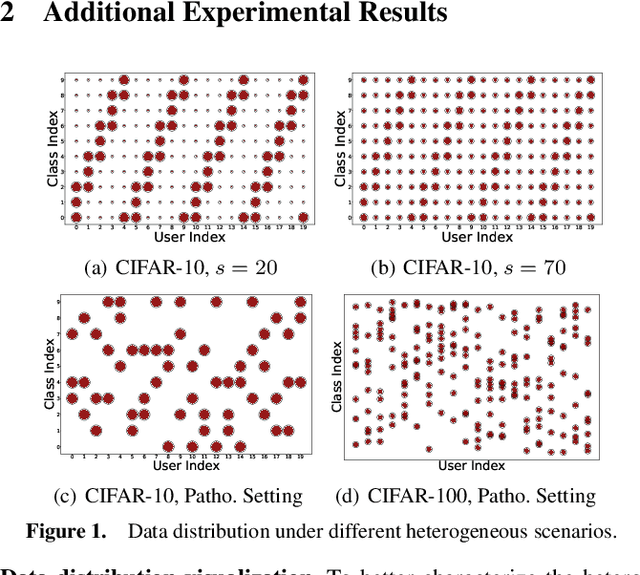

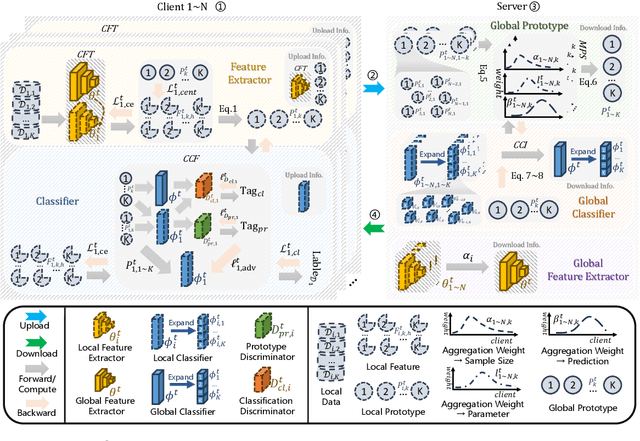
Cross-client data heterogeneity in federated learning induces biases that impede unbiased consensus condensation and the complementary fusion of generalization- and personalization-oriented knowledge. While existing approaches mitigate heterogeneity through model decoupling and representation center loss, they often rely on static and restricted metrics to evaluate local knowledge and adopt global alignment too rigidly, leading to consensus distortion and diminished model adaptability. To address these limitations, we propose FedMate, a method that implements bilateral optimization: On the server side, we construct a dynamic global prototype, with aggregation weights calibrated by holistic integration of sample size, current parameters, and future prediction; a category-wise classifier is then fine-tuned using this prototype to preserve global consistency. On the client side, we introduce complementary classification fusion to enable merit-based discrimination training and incorporate cost-aware feature transmission to balance model performance and communication efficiency. Experiments on five datasets of varying complexity demonstrate that FedMate outperforms state-of-the-art methods in harmonizing generalization and adaptation. Additionally, semantic segmentation experiments on autonomous driving datasets validate the method's real-world scalability.
PEVLM: Parallel Encoding for Vision-Language Models
Jun 24, 2025



Vision-Language Models (VLMs) have demonstrated strong performance in video-language tasks, yet their application to long video understanding remains constrained by the quadratic complexity of standard attention mechanisms. In this paper, we propose \textbf{PEVLM}, a parallel encoding strategy specifically designed to improve the prefill efficiency of VLMs without requiring model finetuning. PEVLM partitions the input into block-wise segments with a shared sink, preserves full-attention positional embeddings, and aligns attention weights to mimic full-attention distributions. This design reduces attention computation from $O((T \times N)^2)$ to $O(T \times N)$ while maintaining high accuracy. Extensive experiments on the LongVideoBench benchmark show that PEVLM achieves up to 8.37\% accuracy improvement over existing inference-efficient methods and delivers up to 7.47x speedup in attention computation and 40\% reduction in end-to-end latency. Under strict latency constraints, PEVLM significantly outperforms baselines, raising accuracy from 23.26\% to 61.03\%. These results highlight PEVLM's effectiveness for low-latency, long-context video understanding, making it well-suited for real-world applications such as autonomous driving.
FedSaaS: Class-Consistency Federated Semantic Segmentation via Global Prototype Supervision and Local Adversarial Harmonization
May 14, 2025Federated semantic segmentation enables pixel-level classification in images through collaborative learning while maintaining data privacy. However, existing research commonly overlooks the fine-grained class relationships within the semantic space when addressing heterogeneous problems, particularly domain shift. This oversight results in ambiguities between class representation. To overcome this challenge, we propose a novel federated segmentation framework that strikes class consistency, termed FedSaaS. Specifically, we introduce class exemplars as a criterion for both local- and global-level class representations. On the server side, the uploaded class exemplars are leveraged to model class prototypes, which supervise global branch of clients, ensuring alignment with global-level representation. On the client side, we incorporate an adversarial mechanism to harmonize contributions of global and local branches, leading to consistent output. Moreover, multilevel contrastive losses are employed on both sides to enforce consistency between two-level representations in the same semantic space. Extensive experiments on several driving scene segmentation datasets demonstrate that our framework outperforms state-of-the-art methods, significantly improving average segmentation accuracy and effectively addressing the class-consistency representation problem.
An Adaptive Underwater Image Enhancement Framework via Multi-Domain Fusion and Color Compensation
Mar 05, 2025Underwater optical imaging is severely degraded by light absorption, scattering, and color distortion, hindering visibility and accurate image analysis. This paper presents an adaptive enhancement framework integrating illumination compensation, multi-domain filtering, and dynamic color correction. A hybrid illumination compensation strategy combining CLAHE, Gamma correction, and Retinex enhances visibility. A two-stage filtering process, including spatial-domain (Gaussian, Bilateral, Guided) and frequency-domain (Fourier, Wavelet) methods, effectively reduces noise while preserving details. To correct color distortion, an adaptive color compensation (ACC) model estimates spectral attenuation and water type to combine RCP, DCP, and MUDCP dynamically. Finally, a perceptually guided color balance mechanism ensures natural color restoration. Experimental results on benchmark datasets demonstrate superior performance over state-of-the-art methods in contrast enhancement, color correction, and structural preservation, making the framework robust for underwater imaging applications.
Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space
Aug 14, 2024



In a multi-agent system (MAS), action semantics indicates the different influences of agents' actions toward other entities, and can be used to divide agents into groups in a physically heterogeneous MAS. Previous multi-agent reinforcement learning (MARL) algorithms apply global parameter-sharing across different types of heterogeneous agents without careful discrimination of different action semantics. This common implementation decreases the cooperation and coordination between agents in complex situations. However, fully independent agent parameters dramatically increase the computational cost and training difficulty. In order to benefit from the usage of different action semantics while also maintaining a proper parameter-sharing structure, we introduce the Unified Action Space (UAS) to fulfill the requirement. The UAS is the union set of all agent actions with different semantics. All agents first calculate their unified representation in the UAS, and then generate their heterogeneous action policies using different available-action-masks. To further improve the training of extra UAS parameters, we introduce a Cross-Group Inverse (CGI) loss to predict other groups' agent policies with the trajectory information. As a universal method for solving the physically heterogeneous MARL problem, we implement the UAS adding to both value-based and policy-based MARL algorithms, and propose two practical algorithms: U-QMIX and U-MAPPO. Experimental results in the SMAC environment prove the effectiveness of both U-QMIX and U-MAPPO compared with several state-of-the-art MARL methods.
GHQ: Grouped Hybrid Q Learning for Heterogeneous Cooperative Multi-agent Reinforcement Learning
Mar 02, 2023Previous deep multi-agent reinforcement learning (MARL) algorithms have achieved impressive results, typically in homogeneous scenarios. However, heterogeneous scenarios are also very common and usually harder to solve. In this paper, we mainly discuss cooperative heterogeneous MARL problems in Starcraft Multi-Agent Challenges (SMAC) environment. We firstly define and describe the heterogeneous problems in SMAC. In order to comprehensively reveal and study the problem, we make new maps added to the original SMAC maps. We find that baseline algorithms fail to perform well in those heterogeneous maps. To address this issue, we propose the Grouped Individual-Global-Max Consistency (GIGM) and a novel MARL algorithm, Grouped Hybrid Q Learning (GHQ). GHQ separates agents into several groups and keeps individual parameters for each group, along with a novel hybrid structure for factorization. To enhance coordination between groups, we maximize the Inter-group Mutual Information (IGMI) between groups' trajectories. Experiments on original and new heterogeneous maps show the fabulous performance of GHQ compared to other state-of-the-art algorithms.