 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
Paper and Code
May 21, 2024

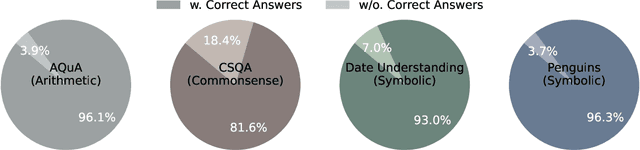
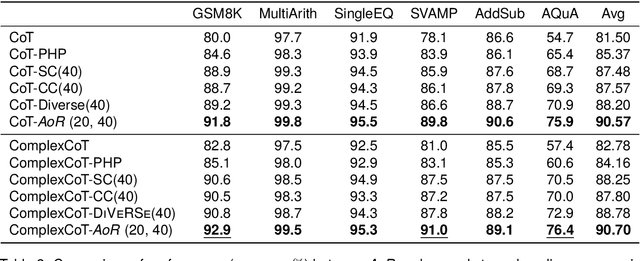
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.