 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Embeddings with Task-Oriented prompting
May 17, 2024This paper introduces Dynamic Embeddings with Task-Oriented prompting (DETOT), a novel approach aimed at improving the adaptability and efficiency of machine learning models by implementing a flexible embedding layer. Unlike traditional static embeddings [14], DETOT dynamically adjusts embeddings based on task-specific requirements and performance feedback, optimizing input data representation for individual tasks [4]. This method enhances both accuracy and computational performance by tailoring the representation layer to meet the unique needs of each task. The structure of DETOT is detailed, highlighting its task-specific adaptation, continuous feedback loop, and mechanisms for preventing overfitting. Empirical evaluations demonstrate its superiority over existing methods.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
Case Study: Testing Model Capabilities in Some Reasoning Tasks
Feb 15, 2024Large Language Models (LLMs) excel in generating personalized content and facilitating interactive dialogues, showcasing their remarkable aptitude for a myriad of applications. However, their capabilities in reasoning and providing explainable outputs, especially within the context of reasoning abilities, remain areas for improvement. In this study, we delve into the reasoning abilities of LLMs, highlighting the current challenges and limitations that hinder their effectiveness in complex reasoning scenarios.
Improving Agent Interactions in Virtual Environments with Language Models
Feb 08, 2024Enhancing AI systems with efficient communication skills for effective human assistance necessitates proactive initiatives from the system side to discern specific circumstances and interact aptly. This research focuses on a collective building assignment in the Minecraft dataset, employing language modeling to enhance task understanding through state-of-the-art methods. These models focus on grounding multi-modal understanding and task-oriented dialogue comprehension tasks, providing insights into their interpretative and responsive capabilities. Our experimental results showcase a substantial improvement over existing methods, indicating a promising direction for future research in this domain.
Physics Driven Domain Specific Transporter Framework with Attention Mechanism for Ultrasound Imaging
Sep 13, 2021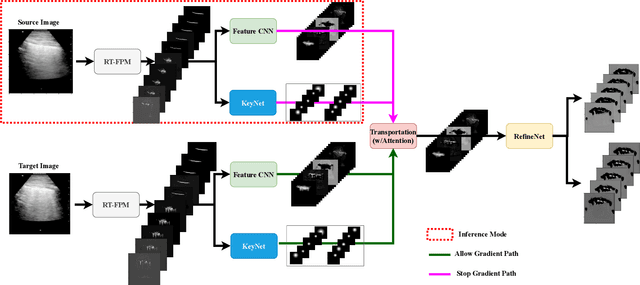
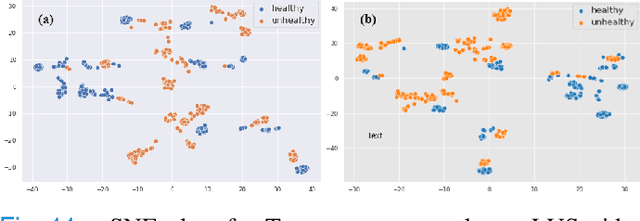
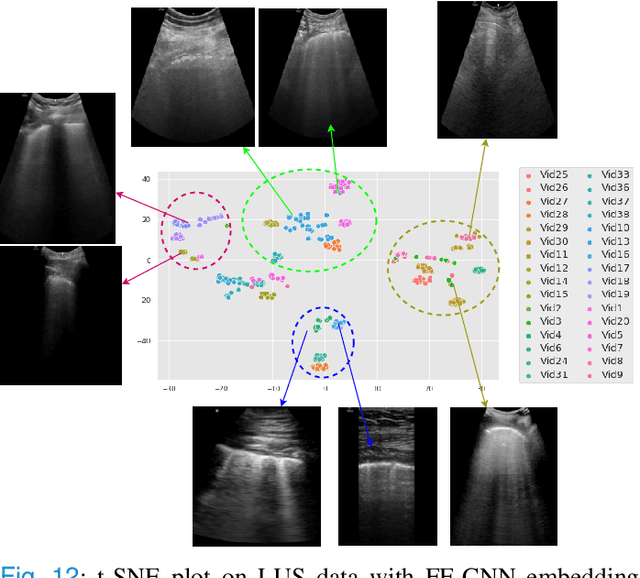
Most applications of deep learning techniques in medical imaging are supervised and require a large number of labeled data which is expensive and requires many hours of careful annotation by experts. In this paper, we propose an unsupervised, physics driven domain specific transporter framework with an attention mechanism to identify relevant key points with applications in ultrasound imaging. The proposed framework identifies key points that provide a concise geometric representation highlighting regions with high structural variation in ultrasound videos. We incorporate physics driven domain specific information as a feature probability map and use the radon transform to highlight features in specific orientations. The proposed framework has been trained on130 Lung ultrasound (LUS) videos and 113 Wrist ultrasound (WUS) videos and validated on 100 Lung ultrasound (LUS) videos and 58 Wrist ultrasound (WUS) videos acquired from multiple centers across the globe. Images from both datasets were independently assessed by experts to identify clinically relevant features such as A-lines, B-lines and pleura from LUS and radial metaphysis, radial epiphysis and carpal bones from WUS videos. The key points detected from both datasets showed high sensitivity (LUS = 99\% , WUS = 74\%) in detecting the image landmarks identified by experts. Also, on employing for classification of the given lung image into normal and abnormal classes, the proposed approach, even with no prior training, achieved an average accuracy of 97\% and an average F1-score of 95\% respectively on the task of co-classification with 3 fold cross-validation. With the purely unsupervised nature of the proposed approach, we expect the key point detection approach to increase the applicability of ultrasound in various examination performed in emergency and point of care.
Domain Specific Transporter Framework to Detect Fractures in Ultrasound
Jun 09, 2021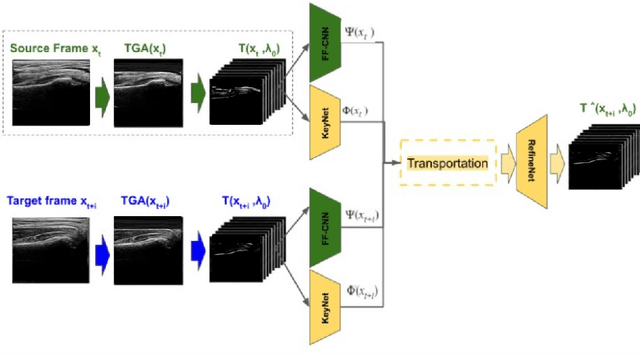
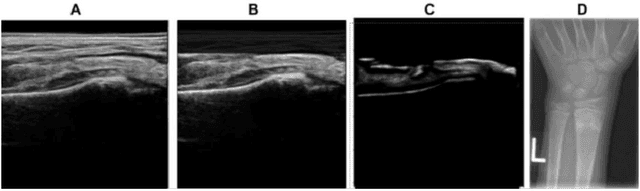
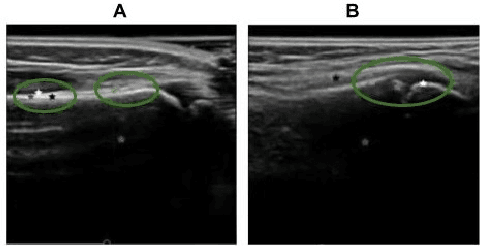
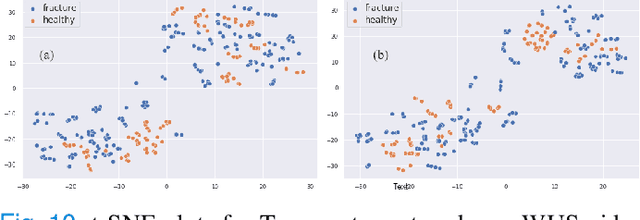
Ultrasound examination for detecting fractures is ideally suited for Emergency Departments (ED) as it is relatively fast, safe (from ionizing radiation), has dynamic imaging capability and is easily portable. High interobserver variability in manual assessment of ultrasound scans has piqued research interest in automatic assessment techniques using Deep Learning (DL). Most DL techniques are supervised and are trained on large numbers of labeled data which is expensive and requires many hours of careful annotation by experts. In this paper, we propose an unsupervised, domain specific transporter framework to identify relevant keypoints from wrist ultrasound scans. Our framework provides a concise geometric representation highlighting regions with high structural variation in a 3D ultrasound (3DUS) sequence. We also incorporate domain specific information represented by instantaneous local phase (LP) which detects bone features from 3DUS. We validate the technique on 3DUS videos obtained from 30 subjects. Each ultrasound scan was independently assessed by three readers to identify fractures along with the corresponding x-ray. Saliency of keypoints detected in the image\ are compared against manual assessment based on distance from relevant features.The transporter neural network was able to accurately detect 180 out of 250 bone regions sampled from wrist ultrasound videos. We expect this technique to increase the applicability of ultrasound in fracture detection.