 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Effective Is Self-Consistency for Long-Context Problems?
Nov 02, 2024Self-consistency (SC) has been demonstrated to enhance the performance of large language models (LLMs) across various tasks and domains involving short content. However, does this evidence support its effectiveness for long-context problems? This study examines the role of SC in long-context scenarios, where LLMs often struggle with position bias, hindering their ability to utilize information effectively from all parts of their long input context. We examine a range of design parameters, including different models, context lengths, prompt formats, and types of datasets and tasks. Our findings demonstrate that SC, while effective for short-context problems, fundamentally fails for long-context tasks -- not only does it fail to mitigate position bias, but it can also actively degrade performance. We observe that the effectiveness of SC varies with context length and model size but remains mainly unaffected by prompt format or task type. These results provide valuable insight into the limitations of current LLMs in long-context understanding and highlight the need for more sophisticated approaches to address position bias in these models.
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Jun 20, 2024Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a "know but don't tell" phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
Class Density and Dataset Quality in High-Dimensional, Unstructured Data
Feb 08, 2022We provide a definition for class density that can be used to measure the aggregate similarity of the samples within each of the classes in a high-dimensional, unstructured dataset. We then put forth several candidate methods for calculating class density and analyze the correlation between the values each method produces with the corresponding individual class test accuracies achieved on a trained model. Additionally, we propose a definition for dataset quality for high-dimensional, unstructured data and show that those datasets that met a certain quality threshold (experimentally demonstrated to be > 10 for the datasets studied) were candidates for eliding redundant data based on the individual class densities.
Towards an Analytical Definition of Sufficient Data
Feb 07, 2022We show that, for each of five datasets of increasing complexity, certain training samples are more informative of class membership than others. These samples can be identified a priori to training by analyzing their position in reduced dimensional space relative to the classes' centroids. Specifically, we demonstrate that samples nearer the classes' centroids are less informative than those that are furthest from it. For all five datasets, we show that there is no statistically significant difference between training on the entire training set and when excluding up to 2% of the data nearest to each class's centroid.
On the Importance of Capturing a Sufficient Diversity of Perspective for the Classification of micro-PCBs
Jan 27, 2021
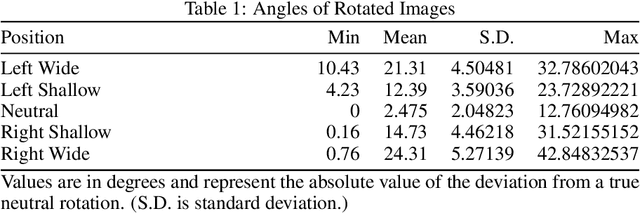
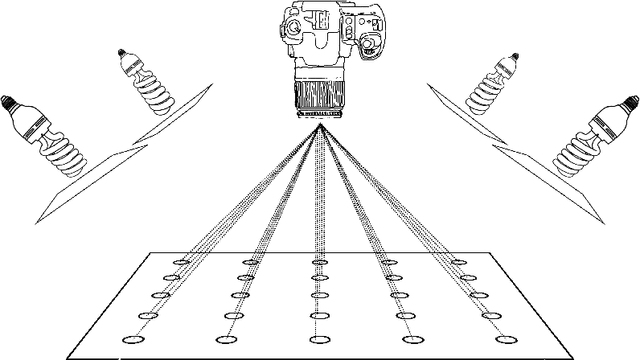
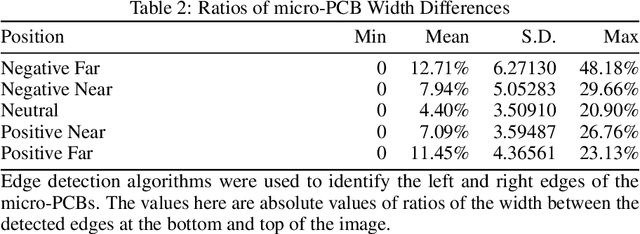
We present a dataset consisting of high-resolution images of 13 micro-PCBs captured in various rotations and perspectives relative to the camera, with each sample labeled for PCB type, rotation category, and perspective categories. We then present the design and results of experimentation on combinations of rotations and perspectives used during training and the resulting impact on test accuracy. We then show when and how well data augmentation techniques are capable of simulating rotations vs. perspectives not present in the training data. We perform all experiments using CNNs with and without homogeneous vector capsules (HVCs) and investigate and show the capsules' ability to better encode the equivariance of the sub-components of the micro-PCBs. The results of our experiments lead us to conclude that training a neural network equipped with HVCs, capable of modeling equivariance among sub-components, coupled with training on a diversity of perspectives, achieves the greatest classification accuracy on micro-PCB data.
A Branching and Merging Convolutional Network with Homogeneous Filter Capsules
Jan 31, 2020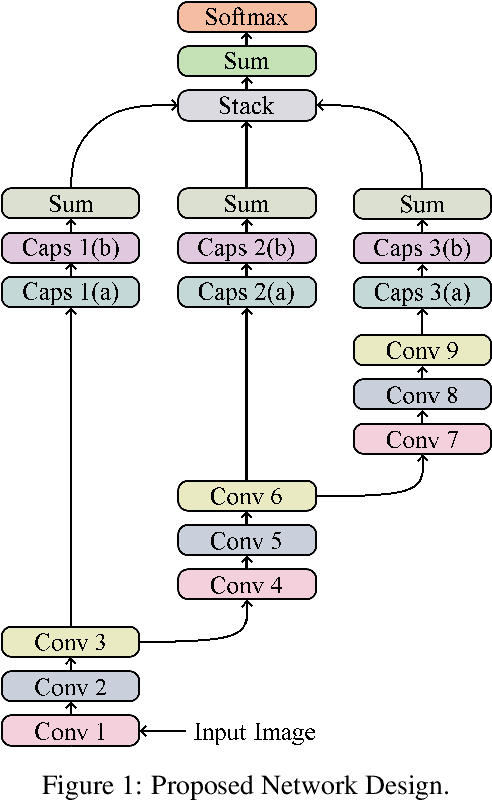

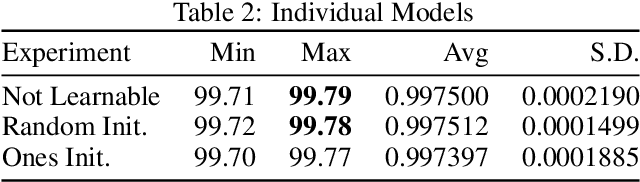
We present a convolutional neural network design with additional branches after certain convolutions so that we can extract features with differing effective receptive fields and levels of abstraction. From each branch, we transform each of the final filters into a pair of homogeneous vector capsules. As the capsules are formed from entire filters, we refer to them as filter capsules. We then compare three methods for merging the branches--merging with equal weight and merging with learned weights, with two different weight initialization strategies. This design, in combination with a domain-specific set of randomly applied augmentation techniques, establishes a new state of the art for the MNIST dataset with an accuracy of 99.84% for an ensemble of these models, as well as establishing a new state of the art for a single model (99.79% accurate). These accuracies were achieved with a 75% reduction in both the number of parameters and the number of epochs of training relative to the previously best performing capsule network on MNIST. All training was performed using the Adam optimizer and experienced no overfitting.
Homogeneous Vector Capsules Enable Adaptive Gradient Descent in Convolutional Neural Networks
Jun 20, 2019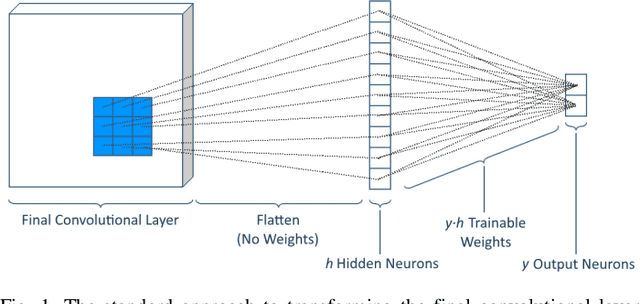
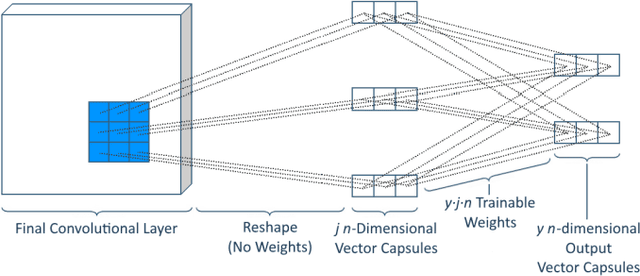
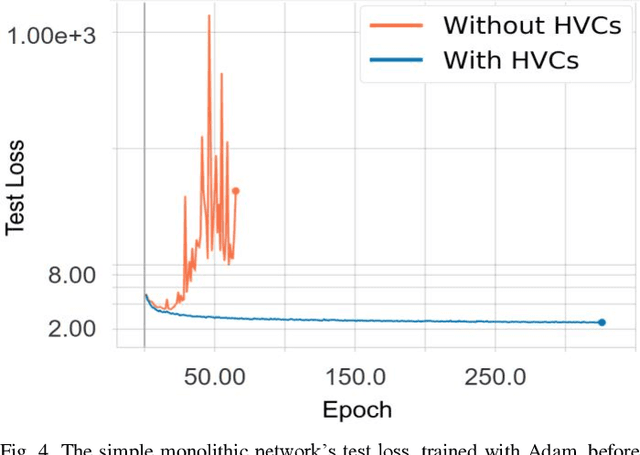
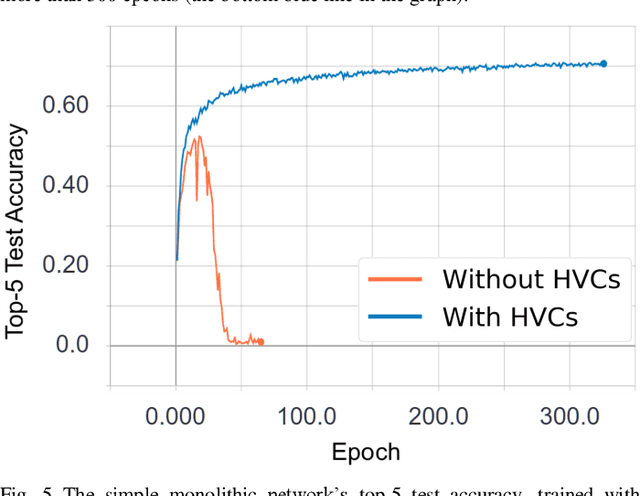
Capsules are the name given by Geoffrey Hinton to vector-valued neurons. Neural networks traditionally produce a scalar value for an activated neuron. Capsules, on the other hand, produce a vector of values, which Hinton argues correspond to a single, composite feature wherein the values of the components of the vectors indicate properties of the feature such as transformation or contrast. We present a new way of parameterizing and training capsules that we refer to as homogeneous vector capsules (HVCs). We demonstrate, experimentally, that altering a convolutional neural network (CNN) to use HVCs can achieve superior classification accuracy without increasing the number of parameters or operations in its architecture as compared to a CNN using a single final fully connected layer. Additionally, the introduction of HVCs enables the use of adaptive gradient descent, reducing the dependence a model's achievable accuracy has on the finely tuned hyperparameters of a non-adaptive optimizer. We demonstrate our method and results using two neural network architectures. First, a very simple monolithic CNN that when using HVCs achieved a 63% improvement in top-1 classification accuracy and a 35% improvement in top-5 classification accuracy over the baseline architecture. Second, with the CNN architecture referred to as Inception v3 that achieved similar accuracies both with and without HVCs. Additionally, the simple monolithic CNN when using HVCs showed no overfitting after more than 300 epochs whereas the baseline showed overfitting after 30 epochs. We use the ImageNet ILSVRC 2012 classification challenge dataset with both networks.