 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and Remote Sensing for Resilient and Sustainable Built Environments: A Review of Current Methods, Open Data and Future Directions
Jul 02, 2025Critical infrastructure, such as transport networks, underpins economic growth by enabling mobility and trade. However, ageing assets, climate change impacts (e.g., extreme weather, rising sea levels), and hybrid threats ranging from natural disasters to cyber attacks and conflicts pose growing risks to their resilience and functionality. This review paper explores how emerging digital technologies, specifically Artificial Intelligence (AI), can enhance damage assessment and monitoring of transport infrastructure. A systematic literature review examines existing AI models and datasets for assessing damage in roads, bridges, and other critical infrastructure impacted by natural disasters. Special focus is given to the unique challenges and opportunities associated with bridge damage detection due to their structural complexity and critical role in connectivity. The integration of SAR (Synthetic Aperture Radar) data with AI models is also discussed, with the review revealing a critical research gap: a scarcity of studies applying AI models to SAR data for comprehensive bridge damage assessment. Therefore, this review aims to identify the research gaps and provide foundations for AI-driven solutions for assessing and monitoring critical transport infrastructures.
A review of faithfulness metrics for hallucination assessment in Large Language Models
Dec 31, 2024This review examines the means with which faithfulness has been evaluated across open-ended summarization, question-answering and machine translation tasks. We find that the use of LLMs as a faithfulness evaluator is commonly the metric that is most highly correlated with human judgement. The means with which other studies have mitigated hallucinations is discussed, with both retrieval augmented generation (RAG) and prompting framework approaches having been linked with superior faithfulness, whilst other recommendations for mitigation are provided. Research into faithfulness is integral to the continued widespread use of LLMs, as unfaithful responses can pose major risks to many areas whereby LLMs would otherwise be suitable. Furthermore, evaluating open-ended generation provides a more comprehensive measure of LLM performance than commonly used multiple-choice benchmarking, which can help in advancing the trust that can be placed within LLMs.
A Dataset Fusion Algorithm for Generalised Anomaly Detection in Homogeneous Periodic Time Series Datasets
May 14, 2023The generalisation of Neural Networks (NN) to multiple datasets is often overlooked in literature due to NNs typically being optimised for specific data sources. This becomes especially challenging in time-series-based multi-dataset models due to difficulties in fusing sequential data from different sensors and collection specifications. In a commercial environment, however, generalisation can effectively utilise available data and computational power, which is essential in the context of Green AI, the sustainable development of AI models. This paper introduces "Dataset Fusion," a novel dataset composition algorithm for fusing periodic signals from multiple homogeneous datasets into a single dataset while retaining unique features for generalised anomaly detection. The proposed approach, tested on a case study of 3-phase current data from 2 different homogeneous Induction Motor (IM) fault datasets using an unsupervised LSTMCaps NN, significantly outperforms conventional training approaches with an Average F1 score of 0.879 and effectively generalises across all datasets. The proposed approach was also tested with varying percentages of the training data, in line with the principles of Green AI. Results show that using only 6.25\% of the training data, translating to a 93.7\% reduction in computational power, results in a mere 4.04\% decrease in performance, demonstrating the advantages of the proposed approach in terms of both performance and computational efficiency. Moreover, the algorithm's effectiveness under non-ideal conditions highlights its potential for practical use in real-world applications.
Herder Ants: Ant Colony Optimization with Aphids for Discrete Event-Triggered Dynamic Optimization Problems
Apr 15, 2023Currently available dynamic optimization strategies for Ant Colony Optimization (ACO) algorithm offer a trade-off of slower algorithm convergence or significant penalty to solution quality after each dynamic change occurs. This paper proposes a discrete dynamic optimization strategy called Ant Colony Optimization (ACO) with Aphids, modelled after a real-world symbiotic relationship between ants and aphids. ACO with Aphids strategy is designed to improve solution quality of discrete domain Dynamic Optimization Problems (DOPs) with event-triggered discrete dynamism. The proposed strategy aims to improve the inter-state convergence rate throughout the entire dynamic optimization. It does so by minimizing the fitness penalty and maximizing the convergence speed that occurs after the dynamic change. This strategy is tested against Full-Restart and Pheromone-Sharing strategies implemented on the same ACO core algorithm solving Dynamic Multidimensional Knapsack Problem (DMKP) benchmarks. ACO with Aphids has demonstrated superior performance over the Pheromone-Sharing strategy in every test on average gap reduced by 29.2%. Also, ACO with Aphids has outperformed the Full-Restart strategy for large datasets groups, and the overall average gap is reduced by 52.5%.
Hybridization of Capsule and LSTM Networks for unsupervised anomaly detection on multivariate data
Feb 11, 2022Deep learning techniques have recently shown promise in the field of anomaly detection, providing a flexible and effective method of modelling systems in comparison to traditional statistical modelling and signal processing-based methods. However, there are a few well publicised issues Neural Networks (NN)s face such as generalisation ability, requiring large volumes of labelled data to be able to train effectively and understanding spatial context in data. This paper introduces a novel NN architecture which hybridises the Long-Short-Term-Memory (LSTM) and Capsule Networks into a single network in a branched input Autoencoder architecture for use on multivariate time series data. The proposed method uses an unsupervised learning technique to overcome the issues with finding large volumes of labelled training data. Experimental results show that without hyperparameter optimisation, using Capsules significantly reduces overfitting and improves the training efficiency. Additionally, results also show that the branched input models can learn multivariate data more consistently with or without Capsules in comparison to the non-branched input models. The proposed model architecture was also tested on an open-source benchmark, where it achieved state-of-the-art performance in outlier detection, and overall performs best over the metrics tested in comparison to current state-of-the art methods.
Class Density and Dataset Quality in High-Dimensional, Unstructured Data
Feb 08, 2022We provide a definition for class density that can be used to measure the aggregate similarity of the samples within each of the classes in a high-dimensional, unstructured dataset. We then put forth several candidate methods for calculating class density and analyze the correlation between the values each method produces with the corresponding individual class test accuracies achieved on a trained model. Additionally, we propose a definition for dataset quality for high-dimensional, unstructured data and show that those datasets that met a certain quality threshold (experimentally demonstrated to be > 10 for the datasets studied) were candidates for eliding redundant data based on the individual class densities.
Towards an Analytical Definition of Sufficient Data
Feb 07, 2022We show that, for each of five datasets of increasing complexity, certain training samples are more informative of class membership than others. These samples can be identified a priori to training by analyzing their position in reduced dimensional space relative to the classes' centroids. Specifically, we demonstrate that samples nearer the classes' centroids are less informative than those that are furthest from it. For all five datasets, we show that there is no statistically significant difference between training on the entire training set and when excluding up to 2% of the data nearest to each class's centroid.
On the Importance of Capturing a Sufficient Diversity of Perspective for the Classification of micro-PCBs
Jan 27, 2021
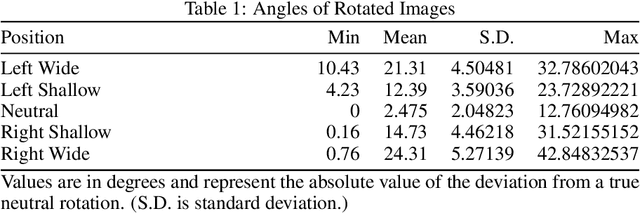
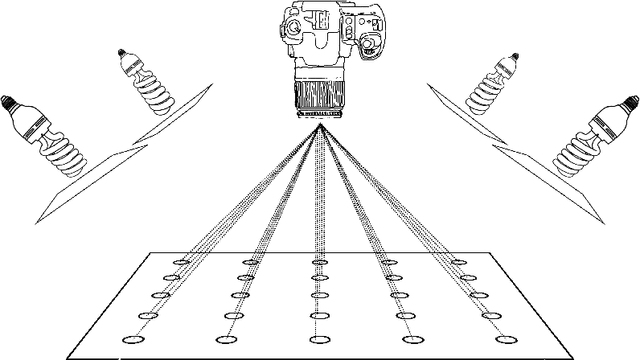
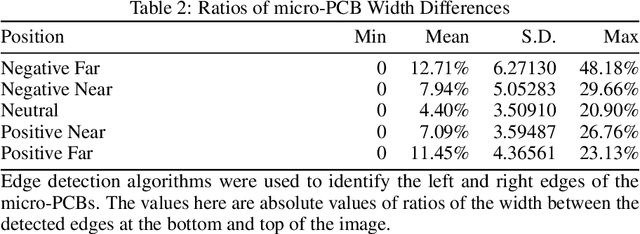
We present a dataset consisting of high-resolution images of 13 micro-PCBs captured in various rotations and perspectives relative to the camera, with each sample labeled for PCB type, rotation category, and perspective categories. We then present the design and results of experimentation on combinations of rotations and perspectives used during training and the resulting impact on test accuracy. We then show when and how well data augmentation techniques are capable of simulating rotations vs. perspectives not present in the training data. We perform all experiments using CNNs with and without homogeneous vector capsules (HVCs) and investigate and show the capsules' ability to better encode the equivariance of the sub-components of the micro-PCBs. The results of our experiments lead us to conclude that training a neural network equipped with HVCs, capable of modeling equivariance among sub-components, coupled with training on a diversity of perspectives, achieves the greatest classification accuracy on micro-PCB data.
Imperialist Competitive Algorithm with Independence and Constrained Assimilation for Solving 0-1 Multidimensional Knapsack Problem
Mar 14, 2020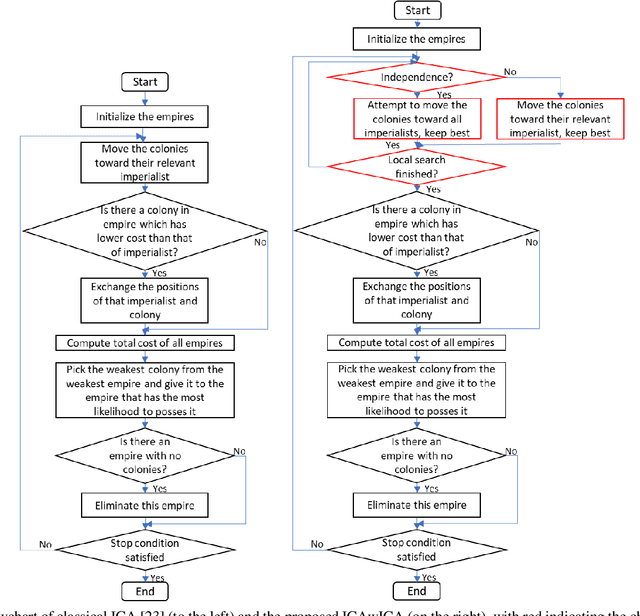

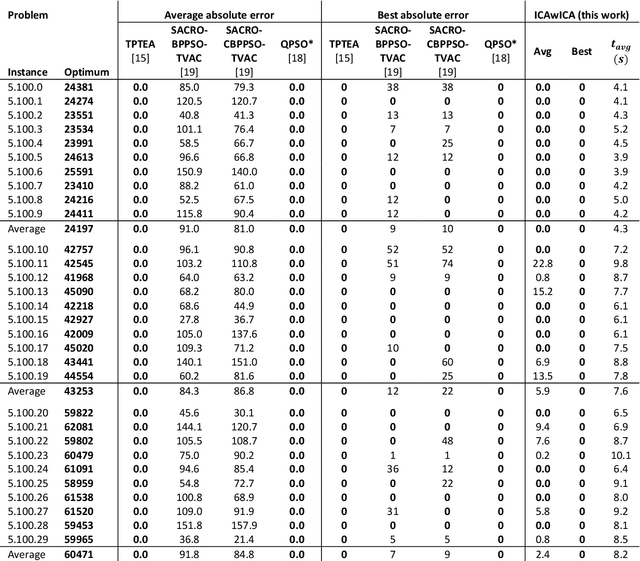
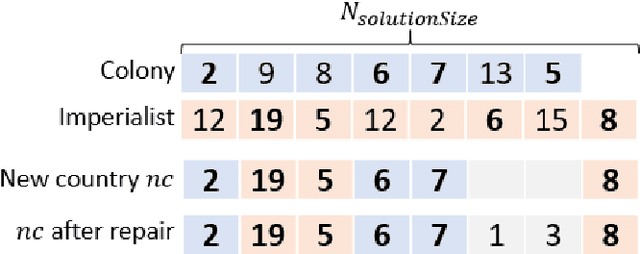
The multidimensional knapsack problem is a well-known constrained optimization problem with many real-world engineering applications. In order to solve this NP-hard problem, a new modified Imperialist Competitive Algorithm with Constrained Assimilation (ICAwICA) is presented. The proposed algorithm introduces the concept of colony independence, a free will to choose between classical ICA assimilation to empires imperialist or any other imperialist in the population. Furthermore, a constrained assimilation process has been implemented that combines classical ICA assimilation and revolution operators, while maintaining population diversity. This work investigates the performance of the proposed algorithm across 101 Multidimensional Knapsack Problem (MKP) benchmark instances. Experimental results show that the algorithm is able to obtain an optimal solution in all small instances and presents very competitive results for large MKP instances.
Dynamic Impact for Ant Colony Optimization algorithm
Feb 10, 2020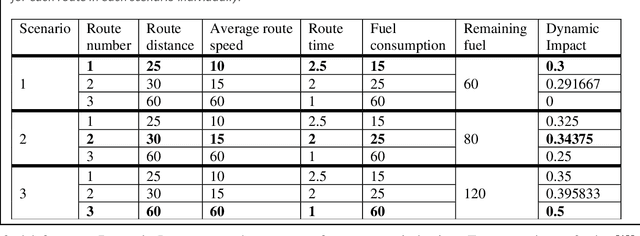

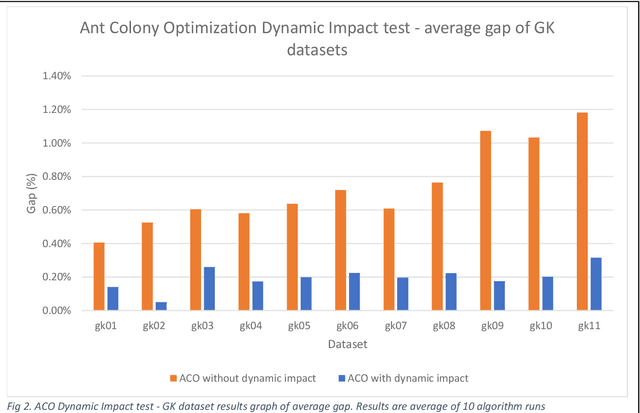
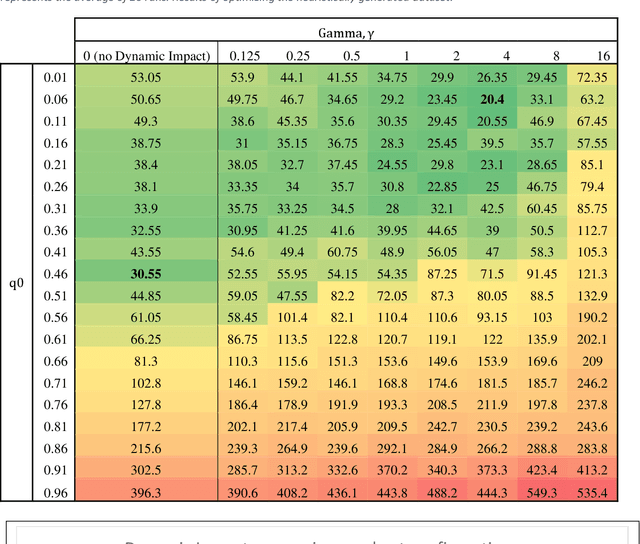
This paper proposes an extension method for Ant Colony Optimization (ACO) algorithm called Dynamic Impact. Dynamic Impact is designed to solve challenging optimization problems that has nonlinear relationship between resource consumption and fitness in relation to other part of the optimized solution. This proposed method is tested against complex real-world Microchip Manufacturing Plant Production Floor Optimization (MMPPFO) problem, as well as theoretical benchmark Multi-Dimensional Knapsack problem (MKP). MMPPFO is a non-trivial optimization problem, due the nature of solution fitness value dependence on collection of wafer-lots without prioritization of any individual wafer-lot. Using Dynamic Impact on single objective optimization fitness value is improved by 33.2%. Furthermore, MKP benchmark instances of small complexity have been solved to 100% success rate where high degree of solution sparseness is observed, and large instances have showed average gap improved by 4.26 times. Algorithm implementation demonstrated superior performance across small and large datasets and sparse optimization problems.