 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperialist Competitive Algorithm with Independence and Constrained Assimilation for Solving 0-1 Multidimensional Knapsack Problem
Mar 14, 2020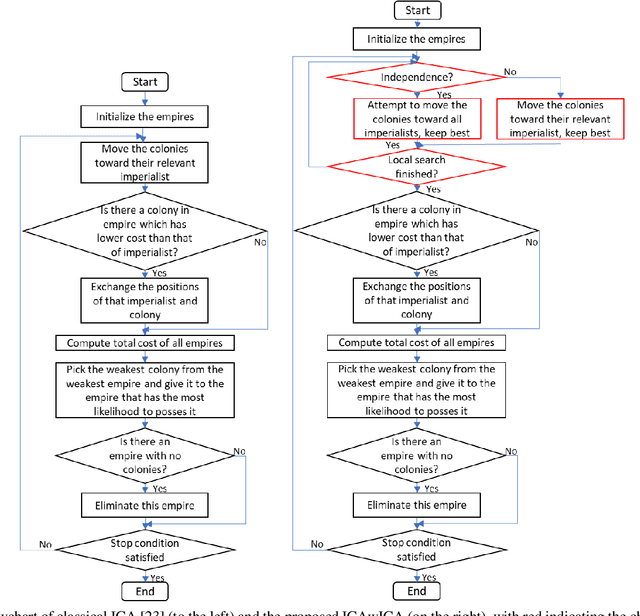

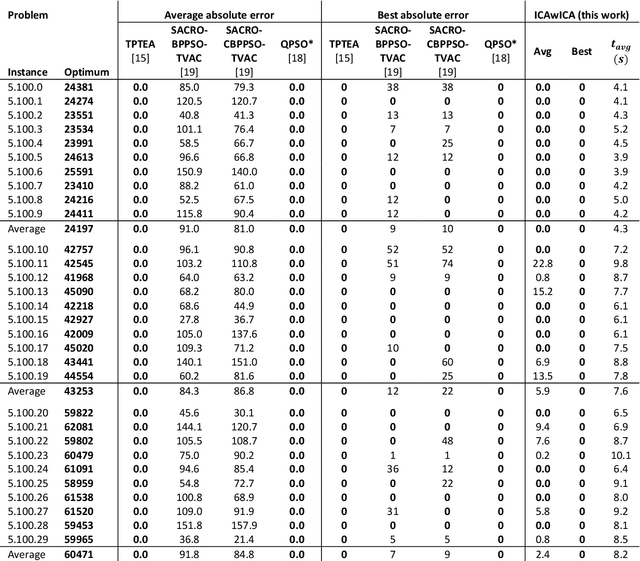
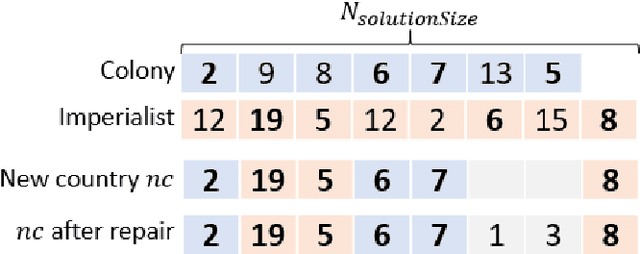
The multidimensional knapsack problem is a well-known constrained optimization problem with many real-world engineering applications. In order to solve this NP-hard problem, a new modified Imperialist Competitive Algorithm with Constrained Assimilation (ICAwICA) is presented. The proposed algorithm introduces the concept of colony independence, a free will to choose between classical ICA assimilation to empires imperialist or any other imperialist in the population. Furthermore, a constrained assimilation process has been implemented that combines classical ICA assimilation and revolution operators, while maintaining population diversity. This work investigates the performance of the proposed algorithm across 101 Multidimensional Knapsack Problem (MKP) benchmark instances. Experimental results show that the algorithm is able to obtain an optimal solution in all small instances and presents very competitive results for large MKP instances.
Accelerating supply chains with Ant Colony Optimization across range of hardware solutions
Jan 22, 2020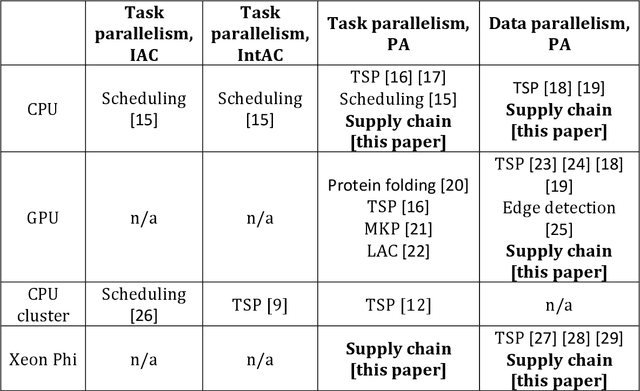
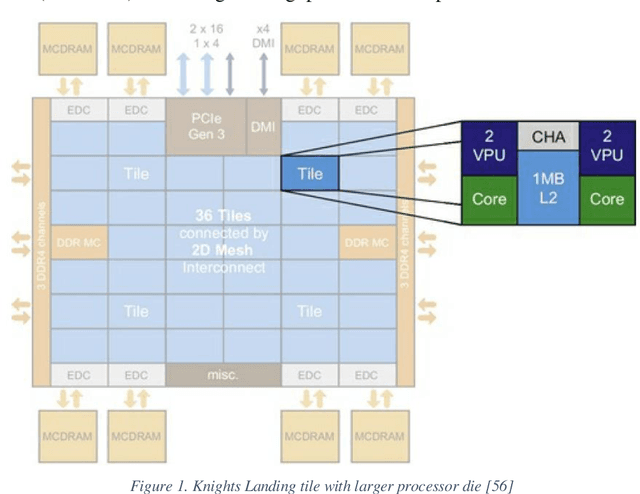
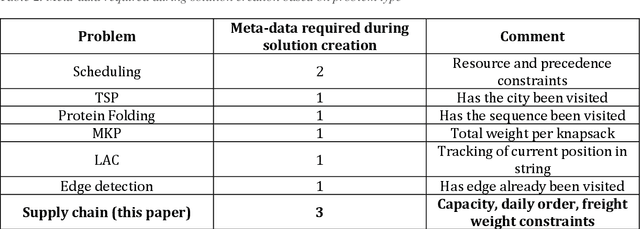
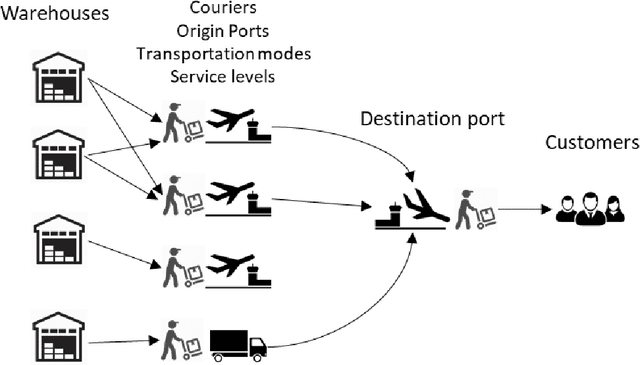
Ant Colony algorithm has been applied to various optimization problems, however most of the previous work on scaling and parallelism focuses on Travelling Salesman Problems (TSPs). Although, useful for benchmarks and new idea comparison, the algorithmic dynamics does not always transfer to complex real-life problems, where additional meta-data is required during solution construction. This paper looks at real-life outbound supply chain problem using Ant Colony Optimization (ACO) and its scaling dynamics with two parallel ACO architectures - Independent Ant Colonies (IAC) and Parallel Ants (PA). Results showed that PA was able to reach a higher solution quality in fewer iterations as the number of parallel instances increased. Furthermore, speed performance was measured across three different hardware solutions - 16 core CPU, 68 core Xeon Phi and up to 4 Geforce GPUs. State of the art, ACO vectorization techniques such as SS-Roulette were implemented using C++ and CUDA. Although excellent for TSP, it was concluded that for the given supply chain problem GPUs are not suitable due to meta-data access footprint required. Furthermore, compared to their sequential counterpart, vectorized CPU AVX2 implementation achieved 25.4x speedup on CPU while Xeon Phi with its AVX512 instruction set reached 148x on PA with Vectorized (PAwV). PAwV is therefore able to scale at least up to 1024 parallel instances on the supply chain network problem solved.