 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Feature Impact and Importance
Jun 08, 2020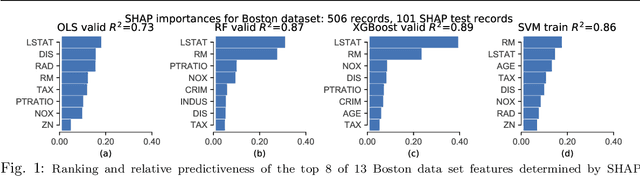

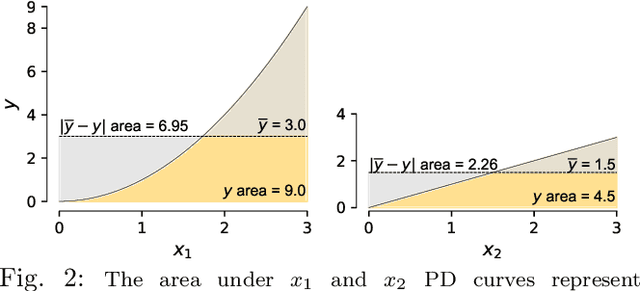
Practitioners use feature importance to rank and eliminate weak predictors during model development in an effort to simplify models and improve generality. Unfortunately, they also routinely conflate such feature importance measures with feature impact, the isolated effect of an explanatory variable on the response variable. This can lead to real-world consequences when importance is inappropriately interpreted as impact for business or medical insight purposes. The dominant approach for computing importances is through interrogation of a fitted model, which works well for feature selection, but gives distorted measures of feature impact. The same method applied to the same data set can yield different feature importances, depending on the model, leading us to conclude that impact should be computed directly from the data. While there are nonparametric feature selection algorithms, they typically provide feature rankings, rather than measures of impact or importance. They also typically focus on single-variable associations with the response. In this paper, we give mathematical definitions of feature impact and importance, derived from partial dependence curves, that operate directly on the data. To assess quality, we show that features ranked by these definitions are competitive with existing feature selection techniques using three real data sets for predictive tasks.
A Stratification Approach to Partial Dependence for Codependent Variables
Jul 15, 2019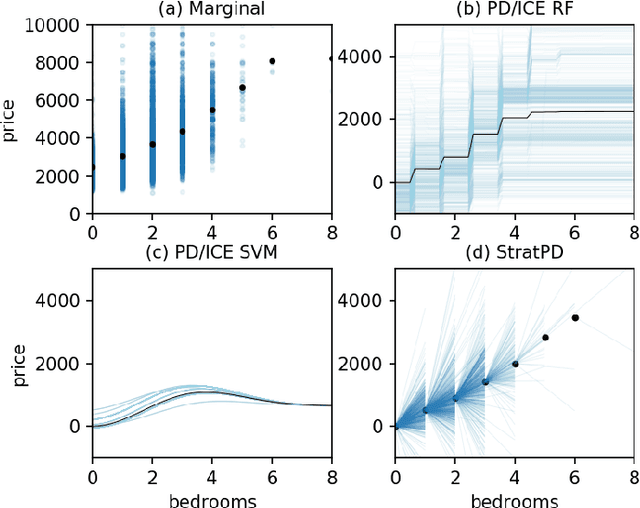

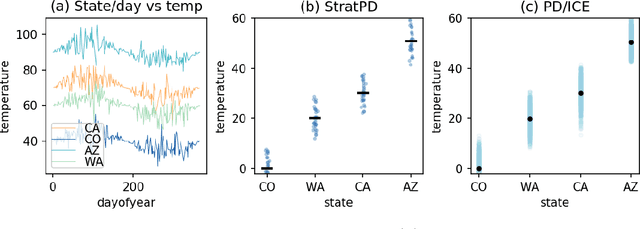
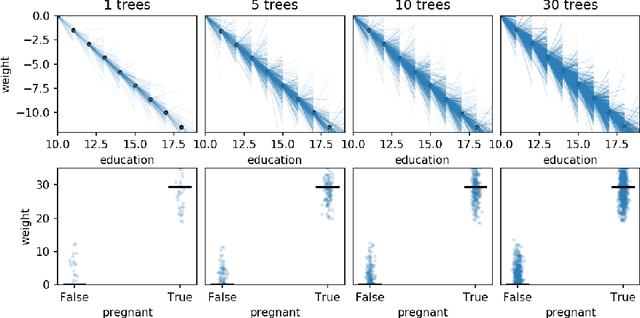
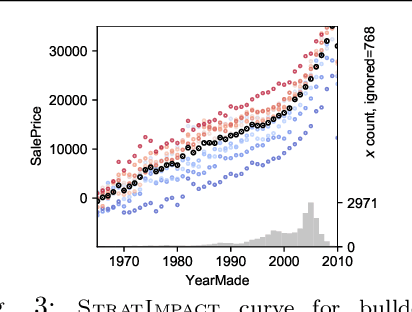
Model interpretability is important to machine learning practitioners, and a key component of interpretation is the characterization of partial dependence of the response variable on any subset of features used in the model. The two most common strategies for assessing partial dependence suffer from a number of critical weaknesses. In the first strategy, linear regression model coefficients describe how a unit change in an explanatory variable changes the response, while holding other variables constant. But, linear regression is inapplicable for high dimensional (p>n) data sets and is often insufficient to capture the relationship between explanatory variables and the response. In the second strategy, Partial Dependence (PD) plots and Individual Conditional Expectation (ICE) plots give biased results for the common situation of codependent variables and they rely on fitted models provided by the user. When the supplied model is a poor choice due to systematic bias or overfitting, PD/ICE plots provide little (if any) useful information. To address these issues, we introduce a new strategy, called StratPD, that does not depend on a user's fitted model, provides accurate results in the presence codependent variables, and is applicable to high dimensional settings. The strategy works by stratifying a data set into groups of observations that are similar, except in the variable of interest, through the use of a decision tree. Any fluctuations of the response variable within a group is likely due to the variable of interest. We apply StratPD to a collection of simulations and case studies to show that StratPD is a fast, reliable, and robust method for assessing partial dependence with clear advantages over state-of-the-art methods.
The Matrix Calculus You Need For Deep Learning
Jul 02, 2018This paper is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed. Note that you do not need to understand this material before you start learning to train and use deep learning in practice; rather, this material is for those who are already familiar with the basics of neural networks, and wish to deepen their understanding of the underlying math. Don't worry if you get stuck at some point along the way---just go back and reread the previous section, and try writing down and working through some examples. And if you're still stuck, we're happy to answer your questions in the Theory category at forums.fast.ai. Note: There is a reference section at the end of the paper summarizing all the key matrix calculus rules and terminology discussed here. See related articles at http://explained.ai
Technical Report: Towards a Universal Code Formatter through Machine Learning
Jun 28, 2016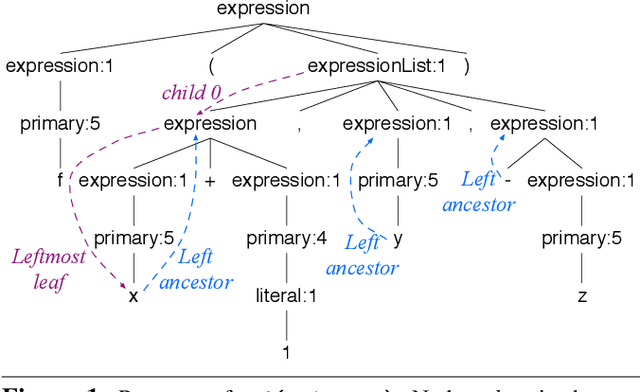
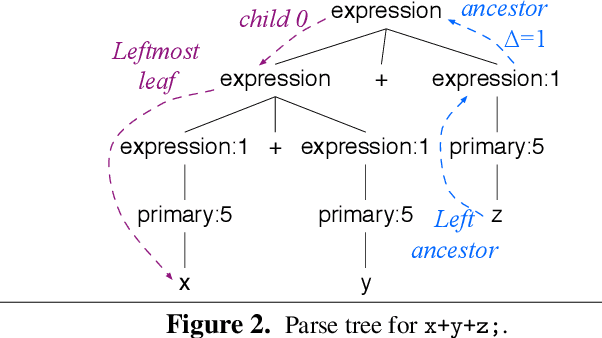
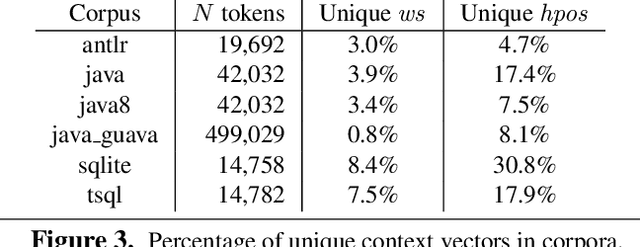
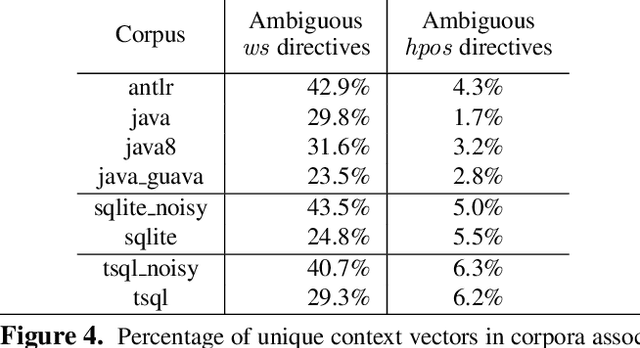
There are many declarative frameworks that allow us to implement code formatters relatively easily for any specific language, but constructing them is cumbersome. The first problem is that "everybody" wants to format their code differently, leading to either many formatter variants or a ridiculous number of configuration options. Second, the size of each implementation scales with a language's grammar size, leading to hundreds of rules. In this paper, we solve the formatter construction problem using a novel approach, one that automatically derives formatters for any given language without intervention from a language expert. We introduce a code formatter called CodeBuff that uses machine learning to abstract formatting rules from a representative corpus, using a carefully designed feature set. Our experiments on Java, SQL, and ANTLR grammars show that CodeBuff is efficient, has excellent accuracy, and is grammar invariant for a given language. It also generalizes to a 4th language tested during manuscript preparation.