 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
fastai: A Layered API for Deep Learning
Feb 16, 2020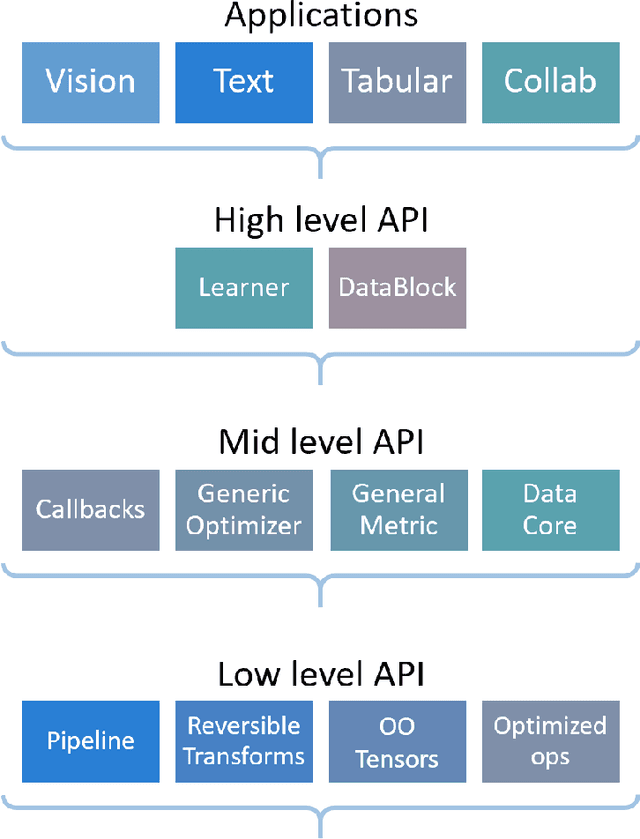



fastai is a deep learning library which provides practitioners with high-level components that can quickly and easily provide state-of-the-art results in standard deep learning domains, and provides researchers with low-level components that can be mixed and matched to build new approaches. It aims to do both things without substantial compromises in ease of use, flexibility, or performance. This is possible thanks to a carefully layered architecture, which expresses common underlying patterns of many deep learning and data processing techniques in terms of decoupled abstractions. These abstractions can be expressed concisely and clearly by leveraging the dynamism of the underlying Python language and the flexibility of the PyTorch library. fastai includes: a new type dispatch system for Python along with a semantic type hierarchy for tensors; a GPU-optimized computer vision library which can be extended in pure Python; an optimizer which refactors out the common functionality of modern optimizers into two basic pieces, allowing optimization algorithms to be implemented in 4-5 lines of code; a novel 2-way callback system that can access any part of the data, model, or optimizer and change it at any point during training; a new data block API; and much more. We have used this library to successfully create a complete deep learning course, which we were able to write more quickly than using previous approaches, and the code was more clear. The library is already in wide use in research, industry, and teaching. NB: This paper covers fastai v2, which is currently in pre-release at http://dev.fast.ai/
MultiFiT: Efficient Multi-lingual Language Model Fine-tuning
Sep 10, 2019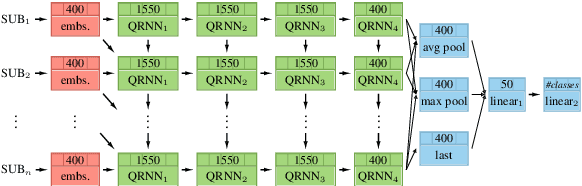
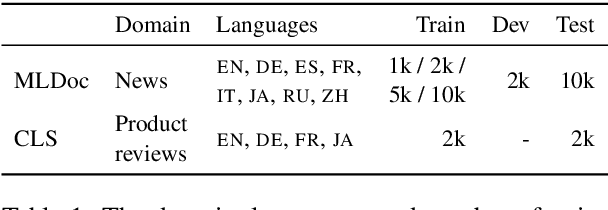
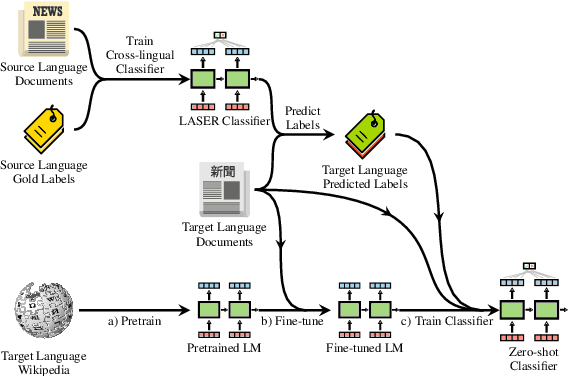
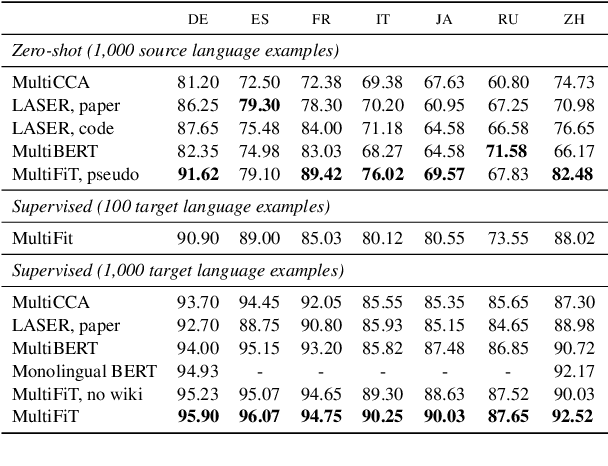
Pretrained language models are promising particularly for low-resource languages as they only require unlabelled data. However, training existing models requires huge amounts of compute, while pretrained cross-lingual models often underperform on low-resource languages. We propose Multi-lingual language model Fine-Tuning (MultiFiT) to enable practitioners to train and fine-tune language models efficiently in their own language. In addition, we propose a zero-shot method using an existing pretrained cross-lingual model. We evaluate our methods on two widely used cross-lingual classification datasets where they outperform models pretrained on orders of magnitude more data and compute. We release all models and code.
Applying a Pre-trained Language Model to Spanish Twitter Humor Prediction
Jul 06, 2019
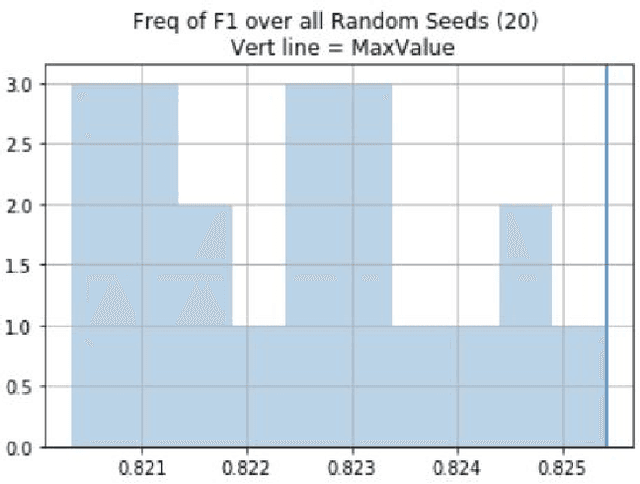

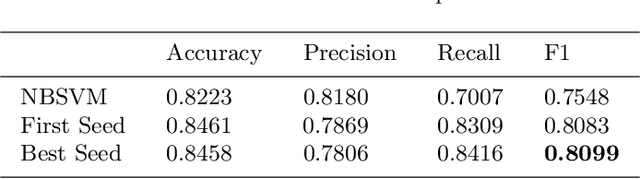
Our entry into the HAHA 2019 Challenge placed $3^{rd}$ in the classification task and $2^{nd}$ in the regression task. We describe our system and innovations, as well as comparing our results to a Naive Bayes baseline. A large Twitter based corpus allowed us to train a language model from scratch focused on Spanish and transfer that knowledge to our competition model. To overcome the inherent errors in some labels we reduce our class confidence with label smoothing in the loss function. All the code for our project is included in a GitHub repository for easy reference and to enable replication by others.
Universal Language Model Fine-Tuning with Subword Tokenization for Polish
Oct 24, 2018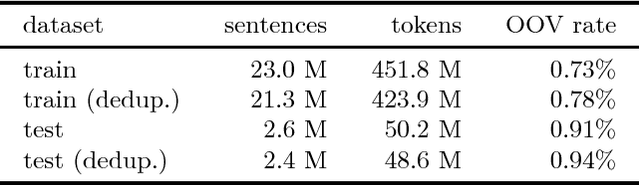
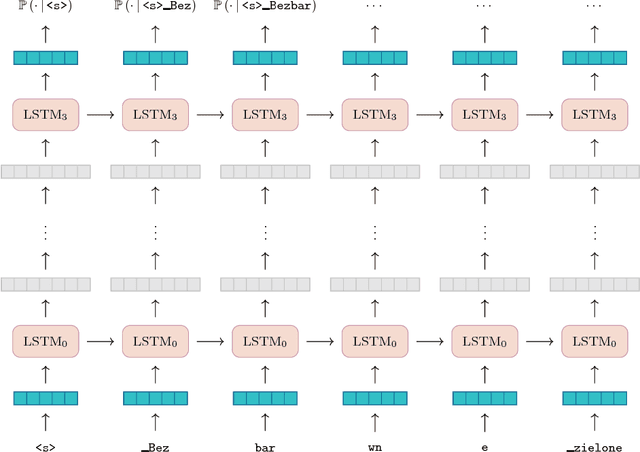

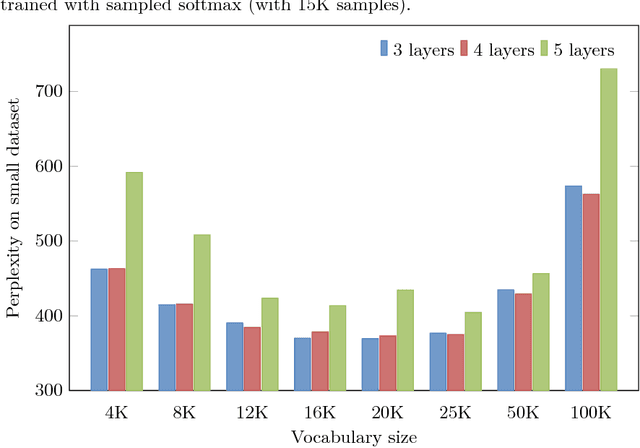
Universal Language Model for Fine-tuning [arXiv:1801.06146] (ULMFiT) is one of the first NLP methods for efficient inductive transfer learning. Unsupervised pretraining results in improvements on many NLP tasks for English. In this paper, we describe a new method that uses subword tokenization to adapt ULMFiT to languages with high inflection. Our approach results in a new state-of-the-art for the Polish language, taking first place in Task 3 of PolEval'18. After further training, our final model outperformed the second best model by 35%. We have open-sourced our pretrained models and code.
The Matrix Calculus You Need For Deep Learning
Jul 02, 2018This paper is an attempt to explain all the matrix calculus you need in order to understand the training of deep neural networks. We assume no math knowledge beyond what you learned in calculus 1, and provide links to help you refresh the necessary math where needed. Note that you do not need to understand this material before you start learning to train and use deep learning in practice; rather, this material is for those who are already familiar with the basics of neural networks, and wish to deepen their understanding of the underlying math. Don't worry if you get stuck at some point along the way---just go back and reread the previous section, and try writing down and working through some examples. And if you're still stuck, we're happy to answer your questions in the Theory category at forums.fast.ai. Note: There is a reference section at the end of the paper summarizing all the key matrix calculus rules and terminology discussed here. See related articles at http://explained.ai
Universal Language Model Fine-tuning for Text Classification
May 23, 2018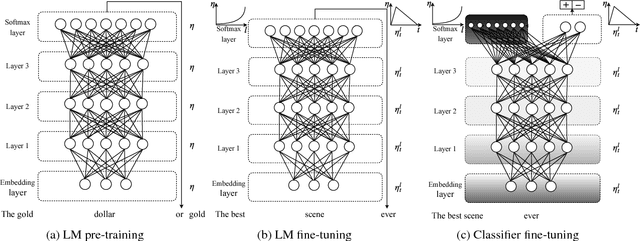
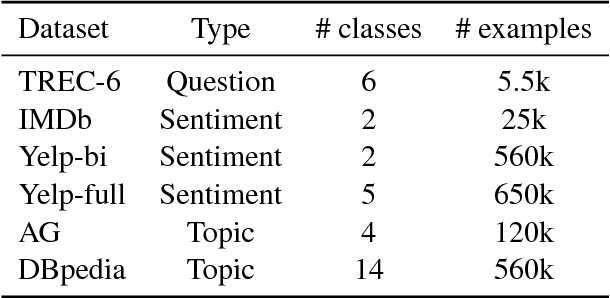
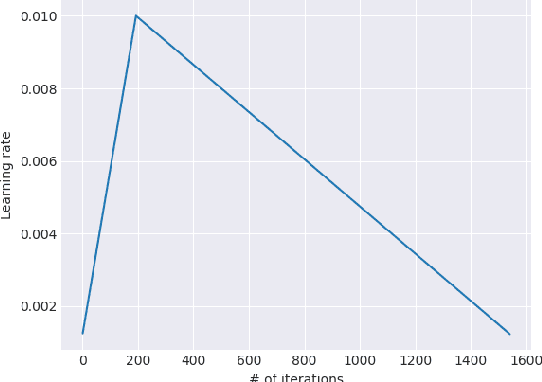
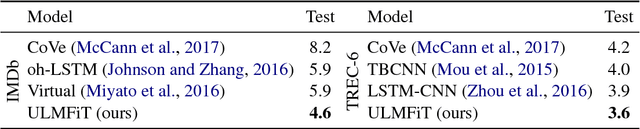
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data. We open-source our pretrained models and code.