 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxCell: Automatic Extraction of Results from Machine Learning Papers
Apr 29, 2020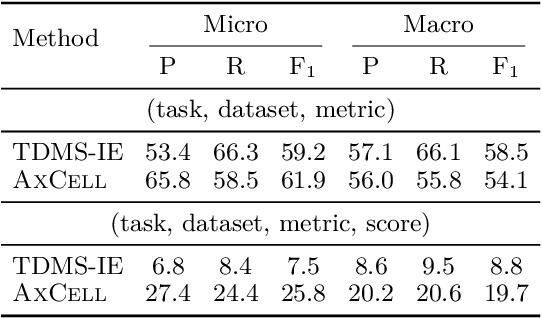
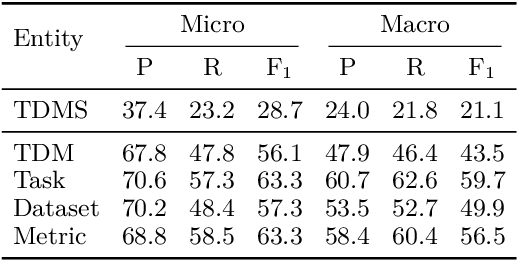

Tracking progress in machine learning has become increasingly difficult with the recent explosion in the number of papers. In this paper, we present AxCell, an automatic machine learning pipeline for extracting results from papers. AxCell uses several novel components, including a table segmentation subtask, to learn relevant structural knowledge that aids extraction. When compared with existing methods, our approach significantly improves the state of the art for results extraction. We also release a structured, annotated dataset for training models for results extraction, and a dataset for evaluating the performance of models on this task. Lastly, we show the viability of our approach enables it to be used for semi-automated results extraction in production, suggesting our improvements make this task practically viable for the first time. Code is available on GitHub.
MultiFiT: Efficient Multi-lingual Language Model Fine-tuning
Sep 10, 2019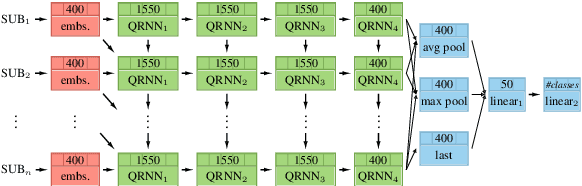
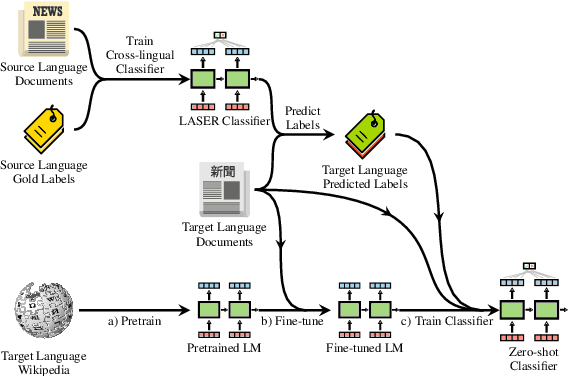
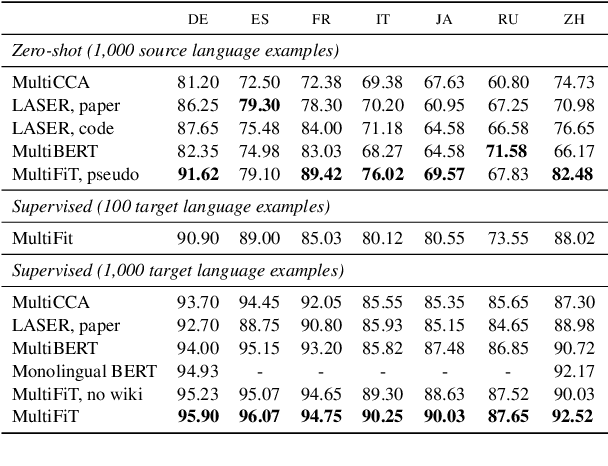
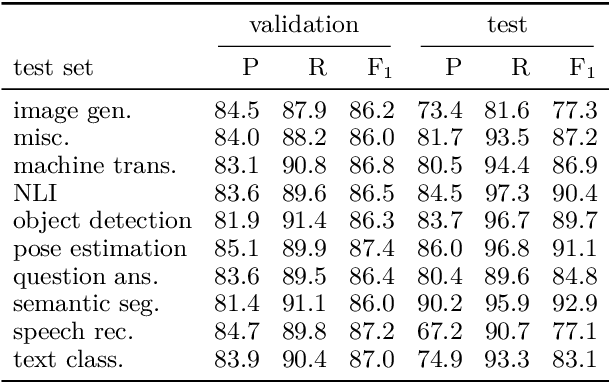
Pretrained language models are promising particularly for low-resource languages as they only require unlabelled data. However, training existing models requires huge amounts of compute, while pretrained cross-lingual models often underperform on low-resource languages. We propose Multi-lingual language model Fine-Tuning (MultiFiT) to enable practitioners to train and fine-tune language models efficiently in their own language. In addition, we propose a zero-shot method using an existing pretrained cross-lingual model. We evaluate our methods on two widely used cross-lingual classification datasets where they outperform models pretrained on orders of magnitude more data and compute. We release all models and code.
Applying a Pre-trained Language Model to Spanish Twitter Humor Prediction
Jul 06, 2019

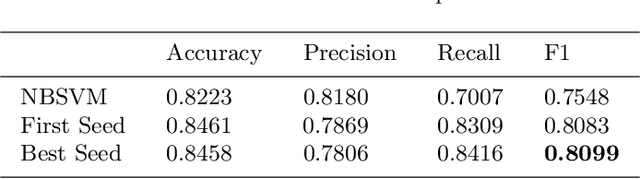
Our entry into the HAHA 2019 Challenge placed $3^{rd}$ in the classification task and $2^{nd}$ in the regression task. We describe our system and innovations, as well as comparing our results to a Naive Bayes baseline. A large Twitter based corpus allowed us to train a language model from scratch focused on Spanish and transfer that knowledge to our competition model. To overcome the inherent errors in some labels we reduce our class confidence with label smoothing in the loss function. All the code for our project is included in a GitHub repository for easy reference and to enable replication by others.
Universal Language Model Fine-Tuning with Subword Tokenization for Polish
Oct 24, 2018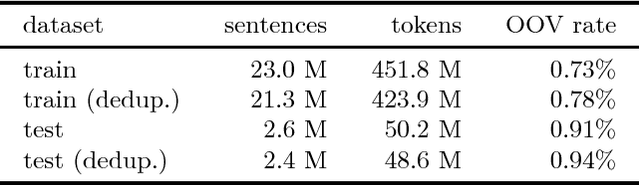
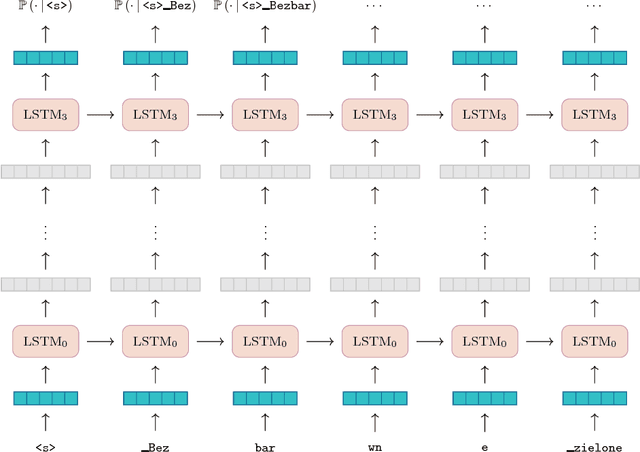

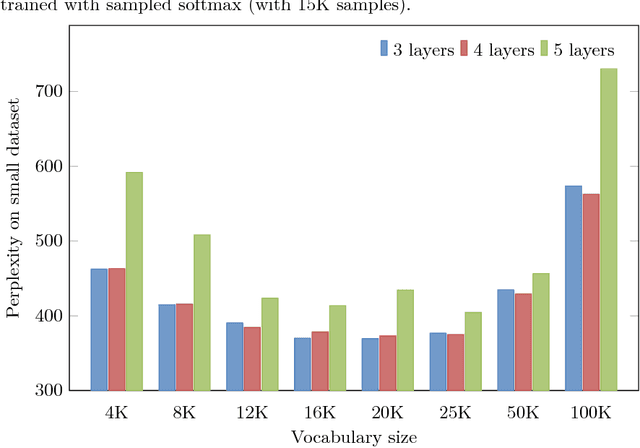
Universal Language Model for Fine-tuning [arXiv:1801.06146] (ULMFiT) is one of the first NLP methods for efficient inductive transfer learning. Unsupervised pretraining results in improvements on many NLP tasks for English. In this paper, we describe a new method that uses subword tokenization to adapt ULMFiT to languages with high inflection. Our approach results in a new state-of-the-art for the Polish language, taking first place in Task 3 of PolEval'18. After further training, our final model outperformed the second best model by 35%. We have open-sourced our pretrained models and code.