Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying a Pre-trained Language Model to Spanish Twitter Humor Prediction
Jul 06, 2019
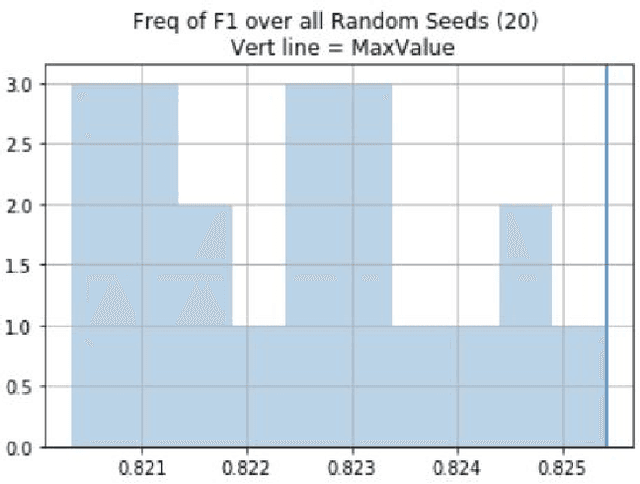

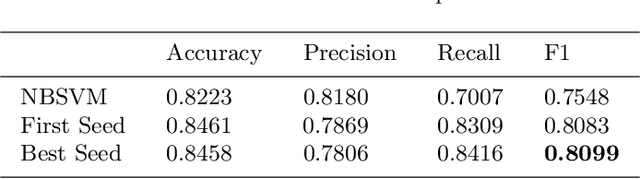
Our entry into the HAHA 2019 Challenge placed $3^{rd}$ in the classification task and $2^{nd}$ in the regression task. We describe our system and innovations, as well as comparing our results to a Naive Bayes baseline. A large Twitter based corpus allowed us to train a language model from scratch focused on Spanish and transfer that knowledge to our competition model. To overcome the inherent errors in some labels we reduce our class confidence with label smoothing in the loss function. All the code for our project is included in a GitHub repository for easy reference and to enable replication by others.
* IberLEF 2019 Workshop
Via