 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxCell: Automatic Extraction of Results from Machine Learning Papers
Paper and Code
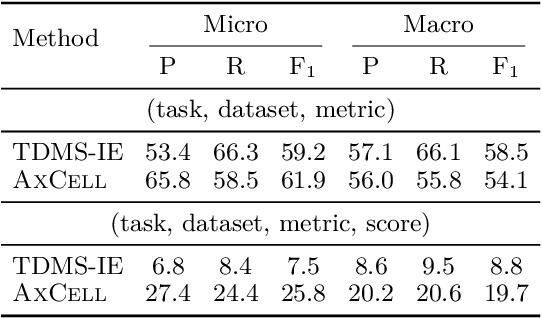
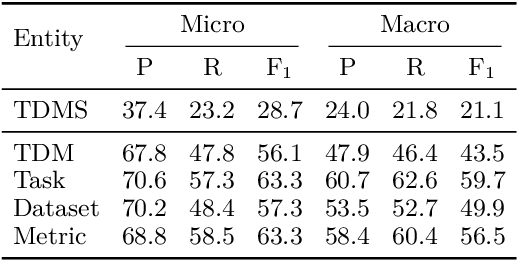
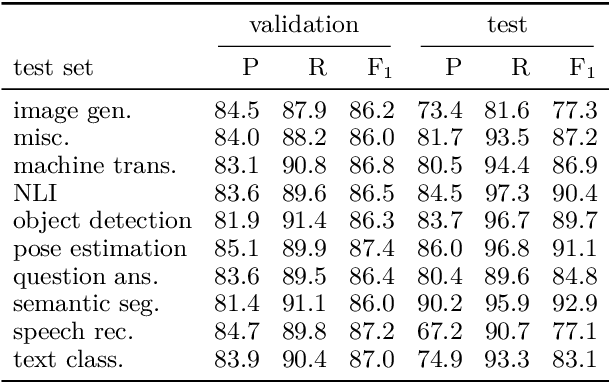

Tracking progress in machine learning has become increasingly difficult with the recent explosion in the number of papers. In this paper, we present AxCell, an automatic machine learning pipeline for extracting results from papers. AxCell uses several novel components, including a table segmentation subtask, to learn relevant structural knowledge that aids extraction. When compared with existing methods, our approach significantly improves the state of the art for results extraction. We also release a structured, annotated dataset for training models for results extraction, and a dataset for evaluating the performance of models on this task. Lastly, we show the viability of our approach enables it to be used for semi-automated results extraction in production, suggesting our improvements make this task practically viable for the first time. Code is available on GitHub.