 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-SEAD: State Estimation Anomaly Dataset for UAVs
Feb 14, 2026Accurate state estimation in Unmanned Aerial Vehicles (UAVs) is crucial for ensuring reliable and safe operation, as anomalies occurring during mission execution may induce discrepancies between expected and observed system behaviors, thereby compromising mission success or posing potential safety hazards. It is essential to continuously monitor and detect such conditions in order to ensure a timely response and maintain system reliability. In this work, we focus on UAV state estimation anomalies and provide a large-scale real-world UAV dataset to facilitate research aimed at improving the development of anomaly detection. Unlike existing datasets that primarily rely on injected faults into simulated data, this dataset comprises 1396 real flight logs totaling over 52 hours of flight time, collected across diverse indoor and outdoor environments using a collection of PX4-based UAVs equipped with a variety of sensor configurations. The dataset comprises both normal and anomalous flights without synthetic manipulation, making it uniquely suitable for realistic anomaly detection tasks. A structured classification is proposed that categorizes UAV state estimation anomalies into four classes: mechanical and electrical, external position, global position, and altitude anomalies. These classifications reflect collective, contextual, and outlier anomalies observed in multivariate sensor data streams, including IMU, GPS, barometer, magnetometer, distance sensors, visual odometry, and optical flow, that can be found in the PX4 logging mechanism. It is anticipated that this dataset will play a key role in the development, training, and evaluation of anomaly detection and isolation systems to address the critical gap in UAV reliability research.
Real-Time Manipulation Action Recognition with a Factorized Graph Sequence Encoder
Mar 15, 2025
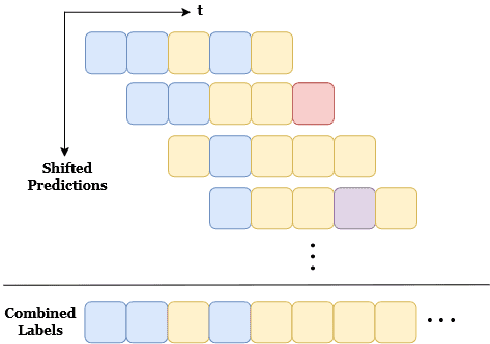
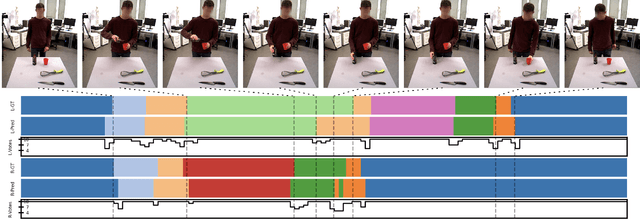

Recognition of human manipulation actions in real-time is essential for safe and effective human-robot interaction and collaboration. The challenge lies in developing a model that is both lightweight enough for real-time execution and capable of generalization. While some existing methods in the literature can run in real-time, they struggle with temporal scalability, i.e., they fail to adapt to long-duration manipulations effectively. To address this, leveraging the generalizable scene graph representations, we propose a new Factorized Graph Sequence Encoder network that not only runs in real-time but also scales effectively in the temporal dimension, thanks to its factorized encoder architecture. Additionally, we introduce Hand Pooling operation, a simple pooling operation for more focused extraction of the graph-level embeddings. Our model outperforms the previous state-of-the-art real-time approach, achieving a 14.3\% and 5.6\% improvement in F1-macro score on the KIT Bimanual Action (Bimacs) Dataset and Collaborative Action (CoAx) Dataset, respectively. Moreover, we conduct an extensive ablation study to validate our network design choices. Finally, we compare our model with its architecturally similar RGB-based model on the Bimacs dataset and show the limitations of this model in contrast to ours on such an object-centric manipulation dataset.
Multimodal Detection and Identification of Robot Manipulation Failures
May 08, 2023


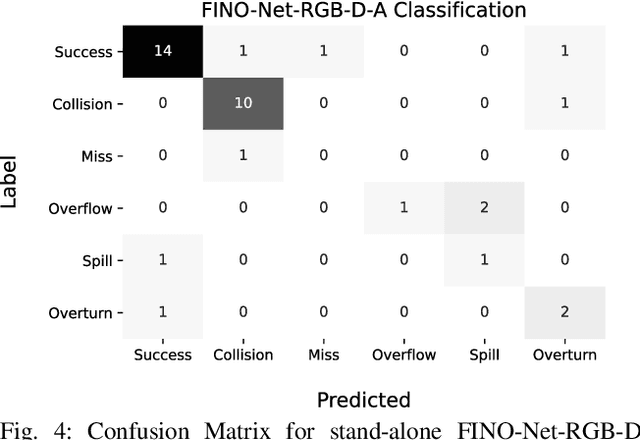
An autonomous service robot should be able to interact with its environment safely and robustly without requiring human assistance. Unstructured environments are challenging for robots since the exact prediction of outcomes is not always possible. Even when the robot behaviors are well-designed, the unpredictable nature of physical robot-object interaction may prevent success in object manipulation. Therefore, execution of a manipulation action may result in an undesirable outcome involving accidents or damages to the objects or environment. Situation awareness becomes important in such cases to enable the robot to (i) maintain the integrity of both itself and the environment, (ii) recover from failed tasks in the short term, and (iii) learn to avoid failures in the long term. For this purpose, robot executions should be continuously monitored, and failures should be detected and classified appropriately. In this work, we focus on detecting and classifying both manipulation and post-manipulation phase failures using the same exteroception setup. We cover a diverse set of failure types for primary tabletop manipulation actions. In order to detect these failures, we propose FINO-Net [1], a deep multimodal sensor fusion based classifier network. Proposed network accurately detects and classifies failures from raw sensory data without any prior knowledge. In this work, we use our extended FAILURE dataset [1] with 99 new multimodal manipulation recordings and annotate them with their corresponding failure types. FINO-Net achieves 0.87 failure detection and 0.80 failure classification F1 scores. Experimental results show that proposed architecture is also appropriate for real-time use.
Learning Failure Prevention Skills for Safe Robot Manipulation
May 04, 2023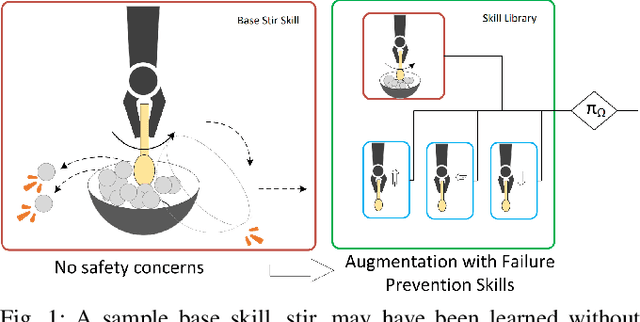


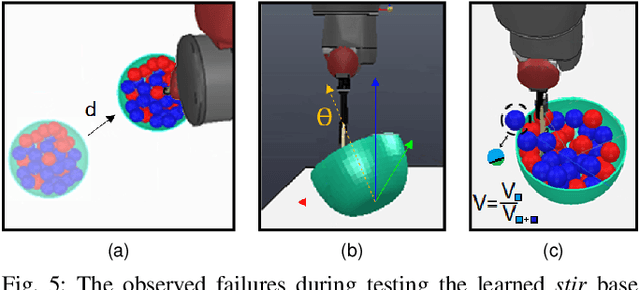
Robots are more capable of achieving manipulation tasks for everyday activities than before. But the safety of manipulation skills that robots employ is still an open problem. Considering all possible failures during skill learning increases the complexity of the process and restrains learning an optimal policy. Beyond that, in unstructured environments, it is not easy to enumerate all possible failures beforehand. In the context of safe skill manipulation, we reformulate skills as base and failure prevention skills where base skills aim at completing tasks and failure prevention skills focus on reducing the risk of failures to occur. Then, we propose a modular and hierarchical method for safe robot manipulation by augmenting base skills by learning failure prevention skills with reinforcement learning, forming a skill library to address different safety risks. Furthermore, a skill selection policy that considers estimated risks is used for the robot to select the best control policy for safe manipulation. Our experiments show that the proposed method achieves the given goal while ensuring safety by preventing failures. We also show that with the proposed method, skill learning is feasible, novel failures are easily adaptable, and our safe manipulation tools can be transferred to the real environment.
CLUE-AI: A Convolutional Three-stream Anomaly Identification Framework for Robot Manipulation
Mar 16, 2022
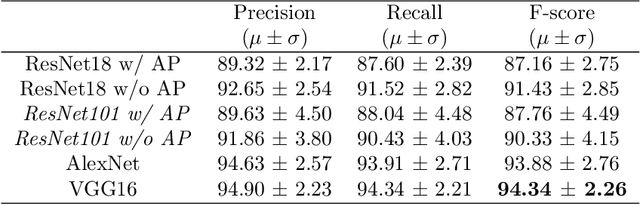

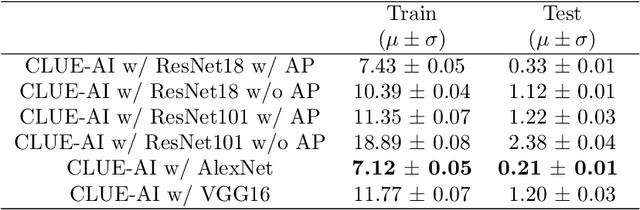
Robot safety has been a prominent research topic in recent years since robots are more involved in daily tasks. It is crucial to devise the required safety mechanisms to enable service robots to be aware of and react to anomalies (i.e., unexpected deviations from intended outcomes) that arise during the execution of these tasks. Detection and identification of these anomalies is an essential step towards fulfilling these requirements. Although several architectures are proposed for anomaly detection, identification is not yet thoroughly investigated. This task is challenging since indicators may appear long before anomalies are detected. In this paper, we propose a ConvoLUtional threE-stream Anomaly Identification (CLUE-AI) framework to address this problem. The framework fuses visual, auditory and proprioceptive data streams to identify everyday object manipulation anomalies. A stream of 2D images gathered through an RGB-D camera placed on the head of the robot is processed within a self-attention enabled visual stage to capture visual anomaly indicators. The auditory modality provided by the microphone placed on the robot's lower torso is processed within a designed convolutional neural network (CNN) in the auditory stage. Last, the force applied by the gripper and the gripper state are processed within a CNN to obtain proprioceptive features. These outputs are then combined with a late fusion scheme. Our novel three-stream framework design is analyzed on everyday object manipulation tasks with a Baxter humanoid robot in a semi-structured setting. The results indicate that the framework achieves an f-score of 94% outperforming the other baselines in classifying anomalies that arise during runtime.
A Variational Graph Autoencoder for Manipulation Action Recognition and Prediction
Oct 25, 2021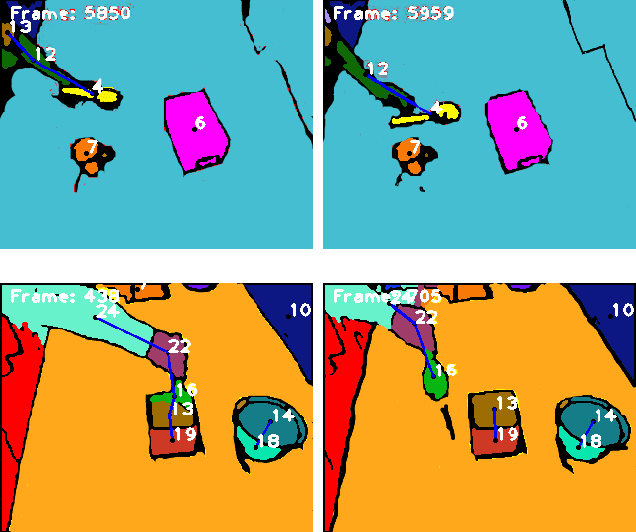
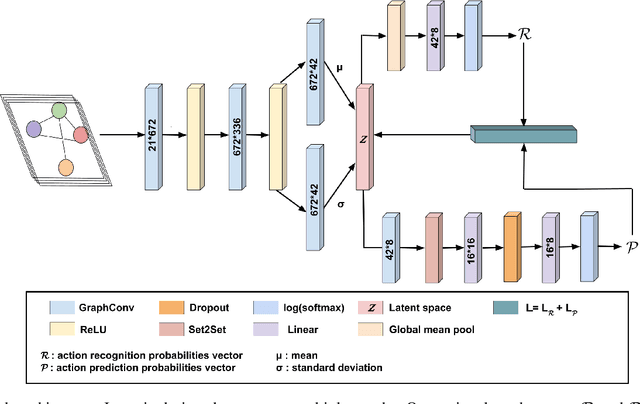

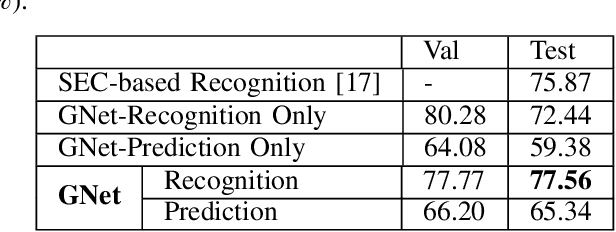
Despite decades of research, understanding human manipulation activities is, and has always been, one of the most attractive and challenging research topics in computer vision and robotics. Recognition and prediction of observed human manipulation actions have their roots in the applications related to, for instance, human-robot interaction and robot learning from demonstration. The current research trend heavily relies on advanced convolutional neural networks to process the structured Euclidean data, such as RGB camera images. These networks, however, come with immense computational complexity to be able to process high dimensional raw data. Different from the related works, we here introduce a deep graph autoencoder to jointly learn recognition and prediction of manipulation tasks from symbolic scene graphs, instead of relying on the structured Euclidean data. Our network has a variational autoencoder structure with two branches: one for identifying the input graph type and one for predicting the future graphs. The input of the proposed network is a set of semantic graphs which store the spatial relations between subjects and objects in the scene. The network output is a label set representing the detected and predicted class types. We benchmark our new model against different state-of-the-art methods on two different datasets, MANIAC and MSRC-9, and show that our proposed model can achieve better performance. We also release our source code https://github.com/gamzeakyol/GNet.
Two-stage training algorithm for AI robot soccer
Apr 13, 2021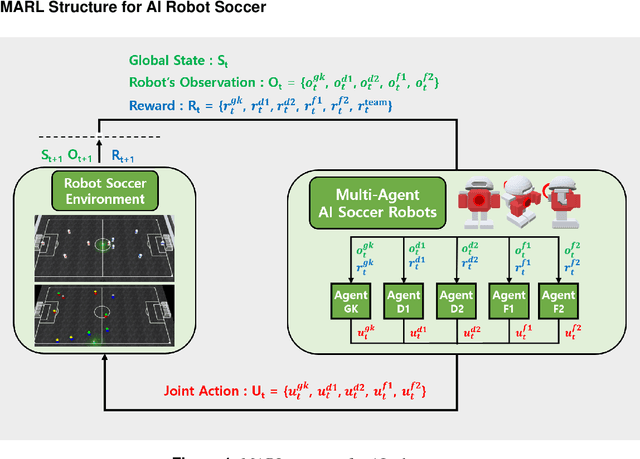
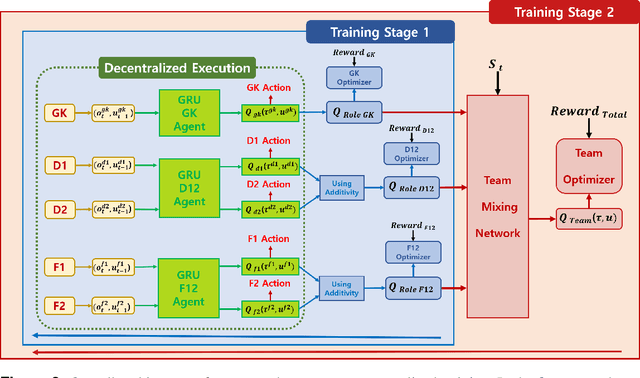
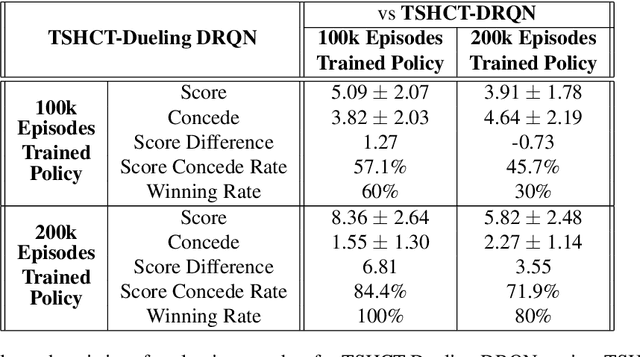
In multi-agent reinforcement learning, the cooperative learning behavior of agents is very important. In the field of heterogeneous multi-agent reinforcement learning, cooperative behavior among different types of agents in a group is pursued. Learning a joint-action set during centralized training is an attractive way to obtain such cooperative behavior, however, this method brings limited learning performance with heterogeneous agents. To improve the learning performance of heterogeneous agents during centralized training, two-stage heterogeneous centralized training which allows the training of multiple roles of heterogeneous agents is proposed. During training, two training processes are conducted in a series. One of the two stages is to attempt training each agent according to its role, aiming at the maximization of individual role rewards. The other is for training the agents as a whole to make them learn cooperative behaviors while attempting to maximize shared collective rewards, e.g., team rewards. Because these two training processes are conducted in a series in every timestep, agents can learn how to maximize role rewards and team rewards simultaneously. The proposed method is applied to 5 versus 5 AI robot soccer for validation. Simulation results show that the proposed method can train the robots of the robot soccer team effectively, achieving higher role rewards and higher team rewards as compared to other approaches that can be used to solve problems of training cooperative multi-agent.
FINO-Net: A Deep Multimodal Sensor Fusion Framework for Manipulation Failure Detection
Nov 11, 2020



Safe manipulation in unstructured environments for service robots is a challenging problem. A failure detection system is needed to monitor and detect unintended outcomes. We propose FINO-Net, a novel multimodal sensor fusion based deep neural network to detect and identify manipulation failures. We also introduce a multimodal dataset, containing 229 real-world manipulation data recorded with a Baxter robot. Our network combines RGB, depth and audio readings to effectively detect and classify failures. Results indicate that fusing RGB with depth and audio modalities significantly improves the performance. FINO-Net achieves 98.60% detection and 87.31% classification accuracy on our novel dataset. Code and data are publicly available at https://github.com/ardai/fino-net.
What went wrong?: Identification of Everyday Object Manipulation Anomalies
Jan 24, 2020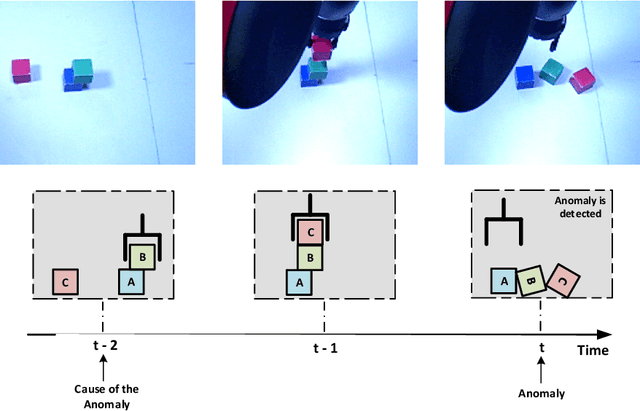
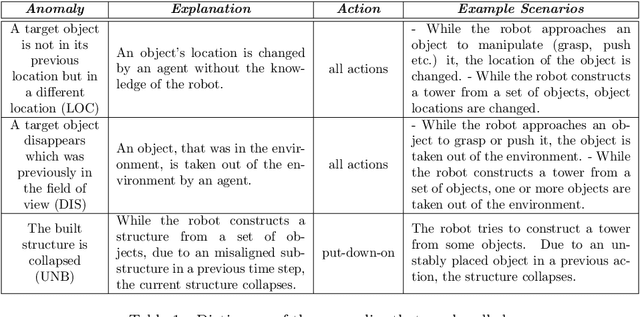

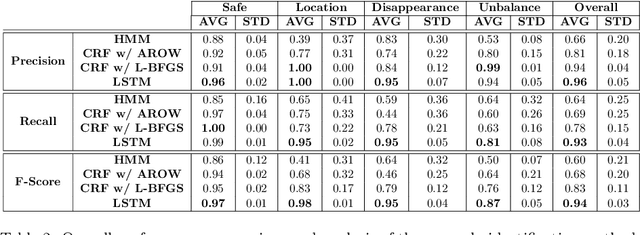
Extending the abilities of service robots is important for expanding what they can achieve in everyday manipulation tasks. On the other hand, it is also essential to ensure them to determine what they can not achieve in certain cases due to either anomalies or permanent failures during task execution. Robots need to identify these situations, and reveal the reasons behind these cases to overcome and recover from them. In this paper, we propose and analyze a Long Short-Term Memories-based (LSTM-based) awareness approach to reveal the reasons behind an anomaly case that occurs during a manipulation episode in an unstructured environment. The proposed method takes into account the real-time observations of the robot by fusing visual, auditory and proprioceptive sensory modalities to achieve this task. We also provide a comparative analysis of our method with Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs). The symptoms of anomalies are first learned from a given training set, then they can be classified in real-time based on the learned models. The approaches are evaluated on a Baxter robot executing object manipulation scenarios. The results indicate that the LSTM-based method outperforms the other methods with a 0.94 classification rate in revealing causes of anomalies in case of an unexpected deviation.